Clear Sky Science · tr
DRLO-VANET: VANET’lerde düşük gecikmeli ve enerji verimli görev yürütme için derin pekiştirmeli öğrenmeye dayalı bir offloading çerçevesi
Neden Daha Akıllı Araç Hesaplaması Önemli?
Günümüz otomobilleri, özellikle sürücüsüz olanlar, hareket eden bilgisayarlara dönüşüyor. Yolcuların güvenliğini sağlamak ve trafiği akıcı tutmak için sürekli olarak kamera görüntülerini, radarı, haritaları ve trafik bilgilerini yorumluyorlar. Ancak tüm bu hesaplama zaman ve enerji gerektirir. Bugünün araçları verileri ya kendi üzerinde işleyebilir ya da yakındaki yol kenarı bilgisayarlarına gönderebilir. Yanlış seçim gecikmelere, tamamlanmayan görevlere veya pil israfına yol açabilir. Bu makale, trafik ve ağ koşullarına gerçek zamanlı uyum sağlayan öğrenme algoritmaları kullanarak bu seçimleri otomatik ve akıllı biçimde yapmanın yeni bir yolunu inceliyor.
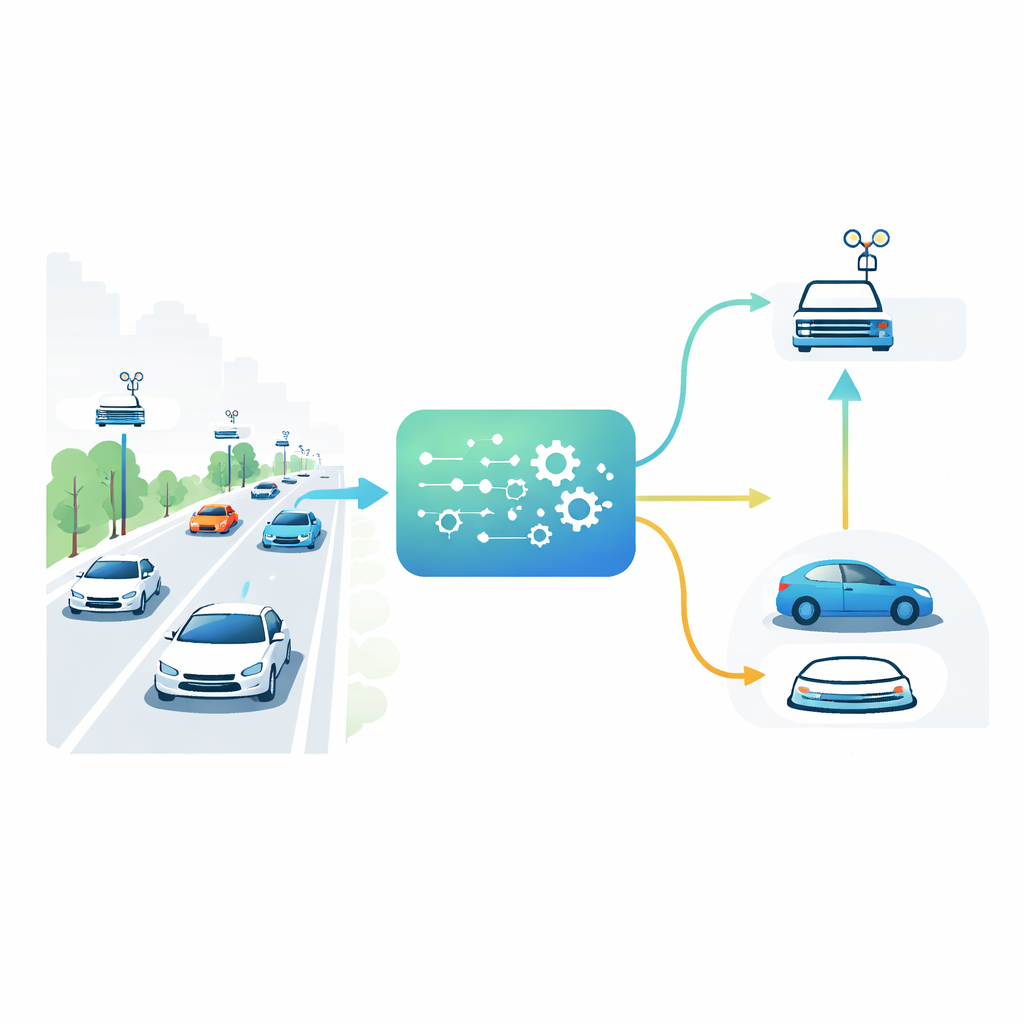
Araçlar, Yollar ve Yakındaki Yardımcılar
Geleceğin şehirlerinde araçlar yalnızca birbirleriyle değil, aynı zamanda sokak boyunca yerleştirilmiş yol kenarı birimlerindeki küçük bilgisayarlarla da konuşacak. Bu yol kenarı birimleri, uzak bulut sunucularından çok daha yakın olan yerel mini veri merkezleri gibi davranır. Bir kavşağa yaklaşan bir araç, gizli yayaları tespit etmek için kamera ve sensör verilerini birleştirmek gibi ağır bir görev çalıştırmak zorunda kalabilir. Bu görevi ya kendi sınırlı işlemcisinde çalıştırır ya da yol kenarındaki birimine offload eder. En iyi seçim, yolun ne kadar kalabalık olduğuna, her bir yol kenarı bilgisayarının ne kadar meşgul olduğuna, kablosuz sinyalin gücüne ve görevin ne kadar acil olduğuna bağlıdır. Bu koşullar saniye saniye değiştiği için—örneğin her zaman en yakın yol kenarı birimini kullanmak gibi—statik kurallar gerçek trafik altında başarısız olur.
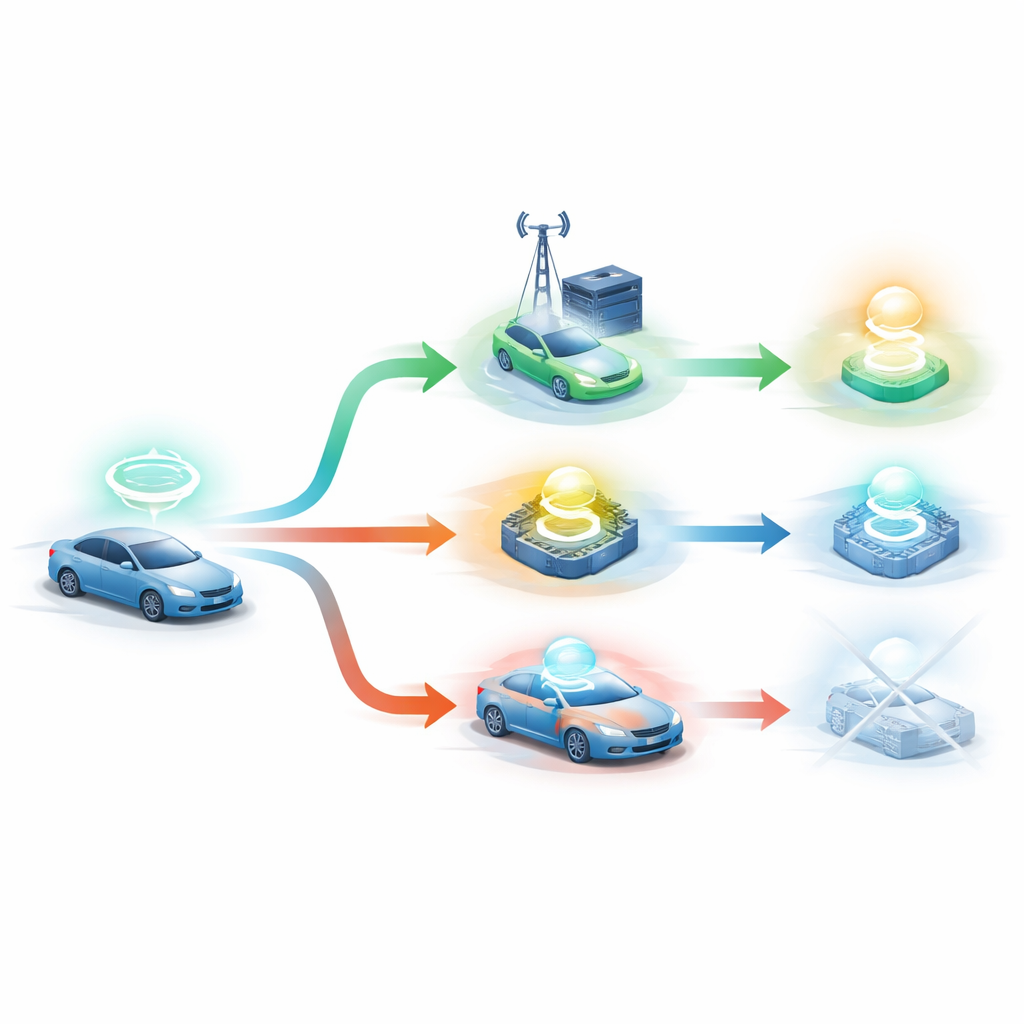
Sistemin Kendi Kendine Öğrenmesine İzin Vermek
Yazarlar, el yapımı kurallara dayanmak yerine deneme-yanılma yoluyla iyi kararlar öğrenmesine izin veren DRLO-VANET adlı bir çerçeve öneriyor. Kurulumlarında her araç, etrafını gözlemleyen bir karar verici olarak ele alınıyor—araç yoğunluğu, sinyal kalitesi, kendi pil düzeyi, her görevin boyutu ve son teslim süresi ve yol kenarı birimlerinin yük durumu gibi. Bir öğrenme ajanı ardından birkaç seçenek arasından seçim yapıyor: yerel olarak işlemek, görevi birkaç yol kenarı biriminden birine göndermek veya işi araç ile yol kenarı arasında bölüştürmek. Her karardan sonra sistem, görevin ne kadar sürdüğünü, ne kadar enerji tüketildiğini, görevin zamanında bitip bitmediğini, yol kenarı kullanımının ne kadar dengeli olduğunu ve aracın hareket ederken bir yol kenarı biriminden diğerine kaç kez geçiş yaptığını ölçüyor. Bu sonuçlar tek bir geri bildirim puanında birleştirilerek öğrenme ajanını zaman içinde daha iyi seçimlere doğru yönlendiriyor.
Gerçekçi Bir Test Ortamı Kurmak
Öğrenilen stratejinin pratikte işe yarayıp yaramadığını değerlendirmek için araştırmacılar ns-3 ağ simülatörünü bir pekiştirmeli öğrenme araç takımıyla bağlayarak detaylı bir bilgisayar simülasyonu kurdular. Sanal şehirleri kavşaklı yollar, farklı hızlarda hareket eden araçlar ve kapsama alanlarının gerçek dağılımı gibi örtüşecek şekilde bir ızgara halinde yerleştirilmiş yol kenarı birimlerini içeriyor. Kablosuz bağlantılar, açık otoyollar ve binaların yansımalar ve sinyal kaybına yol açtığı yoğun kentsel “kanyonlar” için gerçekçi modelleri izliyor. Her araçta farklı boyut ve son teslim sürelerine sahip görevler ortaya çıkıyor ve yol kenarı bilgisayarları kuyruklarla ve sınırlı işlem gücüyle modelleniyor; böylece birçok araç aynı anda offload ettiğinde tıkanma oluşabiliyor. Derin Q-Ağları (Deep Q-Networks) ve Soft Actor-Critic gibi iki popüler öğrenme yöntemi, birçok simüle edilmiş sürüş ve kanal koşulu üzerinde karar politikalarını eğitmek için kullanılıyor.
Öğrenme Yaklaşımı Ne Kadar İyi Çalışıyor?
Ekip DRLO-VANET’i üç yaygın alternatifle karşılaştırdı: her zaman araç içinde işlemek, her zaman en yakın yol kenarı birimine offload etmek ve kısa vadeli en düşük gecikmeyi kovalayan “açgözlü” bir strateji. Hafif trafikte tüm yöntemler makul performans gösteriyor, ancak ağa daha fazla araç girince basit kuralların zayıflıkları ortaya çıkıyor. En yakın birime offload etmek birkaç yol kenarı bilgisayarını aşırı yükleyerek uzun kuyruklara neden oluyor. Açgözlü strateji başlangıçta gecikmeyi en aza indiriyor ama araçları yol kenarı birimleri arasında sürekli anahtarlamaya zorluyor; bu da ek yük ve istikrarsızlık getiriyor. Buna karşılık, öğrenilmiş DRLO-VANET politikası yükü daha eşit dağıtıyor, açıkça kötü kablosuz bağlantılardan kaçınıyor ve gereksiz el değiştirmeleri sınırlıyor. Simülasyonlarda görev gecikmesini yaklaşık %40’a varan oranda azaltıyor, enerji kullanımını %30–35 oranında düşürüyor, orta trafikte görevlerin %90’dan fazlasını zamanında tutuyor ve açgözlü yönteme göre el değiştirme olaylarını yaklaşık yarı yarıya azaltıyor.
Günlük Sürücüler İçin Anlamı
Uzman olmayanlar için temel çıkarım, araçlar ve yolların bugün olduğundan çok daha akıllıca işbirliği yapabileceği. Katı kurallar yerine öğrenmeye dayalı bir denetleyici, yolun ve ağın ne kadar meşgul olduğunu izleyerek her dijital görevin nerede çalıştırılması gerektiğini sessizce seçebilir; böylece yanıtlar hızlı kalır, piller daha uzun süre dayanır ve yol kenarı ekipmanı aşırı yüklenmez. Bu çalışma gerçek araçlar yerine simülasyona dayansa da, otonom sürüş için gereken “düşünmenin” araçlar ile yakın altyapı arasında otomatik olarak bölüştürüldüğü, kalabalık ve hızla değişen trafikte bile gelişmiş güvenlik ve navigasyon hizmetlerini daha güvenilir kılan bir geleceğe işaret ediyor.
Atıf: Neelima, S., Sree, S.R. & Ramakrishnaiah, N. DRLO-VANET: a deep reinforcement learning-based offloading framework for low-latency and energy-efficient task execution in VANETs. Sci Rep 16, 10582 (2026). https://doi.org/10.1038/s41598-026-46336-w
Anahtar kelimeler: otonom araçlar, uç (edge) bilişim, taşıt ağları, pekiştirmeli öğrenme, görev offloadingi