Clear Sky Science · it
Quadro computazionale per prevedere e plasmare le interazioni uomo–macchina in interfacce neurali co-adattive e a ciclo chiuso
Insegnare alle macchine a imparare con noi
Con il passaggio delle interfacce cervello–computer e degli arti protesici avanzati dal laboratorio alla vita quotidiana, emerge una domanda centrale: come progettare dispositivi che imparino da noi mentre noi impariamo a usarli? Questo studio affronta la sfida costruendo un quadro matematico e sperimentale per interfacce neurali "co-adattive": sistemi in cui sia l'utente umano sia l'algoritmo di decodifica si aggiustano continuamente l'uno all'altro, così che il controllo risulti più fluido, naturale e affidabile nel tempo. 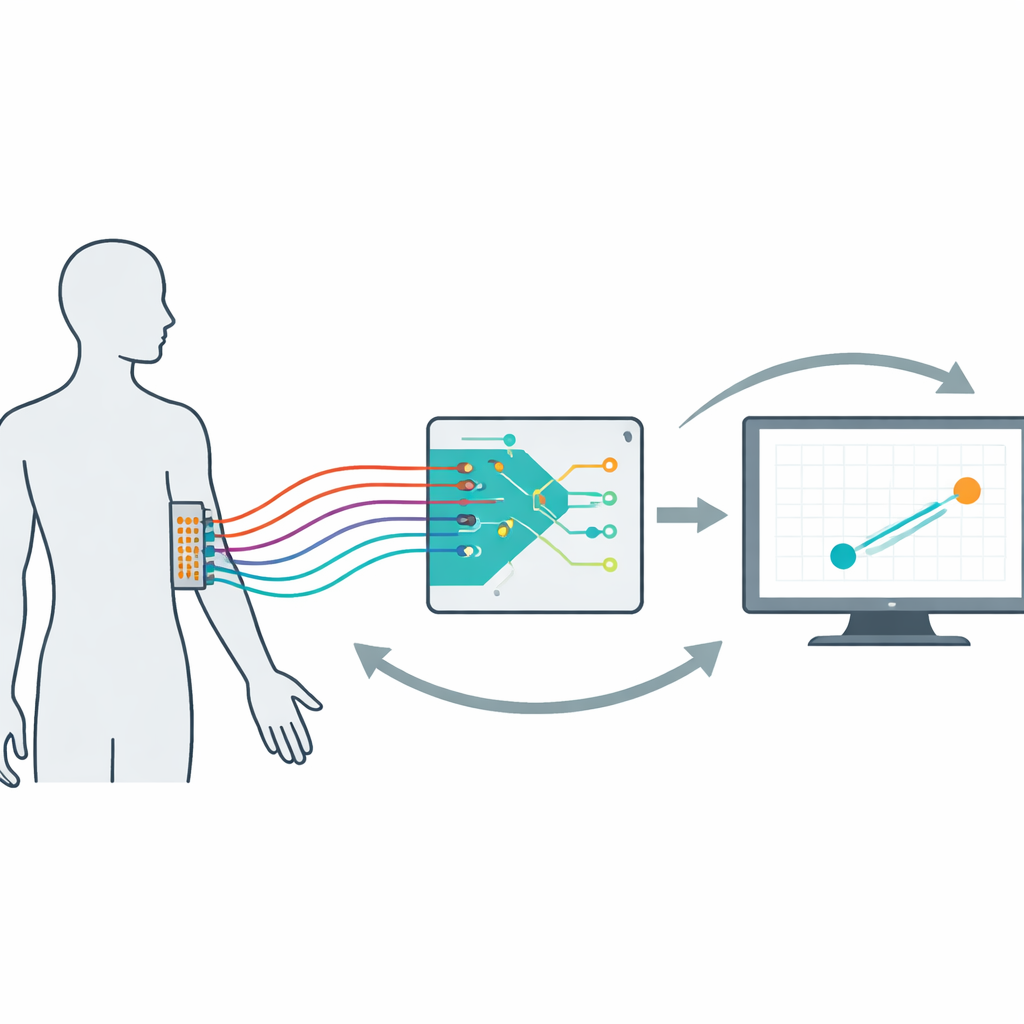
Una nuova forma di collaborazione uomo–macchina
Molte interfacce neurali traducono segnali biologici ad alta dimensionalità, come l'attività muscolare o cerebrale, in comandi semplici che muovono un cursore o un arto robotico. Tradizionalmente i progettisti cercavano di ottimizzare o il lato umano (addestrando l'utente ad adattarsi a un decodificatore fisso) o il lato macchina (lasciando che il decodificatore si aggiornasse assumendo un utente sostanzialmente fisso). In realtà, entrambi i lati imparano continuamente. Questa configurazione a due apprendenti può sbloccare migliori prestazioni e personalizzazione, ma è anche più difficile da progettare: se l'algoritmo si adatta troppo in fretta o in modo inappropriato, può confondere l'utente anziché aiutarlo. Gli autori combinano strumenti della teoria del controllo e della teoria dei giochi per descrivere, prevedere e infine modellare questi processi di apprendimento intrecciati.
Costruire un banco di prova sicuro per le interfacce co-adattive
Per studiare queste dinamiche in modo controllato, i ricercatori hanno creato un'interfaccia mioelettrica non invasiva. Quattordici volontari indossavano una griglia di 64 elettrodi sull'avambraccio dominante. La loro attività muscolare muoveva un cursore sullo schermo che doveva seguire un bersaglio in movimento. Nascosto al funzionamento, un decodificatore convertiva i segnali muscolari in velocità del cursore e si aggiornava ogni 20 secondi in base alle prestazioni recenti. In 16 prove da cinque minuti per partecipante, il team ha variato sistematicamente la velocità di apprendimento del decodificatore, quanto fosse penalizzato per usare guadagni del segnale elevati (il suo "sforzo") e come fosse inizializzato. Esaminando comportamento e pattern muscolari, hanno confermato che gli utenti non si limitavano ad aspettare che l'algoritmo migliorasse; modificavano attivamente l'uso dei propri muscoli entro e tra le prove, creando un autentico ciclo co-adattivo uomo–macchina.
Usare la teoria del controllo per vedere dentro il ciclo
Il passo successivo è stato trasformare questa interazione complessa in un modello misurabile e testabile. Usando idee della teoria del controllo, gli autori stimarono una descrizione matematica compatta della strategia di ciascun utente—un "codificatore" che mappa le informazioni su bersaglio e cursore in schemi di attività muscolare. Questo codificatore è separabile in una parte predittiva, feedforward, e in una parte correttiva, feedback. Combinando il codificatore stimato con il decodificatore noto, il team poteva valutare se l'intero sistema fosse sulla traiettoria per un controllo accurato e stabile. Hanno scoperto che, nel tempo, la coppia utente–decodificatore tendeva a muoversi verso valori previsti come favorevoli per un buon tracking e stabilità, anche se né l'utente né il decodificatore smettevano mai completamente di cambiare. Gli utenti mostrarono inoltre segni di apprendimento a lungo termine, con le loro mappature muscolari che cambiavano meno da una prova all'altra man mano che diventavano più abili. 
La teoria dei giochi rivela come le regole di apprendimento modellano il comportamento
Per andare oltre la descrizione e prevedere concretamente come le scelte di progettazione influenzassero il co-adattamento, gli autori si sono rivolti alla teoria dei giochi, che studia come più decisori interagiscono quando ciascuno cerca di minimizzare il proprio costo. Hanno modellato l'utente e il decodificatore come due "giocatori" che entrambi mirano a ridurre l'errore di tracking ma pagano anche un prezzo per lo sforzo—l'attivazione muscolare per l'utente e guadagni elevati per il decodificatore. In questo quadro, il sistema congiunto può stabilizzarsi in uno dei diversi stati stabili, o punti stazionari, a seconda dei tassi di apprendimento, delle penalità per lo sforzo e delle condizioni iniziali. Il modello forniva predizioni concrete: il tasso di apprendimento del decodificatore dovrebbe influire fortemente su quanto rapidamente e bene il sistema converge; regolare la penalità di sforzo del decodificatore dovrebbe spostare quanto sforzo l'utente deve investire senza necessariamente cambiare l'accuratezza; e le impostazioni iniziali del decodificatore potrebbero influenzare sottilmente la strategia finale dell'utente.
Testare come gli algoritmi guidano l'apprendimento umano
Gli esperimenti hanno in gran parte confermato queste previsioni. Quando il decodificatore imparava lentamente, gli utenti miglioravano di più all'interno di una prova e la coppia codificatore–decodificatore si avvicinava al regime teoricamente ideale per un controllo del cursore accurato e stabile. Quando il decodificatore si adattava troppo rapidamente, le prestazioni peggioravano e gli utenti modificavano meno le loro strategie muscolari, suggerendo che la macchina si muoveva più in fretta di quanto le persone potessero seguire. Modificare la penalità per lo sforzo del decodificatore offriva un altro controllo: penalità più alte spingevano il decodificatore a lavorare meno, il che a sua volta portava molti utenti ad aumentare il proprio sforzo muscolare per mantenere l'accuratezza. Interessante notare che i partecipanti differivano nel modo in cui bilanciavano sforzo e velocità del cursore—alcuni sceglievano di lavorare di più per mantenere il cursore veloce, altri accettavano movimenti più lenti per risparmiare sforzo—suggerendo preferenze individuali che future interfacce potrebbero personalizzare.
Cosa significa questo per le future interfacce neurali
In termini semplici, questo lavoro mostra che le regole di addestramento incorporate negli algoritmi delle interfacce neurali fanno più che ripulire segnali rumorosi; plasmano attivamente come le persone imparano a usare il dispositivo. Combinando una modellazione rigorosa con esperimenti sull'uomo, gli autori forniscono un kit di strumenti per scegliere in modo principled tassi di apprendimento del decodificatore, penalità per lo sforzo e inizializzazioni, invece di procedere per tentativi. Il loro quadro può guidare la progettazione di protesi di nuova generazione, strumenti per la riabilitazione e interfacce cervello–computer che non siano solo accurate, ma anche stabili, confortevoli e su misura per lo stile di apprendimento di ciascun utente.
Citazione: Madduri, M.M., Yamagami, M., Li, S.J. et al. Computational framework to predict and shape human–machine interactions in closed-loop, co-adaptive neural interfaces. Nat Mach Intell 8, 372–387 (2026). https://doi.org/10.1038/s42256-026-01194-z
Parole chiave: interfacce neurali, interazione uomo macchina, controllo co adattivo, controllo cursore mioelettrico, progettazione interfacce cervello-computer