Clear Sky Science · de
Rechnerischer Rahmen zur Vorhersage und Gestaltung von Mensch‑Maschine‑Interaktionen in geschlossenem Regelkreis und ko‑adaptiven neuronalen Schnittstellen
Maschinen beibringen, mit uns zu lernen
Wenn Gehirn‑Computer‑Schnittstellen und fortgeschrittene Prothesen von der Forschung in den Alltag übergehen, stellt sich eine zentrale Frage: Wie entwirft man Geräte, die gleichzeitig von uns lernen, während wir lernen, sie zu benutzen? Diese Studie nimmt diese Herausforderung an, indem sie einen mathematischen und experimentellen Rahmen für „ko‑adaptive“ neuronale Schnittstellen entwickelt — Systeme, in denen sowohl der menschliche Nutzer als auch der Decodieralgorithmus sich fortlaufend aneinander anpassen, sodass die Steuerung im Laufe der Zeit flüssiger, natürlicher und zuverlässiger wirkt. 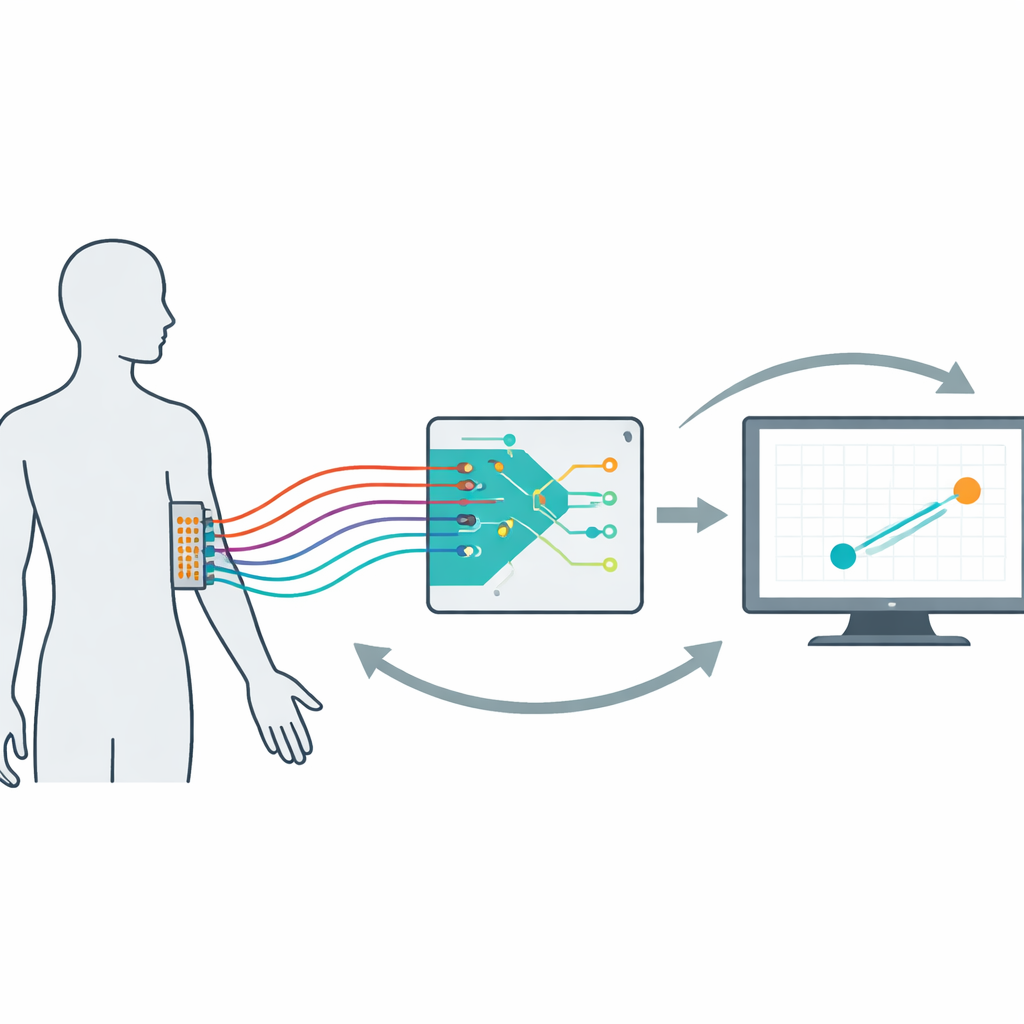
Eine neue Form der Mensch‑Maschine‑Partnerschaft
Viele neuronale Schnittstellen übersetzen hochdimensionale biologische Signale, etwa Muskel‑ oder Gehirnaktivität, in einfache Befehle, mit denen ein Cursor oder ein robotisches Glied bewegt wird. Traditionell haben Entwickler entweder versucht, die menschliche Seite zu optimieren (den Nutzer auf einen festen Decoder zu trainieren) oder die maschinelle Seite (den Decoder anzupassen und dabei von einem weitgehend festen Nutzer auszugehen). In Wirklichkeit lernen jedoch beide Seiten ständig. Diese Zwei‑Lernenden‑Konstellation kann bessere Leistung und stärkere Personalisierung ermöglichen, ist aber auch schwerer zu entwerfen: Lernt der Algorithmus zu schnell oder in ungeeigneter Weise, kann er den Nutzer eher verwirren als unterstützen. Die Autoren verbinden Werkzeuge aus der Regelungstheorie und der Spieltheorie, um diese verflochtenen Lernprozesse zu beschreiben, vorherzusagen und gezielt zu steuern.
Ein sicheres Testfeld für ko‑adaptive Schnittstellen schaffen
Um diese Dynamiken kontrolliert zu untersuchen, entwickelten die Forscher eine nichtinvasive myoelektrische Schnittstelle. Vierzehn Freiwillige trugen ein 64‑Elektroden‑Gitter auf ihrem dominanten Unterarm. Ihre Muskelaktivität steuerte einen Computer‑Cursor, der einem wandernden Ziel auf dem Bildschirm folgen musste. Unter der Haube wandelte ein Decoder die Muskelsignale in Cursor‑Geschwindigkeit um und aktualisierte sich alle 20 Sekunden basierend auf der jüngsten Leistung. Über 16 Versuche à fünf Minuten pro Person variierte das Team systematisch, wie schnell der Decoder lernte, wie stark er für den Einsatz großer Signalverstärkungen (seinen „Aufwand“) bestraft wurde und wie er initialisiert war. Durch die Untersuchung sowohl des Verhaltens als auch der Muskelmuster bestätigten sie, dass Nutzer nicht bloß auf Verbesserungen des Algorithmus warteten, sondern aktiv veränderten, wie sie ihre Muskeln innerhalb und zwischen den Versuchen einsetzten, wodurch eine echte ko‑adaptive Mensch‑Maschine‑Schleife entstand.
Mit Regelungstheorie in die Schleife blicken
Der nächste Schritt war, diese unordentliche Interaktion in ein messbares und prüfbares Modell zu überführen. Mithilfe von Konzepten aus der Regelungstheorie schätzten die Autoren eine kompakte mathematische Beschreibung der Strategie jedes Nutzers — einen „Encoder“, der Ziel‑ und Cursor‑Informationen in Muskelaktivitätsmuster abbildet. Dieser Encoder ließ sich in einen prädiktiven, feedforward‑Anteil und einen korrigierenden, feedback‑Anteil aufteilen. Durch die Kombination des geschätzten Encoders mit dem bekannten Decoder konnte das Team beurteilen, ob das Gesamtsystem auf einer Bahn für genaue und stabile Steuerung lag. Sie fanden, dass sich das kombinierte Nutzer‑Decoder‑Paar im Zeitverlauf zu Werten hin bewegte, die für gutes Tracking und Stabilität vorhergesagt wurden, obwohl weder Nutzer noch Decoder jemals völlig aufhörten, sich zu verändern. Nutzer zeigten zudem Anzeichen langfristigen Lernens: Ihre Muskelzuordnungen veränderten sich von Versuch zu Versuch weniger, je geübter sie wurden. 
Spieltheorie zeigt, wie Lernregeln Verhalten formen
Um über die bloße Beschreibung hinauszugehen und tatsächlich vorherzusagen, wie Designentscheidungen die Ko‑Adaptation beeinflussen würden, griffen die Autoren auf die Spieltheorie zurück, die untersucht, wie mehrere Entscheidungsträger interagieren, wenn jeder versucht, seine eigenen Kosten zu minimieren. Sie modellierten Nutzer und Decoder als zwei „Spieler“, denen beide an der Reduktion des Tracking‑Fehlers gelegen ist, die aber auch einen Preis für Aufwand zahlen — Muskelaktivierung beim Nutzer und große Verstärkungen beim Decoder. In diesem Rahmen kann das gemeinsame System, abhängig von Lernraten, Aufwandsstrafen und Startbedingungen, in einem von mehreren stabilen Zuständen (stationären Punkten) landen. Das Modell machte konkrete Vorhersagen: Die Lernrate des Decoders sollte stark beeinflussen, wie schnell und wie gut das System konvergiert; die Anpassung der Aufwandsstrafe des Decoders sollte verändern, wie viel Aufwand der Nutzer investieren muss, ohne zwangsläufig die Genauigkeit zu ändern; und Anfangseinstellungen des Decoders könnten die letztendliche Strategie des Nutzers subtil vorprägen.
Experimentell prüfen, wie Algorithmen menschliches Lernen lenken
Die Experimente bestätigten diese Vorhersagen größtenteils. Lernte der Decoder langsam, verbesserten sich die Nutzer innerhalb eines Versuchs stärker, und das kombinierte Encoder‑Decoder‑Paar näherte sich eher dem theoretisch idealen Bereich für genaue und stabile Cursorsteuerung. Passte sich der Decoder zu schnell an, verschlechterte sich die Leistung und Nutzer veränderten ihre Muskelstrategien weniger, was darauf hindeutet, dass die Maschine schneller vorging, als die Menschen folgen konnten. Die Veränderung der Aufwandsstrafe des Decoders bot einen weiteren Hebel: Höhere Strafen veranlassten den Decoder, weniger stark zu arbeiten, wodurch viele Nutzer wiederum ihre eigene Muskelanstrengung erhöhten, um die Genauigkeit aufrechtzuerhalten. Interessanterweise unterschieden sich die Teilnehmenden darin, wie sie Aufwand und Cursor‑Geschwindigkeit abwogen — einige arbeiteten härter, um den Cursor schnell zu halten, andere akzeptierten langsamere Bewegungen, um Aufwand zu sparen — ein Hinweis auf individuelle Präferenzen, die künftige Schnittstellen personalisieren könnten.
Was das für zukünftige neuronale Schnittstellen bedeutet
Vereinfacht gesagt zeigt diese Arbeit, dass die Trainingsregeln, die in Algorithmen für neuronale Schnittstellen eingebaut sind, mehr bewirken als nur Rauschunterdrückung: Sie formen aktiv, wie Menschen lernen, das Gerät zu nutzen. Durch die Kombination rigoroser Modellierung mit Humanexperimenten liefern die Autoren ein Werkzeugset, um Decoder‑Lernraten, Aufwandsstrafen und Initialisierungen prinzipiengeleitet statt durch Trial‑and‑Error auszuwählen. Ihr Rahmen kann das Design der nächsten Generation von Prothesen, Rehabilitations‑Instrumenten und Gehirn‑Computer‑Schnittstellen leiten, die nicht nur genau, sondern auch stabil, komfortabel und auf den jeweiligen Lernstil des Nutzers zugeschnitten sind.
Zitation: Madduri, M.M., Yamagami, M., Li, S.J. et al. Computational framework to predict and shape human–machine interactions in closed-loop, co-adaptive neural interfaces. Nat Mach Intell 8, 372–387 (2026). https://doi.org/10.1038/s42256-026-01194-z
Schlüsselwörter: neuronale Schnittstellen, Mensch‑Maschine‑Interaktion, koadaptive Regelung, myoelektrische Cursorsteuerung, Design von Gehirn‑Computer‑Schnittstellen