Clear Sky Science · ar
DRLO-VANET: إطار تفريغ مهام قائم على التعلم التعزيزي العميق لتنفيذ المهام منخفضة الكمون وموفّرة للطاقة في شبكات المركبات
لماذا تهم قدرة الحوسبة الأذكى في السيارات
أصبحت السيارات الحديثة، لا سيما ذاتية القيادة، أشبه بحواسيب متحركة. فهي تفسر باستمرار بيانات الكاميرات والرادار والخرائط ومعلومات المرور للحفاظ على سلامة الركاب وانسياب حركة المرور. لكن كل هذا المعالجة تتطلب وقتًا وطاقة. يمكن للسيارات اليوم إما أن تعالج البيانات محليًا على متنها أو ترسلها إلى حواسيب موضوعة على جوانب الطرق. الاختيار الخاطئ قد يؤدي إلى تأخيرات، فشل في تنفيذ المهام أو هدر في طاقة البطارية. تستكشف هذه الورقة طريقة جديدة لاتخاذ تلك الاختيارات تلقائيًا وبذكاء، باستخدام خوارزميات تعلم تتكيف مع ظروف المرور والشبكة في الزمن الحقيقي.
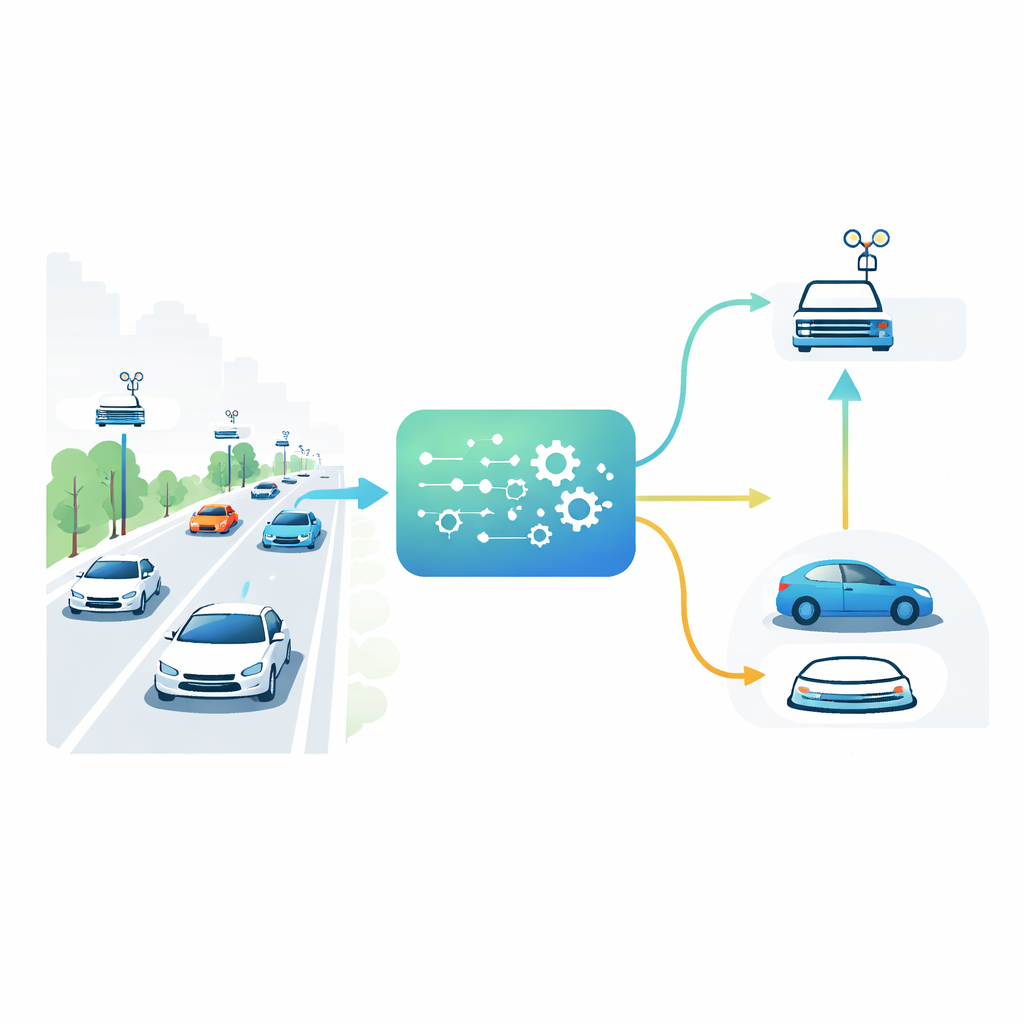
السيارات والطرق والمساعدون القريبون
في مدن المستقبل، لن تتواصل المركبات مع بعضها فحسب، بل ستتواصل أيضًا مع حواسيب صغيرة مدمجة في وحدات على جوانب الطرق. تعمل هذه الوحدات كأنها مراكز بيانات محلية صغيرة، أقرب بكثير من خوادم السحابة البعيدة. قد تضطر سيارة تقترب من تقاطع إلى تنفيذ مهمةٍ متطلبة، مثل دمج بيانات الكاميرا والحساسات لاكتشاف المشاة الخفيين. يمكنها أن تعالج تلك المهمة بمعالجها المحدود أو تفوّضها إلى إحدى وحدات جانب الطريق. يعتمد الاختيار الأفضل على مدى ازدحام الطريق، مدى انشغال كل حاسوب جانب طريق، قوة الإشارة اللاسلكية وأهمية المهلة الزمنية للمهمة. وبما أن كل هذه العوامل تتغير ثانيةً بعد ثانية، تنهار القواعد الثابتة — مثل الاعتماد دائمًا على أقرب وحدة — في ظل حركة المرور الحقيقية.
السماح للنظام بتعلّم القرارات بنفسه
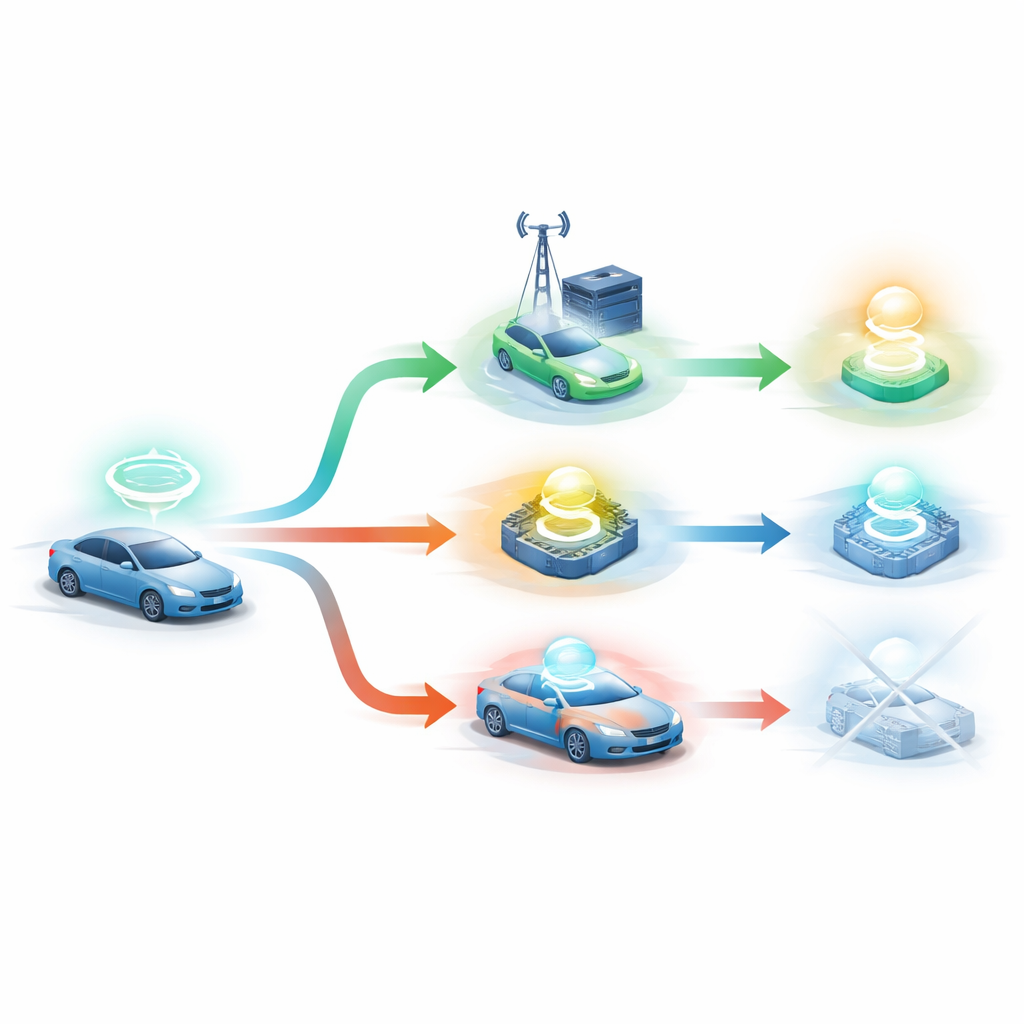
يقترح المؤلفون DRLO-VANET، إطارًا يسمح للنظام بتعلّم قرارات جيدة بالتجربة والخطأ بدلًا من الاعتماد على قواعد مصاغة يدويًا. في إعدادهم، تُعامل كل مركبة كصانع قرار يراقب محيطه — كثافة المركبات، جودة الإشارة، مستوى بطاريته، حجم ومهلة كل مهمة، ومدى حمل وحدات جانب الطريق. ثم يختار وكيل تعلم من بين عدة خيارات: المعالجة محليًا، إرسال المهمة إلى إحدى وحدات جانب الطريق، أو حتى تقسيم العمل بين السيارة ووحدة جانب الطريق. بعد كل قرار، يقيس النظام مدة تنفيذ المهمة، وطاقة الاستهلاك، وما إذا كانت انتهت قبل مهلتها، ومدى توازن استخدام وحدات جانب الطريق وعدد مرات تبديل السيارة من وحدة لأخرى أثناء حركتها. تُدمج هذه النتائج في مقياس تغذية راجعة واحد يدفع وكيل التعلم نحو قرارات أفضل مع مرور الوقت.
بناء بيئة اختبار واقعية
لتقييم ما إذا كانت الاستراتيجية المتعلمة تعمل عمليًا، بنى الباحثون محاكاة حاسوبية مفصّلة باستخدام محاكي الشبكات ns-3 المرتبط بأدوات تعلم تعزيزي. تشمل مدينتهم الافتراضية تقاطعات طرق، مركبات متحركة بسرعات مختلفة، ووحدات جانب طريق موضوعة في شبكة بحيث تتداخل مناطق التغطية كما في نشر فعلي. تتبع الروابط اللاسلكية نماذج واقعية للطرق السريعة المفتوحة و«الأودية» الحضرية الكثيفة حيث تسبب المباني انعكاسات وخسارة إشارة. تصل إلى كل مركبة مهام بأحجام ومهلات زمنية مختلفة، ويتم نمذجة حواسيب جانب الطريق على شكل قوائم انتظار وقدرات معالجة محدودة، لذا يمكن أن تتكدّس عند تفريغ العديد من السيارات في وقت واحد. تُستخدم طريقتان شائعتان في التعلم، شبكات Q العميقة وSoft Actor-Critic، لتدريب سياسات اتخاذ القرار عبر العديد من الرحلات والمحطات القنوية المحاكاة.
مدى أداء نهج التعلم
قارن الفريق DRLO-VANET بثلاث بدائل شائعة: المعالجة دائمًا على اللوحة، التفريغ دائمًا إلى أقرب وحدة جانب طريق واستراتيجية «جشعة» تتبع أقل تأخير فوري دون التفكير للمستقبل. في حركة خفيفة، تعمل جميع الطرق بشكل معقول، لكن مع دخول مزيد من السيارات إلى الشبكة تُظهِر القواعد البسيطة نقاط ضعفها. يؤدي التفريغ إلى أقرب وحدة إلى تحميل بعض وحدات جانب الطريق بشكل مفرط، مسببًا قوائم انتظار طويلة. تقلل الاستراتيجية الجشعة التأخير في البداية لكنها تجبر المركبات على التبديل تكراريًا بين وحدات جانب الطريق، مما يضيف حملًا وعدم استقرار. بالمقابل، توزّع سياسة DRLO-VANET المتعلمة الحمولة بشكل أكثر توازنًا، تتجنب روابط لاسلكية سيئة بوضوح وتحد من التبديلات غير الضرورية. في المحاكاة، تقلل من تأخير المهام بنحو يصل إلى 40%، وتخفض استهلاك الطاقة بنسبة 30–35%، وتحافظ على أكثر من 90% من المهام ضمن المهل في حركة متوسطة، وتقلّص أحداث التبديل بنحو النصف مقارنة بالأسلوب الجشع.
ماذا يعني هذا للسائقين العاديين
بالنسبة لغير المتخصصين، الخلاصة أن السيارات والطرق يمكن أن تتعاون بذكاء أكبر مما هي عليه اليوم. بدلًا من قواعد جامدة، يمكن لمتحكم مبني على التعلم أن يرصد مدى انشغال الطريق والشبكة ويختار بهدوء أين تُنفَّذ كل مهمة رقمية بحيث تبقى الاستجابات سريعة، وتدوم البطاريات أطول ولا تُثَقّل معدات جانب الطريق. وعلى الرغم من أن هذه الدراسة مبنية على محاكاة وليست على سيارات حقيقية، فإنها تشير إلى مستقبل يُقسَّم فيه "التفكير" اللازم للقيادة الذاتية تلقائيًا بين المركبات والبنية التحتية القريبة، مما يجعل خدمات السلامة والملاحة المتقدمة أكثر موثوقية حتى في حركة مزدحمة ومتغيرة بسرعة.
الاستشهاد: Neelima, S., Sree, S.R. & Ramakrishnaiah, N. DRLO-VANET: a deep reinforcement learning-based offloading framework for low-latency and energy-efficient task execution in VANETs. Sci Rep 16, 10582 (2026). https://doi.org/10.1038/s41598-026-46336-w
الكلمات المفتاحية: المركبات الذاتية, الحوسبة على الحافة, شبكات المركبات, التعلم التعزيزي, تفريغ المهام