Clear Sky Science · ru
DRLO-VANET: фреймворк для отгрузки задач на базе глубокого обучения с подкреплением для низкой задержки и энергоэффективного выполнения задач в VANET
Почему важно умное вычисление в автомобилях
Современные автомобили, особенно автономные, становятся движущимися компьютерами. Они постоянно анализируют видеопотоки, радар, карты и информацию о трафике, чтобы обеспечить безопасность пассажиров и поддерживать движение. Но все эти вычисления требуют времени и энергии. Сегодняшние машины могут либо обрабатывать данные локально, либо отправлять их на ближайшие дорожные вычислительные узлы. Неправильный выбор может привести к задержкам, сброшенным задачам или ненужной трате энергии батареи. В этой статье рассматривается новый подход к автоматическому и интеллектуальному принятию таких решений с помощью алгоритмов, которые адаптируются к условиям трафика и сети в реальном времени.
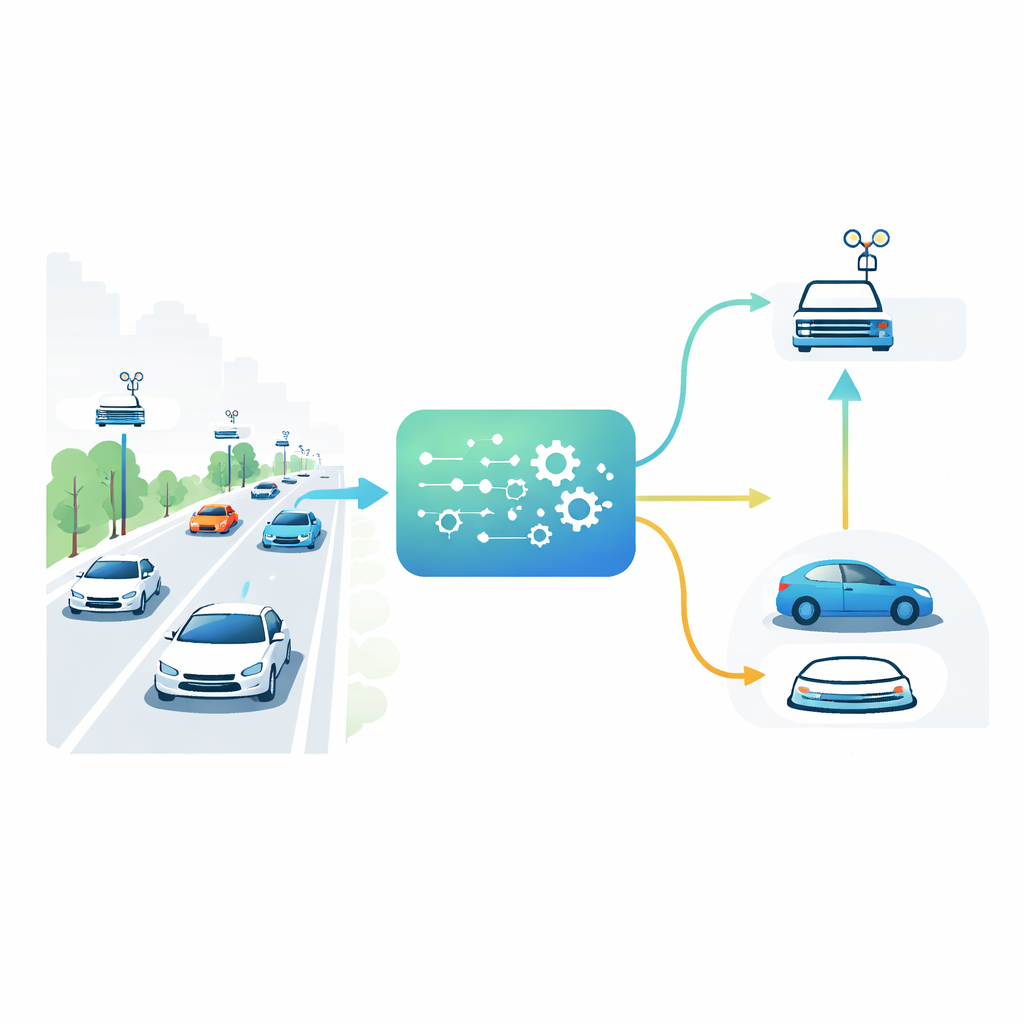
Автомобили, дороги и локальные помощники
В городах будущего транспортные средства будут не только обмениваться данными друг с другом, но и взаимодействовать с небольшими вычислительными узлами, встроенными в дорожную инфраструктуру. Эти узлы функционируют как локальные мини‑центры обработки данных, гораздо ближе, чем отдалённые облачные серверы. Подъезжающий к перекрёстку автомобиль может столкнуться с требовательной задачей, например, объединить данные с камер и датчиков для обнаружения скрытых пешеходов. Он может либо обработать задачу на собственном ограниченном процессоре, либо отдать её одному из дорожных узлов. Лучший выбор зависит от плотности движения, загрузки каждого дорожного компьютера, качества беспроводного сигнала и срочности задачи. Поскольку все эти параметры меняются каждую секунду, статические правила — например, всегда использовать ближайший узел — в реальном трафике быстро теряют эффективность.
Дать системе учиться самостоятельно
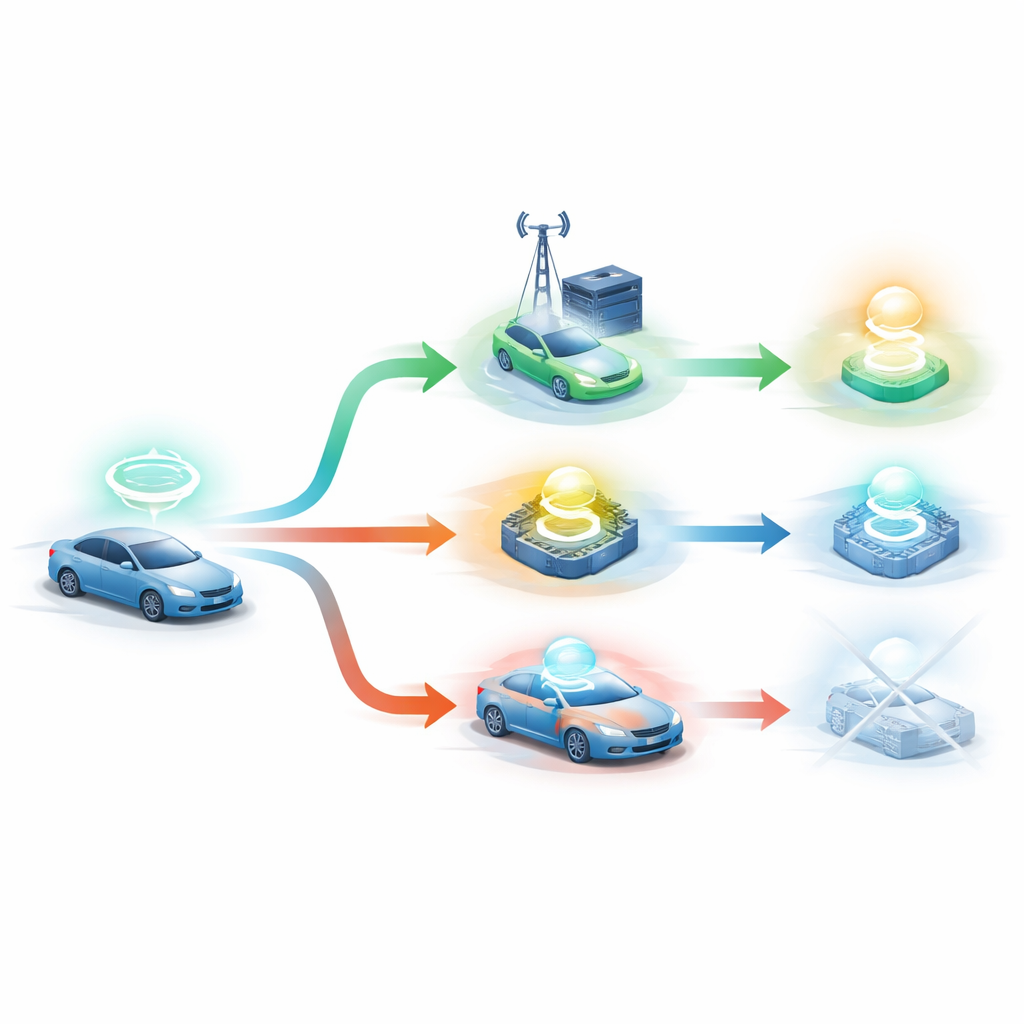
Авторы предлагают DRLO-VANET — фреймворк, который позволяет системе обучаться хорошим решениям методом проб и ошибок вместо опоры на вручную созданные правила. В их модели каждый автомобиль рассматривается как принимающий решения агент, который наблюдает за окружением: плотностью машин, качеством сигнала, уровнем батареи, размером и сроком выполнения каждой задачи, а также загрузкой дорожных узлов. Агент выбирает из нескольких вариантов: обработать локально, отправить задачу в один из дорожных узлов или даже разделить работу между автомобилем и инфраструктурой. После каждого решения система измеряет время выполнения задачи, потреблённую энергию, укладывалась ли задача в срок, насколько равномерно распределялась нагрузка по дорожным узлам и сколько раз автомобиль менял подключение с одного узла на другой в движении. Эти показатели объединяются в единый сигнал обратной связи, который со временем направляет агент к более удачным решениям.
Создание реалистичной испытательной среды
Чтобы проверить, сработает ли обученная стратегия на практике, исследователи построили детализированную компьютерную симуляцию, используя сетевой симулятор ns-3 в связке с инструментарием для обучения с подкреплением. Их виртуальный город включает пересекающиеся дороги, движущиеся автомобили с разными скоростями и дорожные узлы, размещённые в сетке так, чтобы зоны покрытия перекрывались, как в реальной развертке. Беспроводные каналы моделируются реалистично для открытых шоссе и плотных городских «ущелий», где здания вызывают отражения и потери сигнала. На каждом автомобиле появляются задачи разного размера и срока выполнения, а дорожные вычислители моделируются с очередями и ограниченной вычислительной мощностью, поэтому они могут перегружаться при массовой отгрузке. Для обучения политик решений применяются две популярные методики: Deep Q-Networks и Soft Actor-Critic, тренируемые на множестве симулированных поездок и условий каналов.
Насколько эффективно обучение
Команда сравнила DRLO-VANET с тремя распространёнными альтернативами: всегда обрабатывать локально, всегда отгружать в ближайший дорожный узел и «жадную» стратегию, которая преследует минимальную немедленную задержку без учёта последствий. При небольшом трафике все методы работают приемлемо, но по мере роста числа автомобилей недостатки простых правил становятся очевидны. Отгрузка в ближайший узел перегружает небольшое число дорожных компьютеров, что приводит к длинным очередям. Жадная стратегия сначала минимизирует задержку, но заставляет автомобили часто переключаться между узлами, добавляя накладные расходы и нестабильность. В отличие от них, обученная политика DRLO-VANET более равномерно распределяет нагрузку, избегает явно плохих беспроводных ссылок и ограничивает лишние передачи между узлами. В симуляциях она сокращает задержку выполнения задач примерно до 40%, уменьшает потребление энергии на 30–35%, обеспечивает своевременное выполнение более 90% задач при среднем трафике и примерно вдвое снижает число хэндоверов по сравнению с жадной стратегией.
Что это значит для обычных водителей
Для широкой аудитории ключевая идея такова: автомобили и дорожная инфраструктура могут сотрудничать намного разумнее, чем сегодня. Вместо жёстких правил контроллер на основе обучения может отслеживать, насколько загружены дорога и сеть, и незаметно выбирать, где выполнять каждую цифровую задачу, чтобы ответы оставались быстрыми, батареи служили дольше, а оборудование на обочине не перегружалось. Хотя исследование основано на симуляции, а не на реальных автомобилях, оно указывает на будущее, в котором «мышление», необходимое для автономного вождения, автоматически распределяется между транспортными средствами и близлежащей инфраструктурой, делая продвинутые сервисы безопасности и навигации более надёжными даже в плотном и быстро меняющемся трафике.
Цитирование: Neelima, S., Sree, S.R. & Ramakrishnaiah, N. DRLO-VANET: a deep reinforcement learning-based offloading framework for low-latency and energy-efficient task execution in VANETs. Sci Rep 16, 10582 (2026). https://doi.org/10.1038/s41598-026-46336-w
Ключевые слова: автономные транспортные средства, edge-вычисления, транспортные сети, обучение с подкреплением, отгрузка задач