Clear Sky Science · pt
Estrutura computacional para prever e moldar interações humano–máquina em interfaces neurais co-adaptativas e em malha fechada
Ensinando Máquinas a Aprender Conosco
À medida que interfaces cérebro–computador e próteses avançadas saem do laboratório e entram na vida cotidiana, surge uma questão central: como projetar dispositivos que aprendam conosco ao mesmo tempo em que nós aprendemos a usá‑los? Este estudo enfrenta esse desafio ao construir uma estrutura matemática e experimental para interfaces neurais “co‑adaptativas” — sistemas nos quais tanto o usuário humano quanto o algoritmo de decodificação se ajustam continuamente um ao outro, de modo que o controle se torne mais suave, natural e confiável ao longo do tempo. 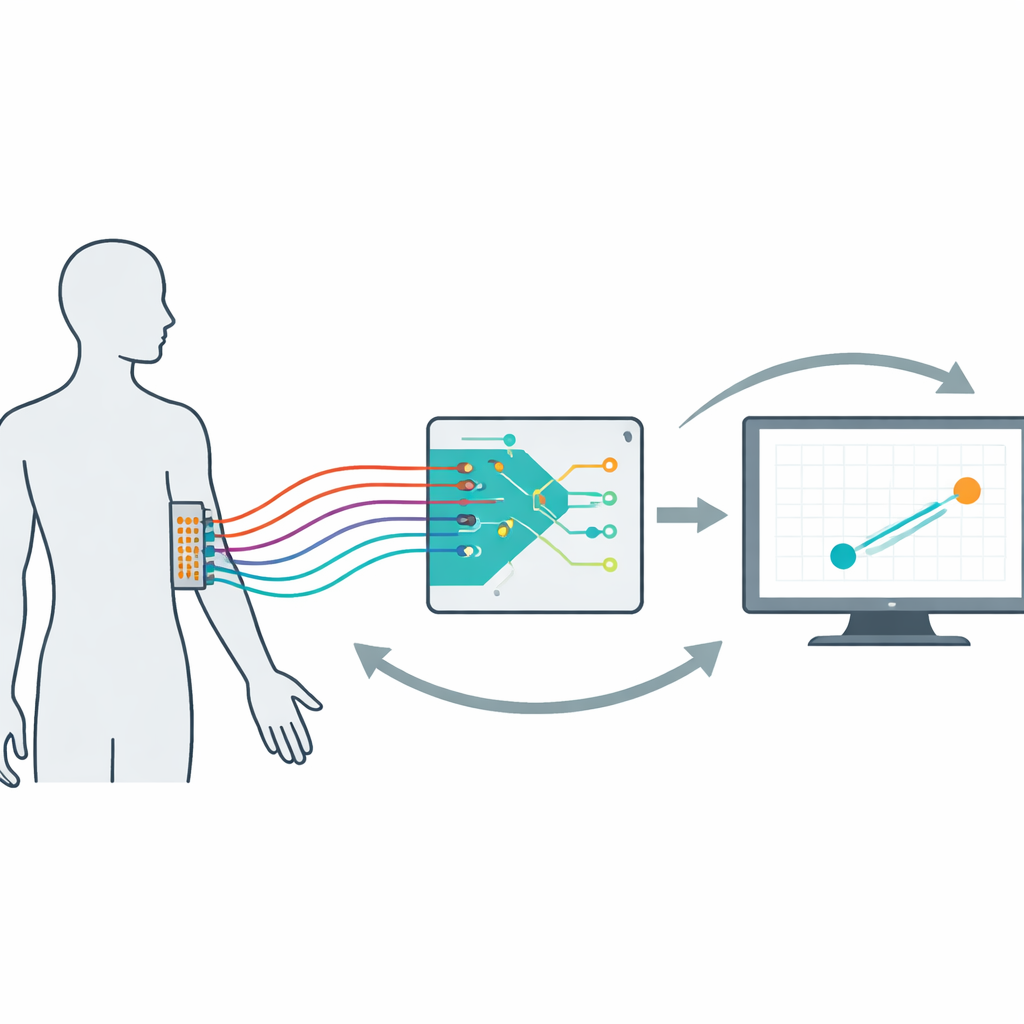
Um Novo Tipo de Parceria Humano–Máquina
Muitas interfaces neurais funcionam traduzindo sinais biológicos de alta dimensionalidade, como atividade muscular ou cerebral, em comandos simples que movem um cursor ou um membro robótico. Tradicionalmente, os projetistas tentam otimizar ou o lado humano (treinando o usuário para se adaptar a um decodificador fixo) ou o lado da máquina (permitindo que o decodificador se atualize assumindo um usuário essencialmente fixo). Na prática, ambos os lados estão constantemente aprendendo. Esse arranjo de dois aprendizes pode desbloquear desempenho e personalização melhores, mas também é mais difícil de projetar: se o algoritmo se adaptar rápido demais ou de forma inadequada, pode confundir o usuário em vez de ajudar. Os autores reúnem ferramentas da teoria de controle e da teoria dos jogos para descrever, prever e, em última instância, moldar esses processos de aprendizado entrelaçados.
Construindo um Banco de Testes Seguro para Interfaces Co‑Adaptativas
Para estudar essas dinâmicas de forma controlada, os pesquisadores criaram uma interface mioelétrica não invasiva. Quatorze voluntários usaram uma grade de 64 eletrodos no antebraço dominante. A atividade muscular deles controlava um cursor no computador que devia seguir um alvo errante na tela. Por baixo do capô, um decodificador convertia os sinais musculares em velocidade do cursor e se atualizava a cada 20 segundos com base no desempenho recente. Ao longo de 16 ensaios de cinco minutos por pessoa, a equipe variou sistematicamente quão rápido o decodificador aprendia, quão fortemente era penalizado por usar grandes ganhos de sinal (seu “esforço”) e como ele era inicializado. Ao examinar tanto o comportamento quanto os padrões musculares, confirmaram que os usuários não apenas esperavam o algoritmo melhorar; eles mudavam ativamente a forma de usar os músculos dentro e entre os ensaios, criando um loop humano–máquina verdadeiramente co‑adaptativo.
Usando Teoria de Controle para Ver Dentro do Loop
O passo seguinte foi transformar essa interação complicada em um modelo que pudesse ser medido e testado. Usando ideias da teoria de controle, os autores estimaram uma descrição matemática compacta da estratégia de cada usuário — um “codificador” que mapeia informações do alvo e do cursor em padrões de atividade muscular. Esse codificador pôde ser separado em uma parte preditiva, feedforward, e uma parte corretiva, de realimentação. Ao combinar o codificador estimado com o decodificador conhecido, a equipe pôde avaliar se o sistema como um todo estava no caminho para um controle preciso e estável. Eles descobriram que, com o tempo, o par usuário–decodificador tendia a se mover em direção a valores previstos como favoráveis ao rastreamento e à estabilidade, embora nem o usuário nem o decodificador deixassem de mudar completamente. Os usuários também mostraram sinais de aprendizado em prazo mais longo, com seus mapeamentos musculares variando menos de um ensaio para outro à medida que ficavam mais proficientes. 
Teoria dos Jogos Revela Como Regras de Aprendizado Moldam o Comportamento
Para ir além da descrição e realmente prever como escolhas de projeto afetariam a co‑adaptação, os autores recorreram à teoria dos jogos, que estuda como múltiplos tomadores de decisão interagem quando cada um tenta minimizar seu próprio custo. Eles modelaram o usuário e o decodificador como dois “jogadores” que se importam em reduzir o erro de rastreamento, mas também pagam um preço pelo esforço — ativação muscular para o usuário e grandes ganhos para o decodificador. Nesse quadro, o sistema conjunto pode se acomodar em um de vários estados estáveis, ou pontos estacionários, dependendo das taxas de aprendizado, penalidades de esforço e condições iniciais. O modelo fez previsões concretas: a taxa de aprendizado do decodificador deve afetar fortemente quão rápido e quão bem o sistema converge; ajustar a penalidade de esforço do decodificador deve deslocar quanto esforço o usuário precisa investir sem necessariamente mudar a precisão; e configurações iniciais do decodificador podem sutilmente viésar a estratégia final do usuário.
Testando Como Algoritmos Conduzem o Aprendizado Humano
Os experimentos confirmaram em grande parte essas previsões. Quando o decodificador aprendia lentamente, os usuários melhoravam mais dentro de um ensaio, e o par codificador–decodificador combinado se aproximava mais do regime teoricamente ideal para controle preciso e estável do cursor. Quando o decodificador se adaptava rápido demais, o desempenho piorava e os usuários mudavam menos suas estratégias musculares, sugerindo que a máquina estava se movendo mais rápido do que as pessoas conseguiam acompanhar. Mudar a penalidade de esforço do decodificador forneceu outra alavanca: penalidades maiores empurravam o decodificador a trabalhar menos, o que por sua vez levou muitos usuários a aumentarem seu próprio esforço muscular para manter a precisão. Interessantemente, os participantes diferiram em como equilibravam esforço e velocidade do cursor — alguns optaram por trabalhar mais para manter o cursor rápido, enquanto outros aceitaram movimentos mais lentos para poupar esforço — apontando para preferências individuais que futuras interfaces poderiam personalizar.
O Que Isso Significa para Interfaces Neurais Futuras
Em termos simples, este trabalho mostra que as regras de treinamento embutidas em algoritmos de interface neural fazem mais do que limpar sinais ruidosos; elas moldam ativamente como as pessoas aprendem a usar o dispositivo. Ao combinar modelagem rigorosa com experimentos humanos, os autores oferecem um conjunto de ferramentas para escolher taxas de aprendizado do decodificador, penalidades de esforço e inicializações de forma principiada, em vez de por tentativa e erro. Sua estrutura pode orientar o projeto de próteses de próxima geração, ferramentas de reabilitação e interfaces cérebro–computador que não sejam apenas precisas, mas também estáveis, confortáveis e adaptadas ao estilo de aprendizado de cada usuário.
Citação: Madduri, M.M., Yamagami, M., Li, S.J. et al. Computational framework to predict and shape human–machine interactions in closed-loop, co-adaptive neural interfaces. Nat Mach Intell 8, 372–387 (2026). https://doi.org/10.1038/s42256-026-01194-z
Palavras-chave: interfaces neurais, interação humano máquina, controle co adaptativo, controle de cursor mioelétrico, projeto de interface cérebro computador