Clear Sky Science · de
DRLO-VANET: ein auf Deep Reinforcement Learning basierendes Offloading‑Framework für latenzarme und energieeffiziente Aufgabenausführung in VANETs
Warum klügeres Rechnen im Auto wichtig ist
Moderne Autos, besonders selbstfahrende, werden zu fahrenden Computern. Sie werten ständig Kamerabilder, Radar, Karten und Verkehrsinformationen aus, um Insassen zu schützen und den Verkehr am Fließen zu halten. All dieses Denken erfordert jedoch Zeit und Energie. Heutige Fahrzeuge können die Berechnungen entweder an Bord durchführen oder sie an nahegelegene Straßenrechner senden. Die falsche Wahl kann Verzögerungen, Abbrüche von Aufgaben oder unnötigen Energieverbrauch bedeuten. Dieses Papier untersucht eine neue Methode, diese Entscheidungen automatisch und intelligent zu treffen, mithilfe von Lernalgorithmen, die sich in Echtzeit an Verkehr und Netzwerkbedingungen anpassen.
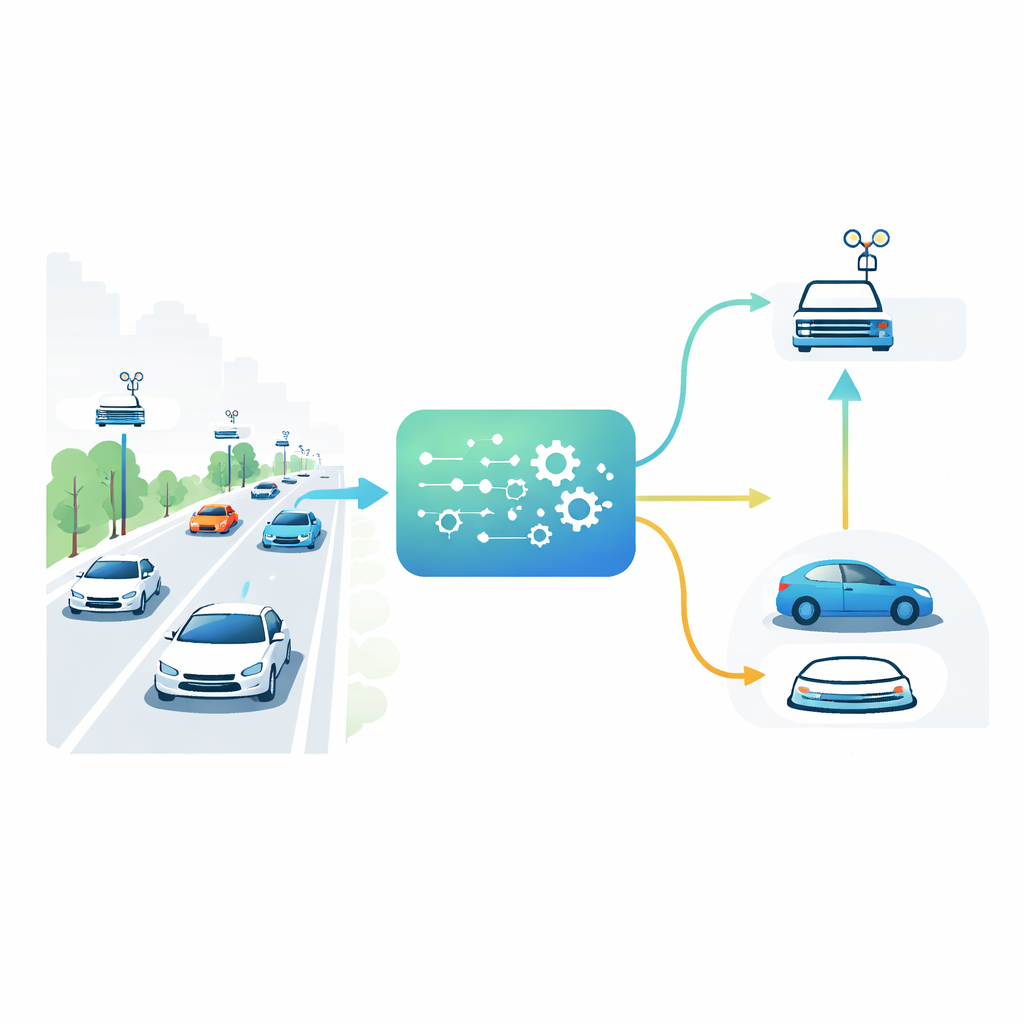
Autos, Straßen und nahe Helfer
In zukünftigen Städten werden Fahrzeuge nicht nur miteinander kommunizieren, sondern auch mit kleinen Rechnern in Straßeninfrastruktur entlang der Wege. Diese Roadside‑Units fungieren wie lokale Mini‑Rechenzentren, deutlich näher als entfernte Cloud‑Server. Ein Fahrzeug, das sich einer Kreuzung nähert, muss vielleicht eine rechenintensive Aufgabe ausführen, etwa Kameradaten und Sensorinformationen zur Erkennung verdeckter Fußgänger zusammenführen. Es kann die Aufgabe entweder auf dem begrenzten Prozessor an Bord verarbeiten oder an eine der Roadside‑Units auslagern. Die beste Wahl hängt davon ab, wie dicht der Verkehr ist, wie ausgelastet die einzelnen Roadside‑Rechner sind, wie stark das Funksignal ist und wie dringend die Aufgabe ist. Da sich all diese Bedingungen Sekunde für Sekunde ändern, versagen statische Regeln — etwa immer die nächstgelegene Roadside‑Unit zu nutzen — unter realem Verkehr.
Das System selbst lernen lassen
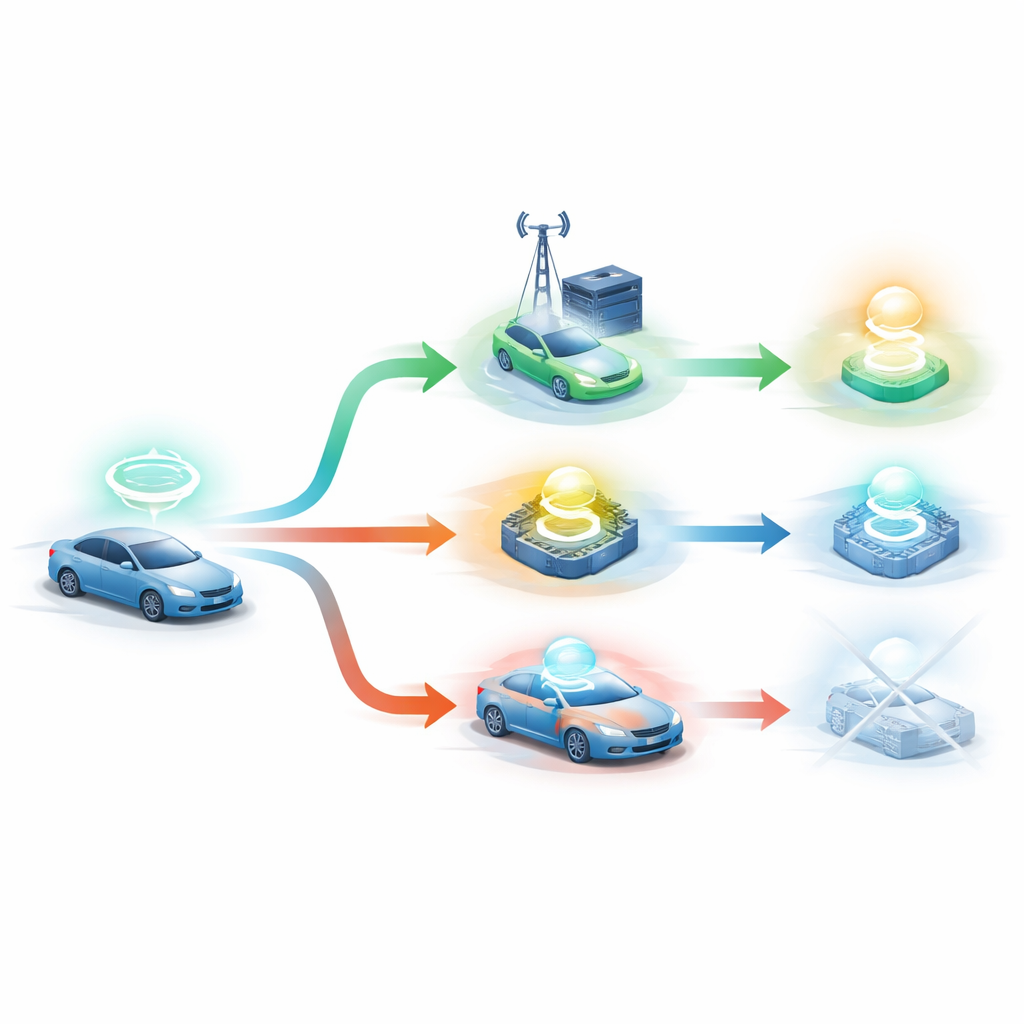
Die Autoren schlagen DRLO‑VANET vor, ein Framework, das das System durch Trial‑and‑Error gute Entscheidungen lernen lässt, statt auf handgefertigte Regeln zu setzen. In ihrem Aufbau wird jedes Fahrzeug als Entscheidungsträger betrachtet, das seine Umgebung beobachtet — Fahrzeugdichte, Signalqualität, eigenen Batteriestand, Größe und Deadline jeder Aufgabe sowie die Auslastung der Roadside‑Units. Ein Lernagent wählt dann zwischen mehreren Optionen: lokal verarbeiten, die Aufgabe an eine von mehreren Roadside‑Units senden oder die Aufgabe sogar zwischen Auto und Roadside aufteilen. Nach jeder Entscheidung misst das System, wie lange die Aufgabe dauerte, wie viel Energie verbraucht wurde, ob sie vor Fristende abgeschlossen wurde, wie ausgeglichen die Nutzung der Roadside‑Units war und wie oft das Fahrzeug beim Fahren zwischen Roadside‑Units wechseln musste. Diese Ergebnisse werden in einen einzelnen Rückmeldungswert zusammengeführt, der den Lernagenten im Laufe der Zeit zu besseren Entscheidungen lenkt.
Aufbau eines realistischen Testfelds
Um zu prüfen, ob die gelernte Strategie in der Praxis funktioniert, bauten die Forschenden eine detaillierte Computersimulation mit dem ns‑3 Netzwerksimulator, gekoppelt an ein Reinforcement‑Learning‑Toolkit. Ihre virtuelle Stadt enthält Kreuzungen, sich bewegende Fahrzeuge mit unterschiedlichen Geschwindigkeiten und Roadside‑Units in einem Raster, sodass sich Abdeckungsbereiche überlappen wie bei einer realen Installation. Die Funkverbindungen folgen realistischen Modellen für offene Autobahnen und dichte städtische »Canyons«, in denen Gebäude Reflexionen und Signalverlust verursachen. Aufgaben unterschiedlicher Größe und mit verschiedenen Deadlines treffen auf jedes Fahrzeug, und die Roadside‑Rechner sind mit Warteschlangen und begrenzter Rechenleistung modelliert, sodass sie bei gleichzeitigen Offloads überlastet werden können. Zwei verbreitete Lernmethoden, Deep Q‑Networks und Soft Actor‑Critic, werden verwendet, um Entscheidungsrichtlinien über viele simulierte Fahrten und Kanalbedingungen zu trainieren.
Wie gut der Lernansatz abschneidet
Das Team verglich DRLO‑VANET mit drei gängigen Alternativen: immer an Bord verarbeiten, immer an die nächstgelegene Roadside‑Unit auslagern und eine »gierige« Strategie, die lediglich die aktuell geringste Verzögerung verfolgt, ohne vorauszuplanen. Bei geringem Verkehr schneiden alle Methoden akzeptabel ab, doch mit zunehmender Fahrzeugdichte treten die Schwächen der einfachen Regeln zutage. Das Offloading zur nächstgelegenen Unit führt zu Überlast bei einigen Roadside‑Rechnern und langen Warteschlangen. Die gierige Strategie minimiert zunächst die Verzögerung, zwingt Fahrzeuge jedoch zu häufigen Wechseln zwischen Roadside‑Units, was Overhead und Instabilität erzeugt. Im Gegensatz dazu verteilt die gelernte DRLO‑VANET‑Policy die Last gleichmäßiger, vermeidet eindeutig schlechte Funkverbindungen und begrenzt unnötige Handovers. In Simulationen reduziert sie die Aufgabendauer um bis zu etwa 40 Prozent, senkt den Energieverbrauch um 30–35 Prozent, hält bei mittlerem Verkehr über 90 Prozent der Aufgaben termingerecht und halbiert ungefär die Handovers im Vergleich zur gierigen Methode.
Was das für Alltagfahrende bedeutet
Für Nicht‑Spezialisten ist die wichtigste Erkenntnis, dass Autos und Infrastruktur viel intelligenter zusammenarbeiten können als heute. Statt starrer Regeln kann ein lernbasierter Controller beobachten, wie ausgelastet Straße und Netzwerk sind, und leise entscheiden, wo jede digitale Aufgabe ausgeführt werden soll, sodass Reaktionen schnell bleiben, Batterien länger halten und Straßeninfrastruktur nicht überlastet wird. Obwohl diese Studie auf Simulationen statt auf Realfahrzeugen basiert, weist sie auf eine Zukunft, in der das für autonomes Fahren notwendige »Denken« automatisch zwischen Fahrzeugen und nahegelegener Infrastruktur aufgeteilt wird, wodurch fortgeschrittene Sicherheits‑ und Navigationsdienste auch in dichtem, sich schnell änderndem Verkehr zuverlässiger werden.
Zitation: Neelima, S., Sree, S.R. & Ramakrishnaiah, N. DRLO-VANET: a deep reinforcement learning-based offloading framework for low-latency and energy-efficient task execution in VANETs. Sci Rep 16, 10582 (2026). https://doi.org/10.1038/s41598-026-46336-w
Schlüsselwörter: autonome Fahrzeuge, Edge‑Computing, Fahrzeugnetzwerke, Reinforcement Learning, Task‑Offloading