Clear Sky Science · sv
Beräkningsramverk för att förutsäga och forma mänsklig–maskininteraktion i slutna, ko-adaptiva neurala gränssnitt
Lära maskiner att lära tillsammans med oss
När hjärn–datorgränssnitt och avancerade proteser går från labbet till vardagslivet uppstår en central fråga: hur kan vi utforma enheter som lär sig av oss samtidigt som vi lär oss använda dem? Denna studie tar sig an den utmaningen genom att bygga ett matematiskt och experimentellt ramverk för ”ko-adaptiva” neurala gränssnitt — system där både den mänskliga användaren och avkodningsalgoritmen kontinuerligt anpassar sig till varandra så att styrning känns smidigare, mer naturlig och mer pålitlig över tid. 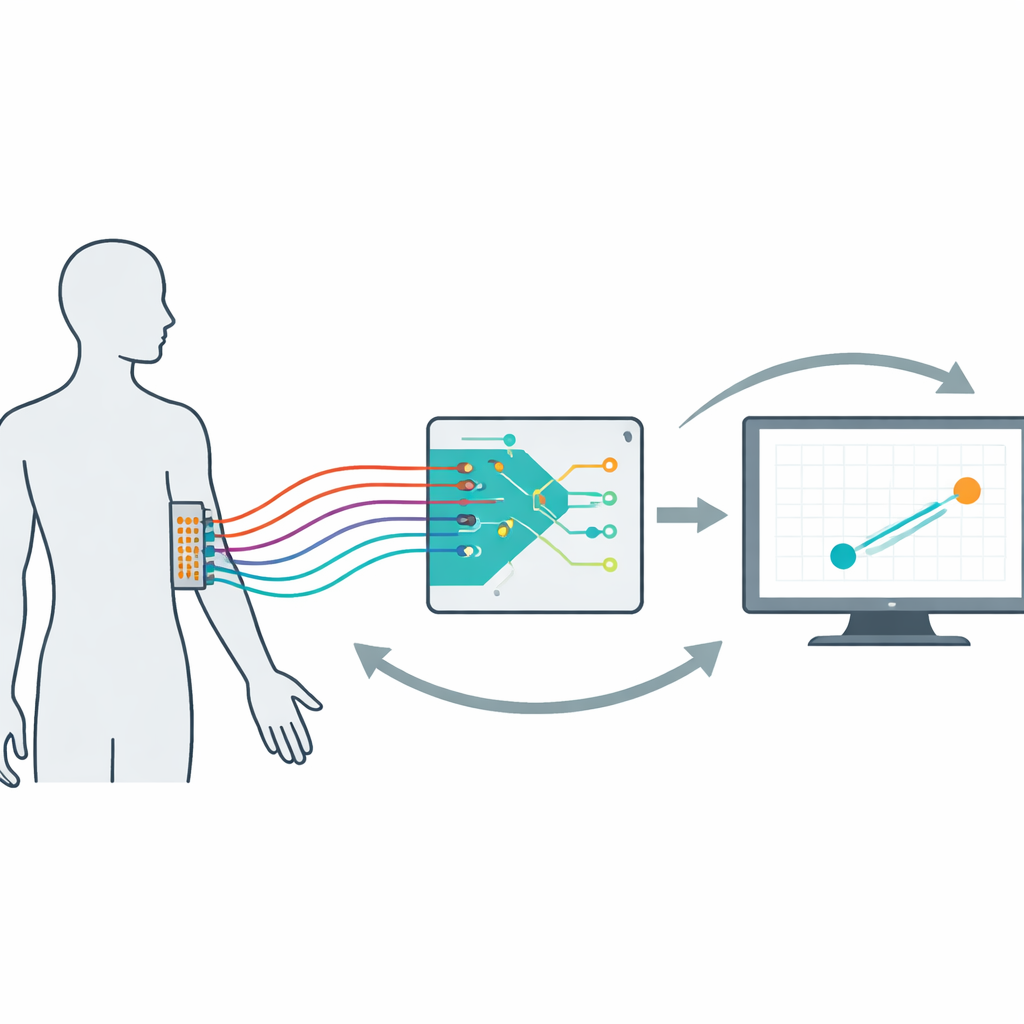
En ny sorts människa–maskinpartnerskap
Många neurala gränssnitt fungerar genom att översätta högdimensionella biologiska signaler, såsom muskel- eller hjärnaktivitet, till enkla kommandon som kan flytta en markör eller en robotarm. Traditionellt har designers försökt optimera antingen människosidan (träna användaren att anpassa sig till en fast avkodare) eller masksidan (låta avkodaren uppdateras under antagandet att användaren är i stort sett oförändrad). I verkligheten lär sig båda sidor ständigt. Denna två-lärande konstellation kan frigöra bättre prestanda och personalisering, men är också svårare att designa: om algoritmen anpassar sig för snabbt eller på fel sätt kan den förvirra användaren istället för att hjälpa. Författarna förenar verktyg från styrteori och spelteori för att beskriva, förutsäga och i slutändan forma dessa sammanflätade inlärningsprocesser.
Bygga en säker testbädd för ko-adaptiva gränssnitt
För att studera dessa dynamiker på ett kontrollerat sätt skapade forskarna ett icke-invasivt myoelektriskt gränssnitt. Fjorton frivilliga bar ett 64-elektrodsgaller på sin dominanta underarm. Deras muskelaktivitet styrde en datormarkör som skulle följa ett vandrande mål på skärmen. Under ytan konverterade en avkodare muskelsignalerna till markörhastighet och uppdaterade sig själv var 20:e sekund baserat på senaste prestandan. Under 16 femminutersförsök per person varierade teamet systematiskt hur snabbt avkodaren lärde sig, hur hårt den bestraffades för att använda stora signalförstärkningar (dess ”insats”), och hur den initialiserades. Genom att granska både beteende och muskelmönster bekräftade de att användarna inte bara väntade på att algoritmen skulle förbättras; de ändrade aktivt hur de använde sina muskler inom och mellan försök och skapade en äkta ko-adaptiv människa–maskin-loop.
Använda styrteori för att se in i loopen
Nästa steg var att förvandla denna röriga interaktion till en modell som kunde mätas och testas. Med idéer från styrteori skattade författarna en kompakt matematisk beskrivning av varje användares strategi — en ”kodare” som kartlägger mål- och markörinformation till mönster av muskelaktivitet. Denna kodare kunde delas upp i en förutsägande, framåtriktad del och en korrigerande, återkopplande del. Genom att kombinera den skattade kodaren med den kända avkodaren kunde teamet bedöma om hela systemet var på väg mot noggrann och stabil styrning. De fann att över tid tenderade det kombinerade användar–avkodarparet att röra sig mot värden som förutspåddes ge god spårning och stabilitet, även om varken användaren eller avkodaren någonsin slutade förändras helt. Användare visade också tecken på längre tidsinlärning, där deras muskelkartläggningar förändrades mindre från försök till försök i takt med att de blev skickligare. 
Spelteori avslöjar hur inlärningsregler formar beteende
För att gå bortom beskrivning och faktiskt förutsäga hur designval skulle påverka ko-adaptationen vände sig författarna till spelteori, som studerar hur flera beslutstagare interagerar när var och en försöker minimera sin egen kostnad. De modellerade användaren och avkodaren som två ”spelare” som båda bryr sig om att minska spårningsfel men också betalar ett pris för insats — muskelaktivering för användaren och stora förstärkningar för avkodaren. I detta ramverk kan det gemensamma systemet stanna i en av flera stabila tillstånd, eller stationära punkter, beroende på inlärningshastigheter, insatsstraff och startvillkor. Modellen gav konkreta förutsägelser: avkodarens inlärningshastighet bör starkt påverka hur snabbt och hur väl systemet konvergerar; justering av avkodarens insatsstraff bör förändra hur mycket ansträngning användaren måste lägga ner utan att nödvändigtvis ändra noggrannheten; och initiala avkodarinställningar kan subtilt vinkla användarens slutgiltiga strategi.
Testa hur algoritmer styr mänsklig inlärning
Experimenten bekräftade i stort dessa prediktioner. När avkodaren lärde sig långsamt förbättrade sig användarna mer inom ett försök, och det kombinerade kodare–avkodarparet rörde sig närmare det teoretiskt idealiska läget för noggrann och stabil markörstyrning. När avkodaren anpassade sig för snabbt försämrades prestationen och användarna förändrade sina muskelstrategier mindre, vilket tyder på att maskinen rörde sig snabbare än vad människor kunde följa. Att ändra avkodarens insatsstraff gav ytterligare en spak: högre straff fick avkodaren att arbeta mindre, vilket i sin tur ledde till att många användare ökade sin egen muskelinsats för att bibehålla noggrannheten. Intressant nog skilde sig deltagarna åt i hur de balanserade insats och markörhastighet — några valde att arbeta hårdare för att hålla markören snabb, medan andra accepterade långsammare rörelser för att spara ansträngning — vilket antyder individuella preferenser som framtida gränssnitt kan anpassa efter.
Vad detta betyder för framtida neurala gränssnitt
Enkelt uttryckt visar detta arbete att träningsreglerna inbyggda i neurala gränssnittsalgoritmer gör mer än att rensa upp brusiga signaler; de formar aktivt hur människor lär sig använda enheten. Genom att kombinera rigorös modellering med mänskliga experiment erbjuder författarna en verktygslåda för att välja avkodarens inlärningshastigheter, insatsstraff och initialiseringar på ett principfast sätt istället för genom trial-and-error. Deras ramverk kan vägleda utformningen av nästa generations proteser, rehabiliteringsverktyg och hjärn–datorgränssnitt som inte bara är exakta, utan också stabila, bekväma och anpassade efter varje användares inlärningsstil.
Citering: Madduri, M.M., Yamagami, M., Li, S.J. et al. Computational framework to predict and shape human–machine interactions in closed-loop, co-adaptive neural interfaces. Nat Mach Intell 8, 372–387 (2026). https://doi.org/10.1038/s42256-026-01194-z
Nyckelord: neurala gränssnitt, människa maskin-interaktion, ko adaptiv kontroll, myoelektrisk markörstyrning, hjärn-datorgränssnittsdesign