Clear Sky Science · es
Marco computacional para predecir y moldear las interacciones humano–máquina en interfaces neuronales coadaptativas en bucle cerrado
Enseñar a las máquinas a aprender con nosotros
A medida que las interfaces cerebro–computadora y las prótesis avanzadas pasan del laboratorio a la vida cotidiana, surge una pregunta central: ¿cómo diseñar dispositivos que aprendan de nosotros al mismo tiempo que nosotros aprendemos a usarlos? Este estudio aborda ese desafío construyendo un marco matemático y experimental para interfaces neuronales “coadaptativas”: sistemas en los que tanto el usuario humano como el algoritmo de decodificación se ajustan continuamente entre sí para que el control resulte más fluido, natural y fiable con el tiempo. 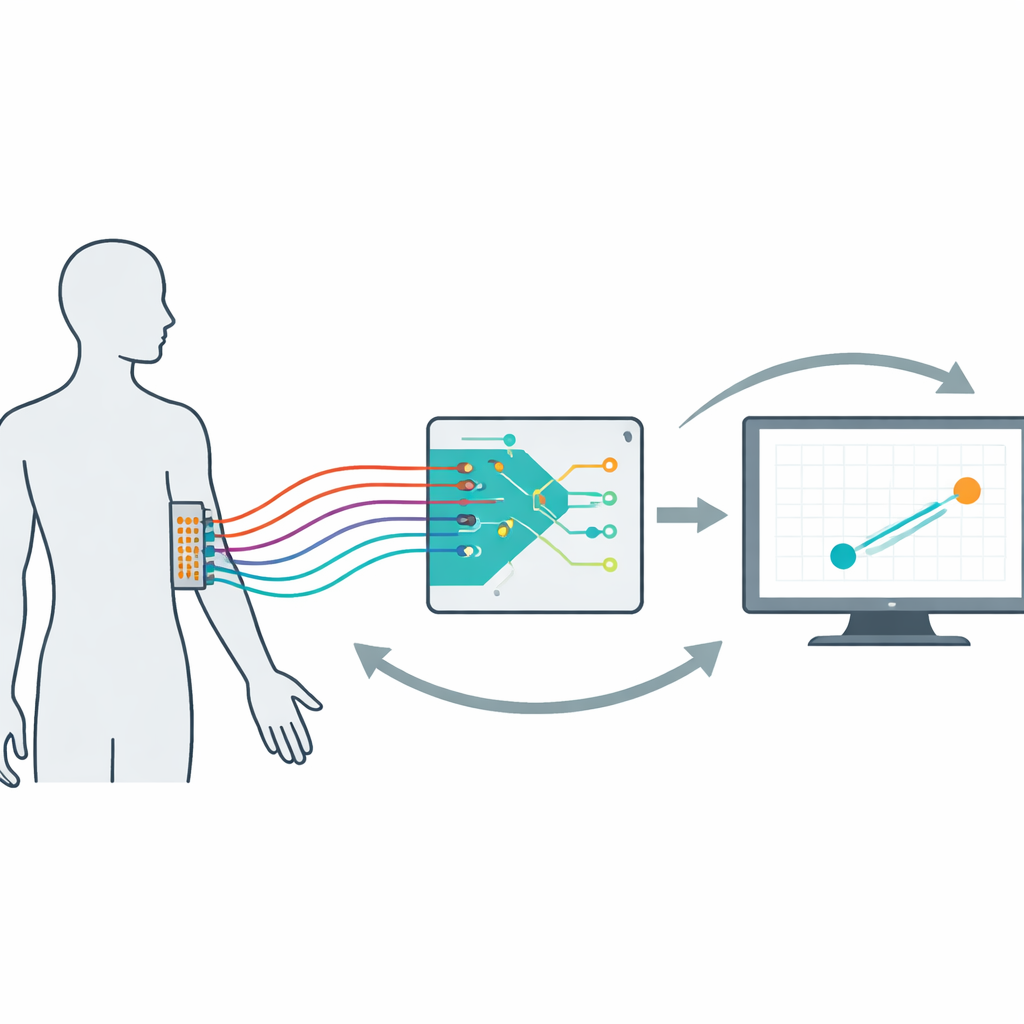
Un nuevo tipo de asociación humano–máquina
Muchas interfaces neuronales funcionan traduciendo señales biológicas de alta dimensión, como la actividad muscular o cerebral, en comandos simples que pueden mover un cursor o una extremidad robótica. Tradicionalmente, los diseñadores han intentado optimizar ya sea el lado humano (entrenando al usuario para que se adapte a un decodificador fijo) o el lado máquina (dejando que el decodificador se actualice mientras se asume un usuario mayormente fijo). En la realidad, ambos lados están aprendiendo constantemente. Esta configuración de dos aprendices puede desbloquear mejor rendimiento y personalización, pero también es más difícil de diseñar: si el algoritmo se adapta demasiado rápido o de forma inadecuada, puede confundir al usuario en lugar de ayudarle. Los autores combinan herramientas de teoría del control y teoría de juegos para describir, predecir y, en última instancia, modelar estos procesos de aprendizaje entrelazados.
Construir un banco de pruebas seguro para interfaces coadaptativas
Para estudiar estas dinámicas de manera controlada, los investigadores crearon una interfaz mioeléctrica no invasiva. Catorce voluntarios llevaron una rejilla de 64 electrodos en el antebrazo dominante. Su actividad muscular movía un cursor informático que debía seguir un objetivo errante en la pantalla. A nivel interno, un decodificador convertía las señales musculares en velocidad del cursor y se actualizaba cada 20 segundos según el rendimiento reciente. A lo largo de 16 ensayos de cinco minutos por persona, el equipo varió sistemáticamente la velocidad de aprendizaje del decodificador, cuán fuertemente se penalizaba el uso de ganancias de señal grandes (su “esfuerzo”) y cómo se inicializaba. Al examinar tanto el comportamiento como los patrones musculares, confirmaron que los usuarios no se limitaban a esperar a que el algoritmo mejorara; cambiaban activamente la forma en que usaban sus músculos dentro y entre ensayos, creando un bucle humano–máquina verdaderamente coadaptativo.
Usar teoría del control para ver dentro del bucle
El siguiente paso fue convertir esta interacción compleja en un modelo que se pudiera medir y probar. Con ideas de la teoría del control, los autores estimaron una descripción matemática compacta de la estrategia de cada usuario: un “codificador” que mapea la información del objetivo y del cursor a patrones de actividad muscular. Este codificador se pudo separar en una parte predictiva, feedforward, y una parte correctiva, de retroalimentación. Al combinar el codificador estimado con el decodificador conocido, el equipo pudo evaluar si todo el sistema iba camino de un control preciso y estable. Encontraron que, con el tiempo, la pareja usuario–decodificador tendía a moverse hacia valores predichos que dan un buen seguimiento y estabilidad, aunque ni el usuario ni el decodificador dejaban de cambiar por completo. Los usuarios también mostraron signos de aprendizaje a más largo plazo: sus mapeos musculares cambiaban menos de un ensayo a otro a medida que se volvieron más competentes. 
La teoría de juegos revela cómo las reglas de aprendizaje moldean el comportamiento
Para ir más allá de la descripción y predecir realmente cómo las decisiones de diseño afectarían la coadaptación, los autores recurrieron a la teoría de juegos, que estudia cómo interactúan varios agentes cuando cada uno intenta minimizar su propio coste. Modelaron al usuario y al decodificador como dos “jugadores” que ambos se preocupan por reducir el error de seguimiento, pero que también pagan un precio por el esfuerzo: activación muscular para el usuario y ganancias grandes para el decodificador. En este marco, el sistema conjunto puede estabilizarse en uno de varios estados estables, o puntos estacionarios, según las velocidades de aprendizaje, las penalizaciones por esfuerzo y las condiciones iniciales. El modelo hizo predicciones concretas: la tasa de aprendizaje del decodificador debería afectar fuertemente la rapidez y la calidad de la convergencia; ajustar la penalización de esfuerzo del decodificador debería desplazar cuánto esfuerzo debe invertir el usuario sin cambiar necesariamente la precisión; y la configuración inicial del decodificador podría sesgar sutilmente la estrategia final del usuario.
Probar cómo los algoritmos guían el aprendizaje humano
Los experimentos confirmaron en gran medida estas predicciones. Cuando el decodificador aprendía lentamente, los usuarios mejoraban más dentro de un ensayo, y la pareja codificador–decodificador se acercaba más al régimen teóricamente ideal para un control del cursor preciso y estable. Cuando el decodificador se adaptaba demasiado rápido, el rendimiento empeoraba y los usuarios cambiaban menos sus estrategias musculares, lo que sugiere que la máquina se movía más rápido de lo que las personas podían seguir. Cambiar la penalización por esfuerzo del decodificador ofreció otra palanca: penalizaciones más altas empujaban al decodificador a esforzarse menos, lo que a su vez llevó a muchos usuarios a aumentar su propio esfuerzo muscular para mantener la precisión. Es interesante que los participantes diferían en cómo equilibraban esfuerzo y velocidad del cursor: algunos optaban por trabajar más para mantener el cursor rápido, mientras otros aceptaban un movimiento más lento para ahorrar esfuerzo, lo que apunta a preferencias individuales que las futuras interfaces podrían personalizar.
Qué significa esto para las futuras interfaces neuronales
En términos sencillos, este trabajo muestra que las reglas de entrenamiento incorporadas en los algoritmos de interfaces neuronales hacen más que limpiar señales ruidosas; moldean activamente cómo las personas aprenden a usar el dispositivo. Al combinar modelado riguroso con experimentos humanos, los autores proporcionan un conjunto de herramientas para elegir de forma fundamentada las tasas de aprendizaje del decodificador, las penalizaciones por esfuerzo y las inicializaciones, en lugar de hacerlo por ensayo y error. Su marco podría guiar el diseño de prótesis de próxima generación, herramientas de rehabilitación e interfaces cerebro–computadora que no solo sean precisas, sino también estables, cómodas y adaptadas al estilo de aprendizaje de cada usuario.
Cita: Madduri, M.M., Yamagami, M., Li, S.J. et al. Computational framework to predict and shape human–machine interactions in closed-loop, co-adaptive neural interfaces. Nat Mach Intell 8, 372–387 (2026). https://doi.org/10.1038/s42256-026-01194-z
Palabras clave: interfaces neuronales, interacción humano máquina, control coadaptativo, control de cursor mioeléctrico, diseño de interfaces cerebro–computadora