Clear Sky Science · en
DRLO-VANET: a deep reinforcement learning-based offloading framework for low-latency and energy-efficient task execution in VANETs
Why Smarter Car Computing Matters
Modern cars, especially self-driving ones, are becoming rolling computers. They constantly interpret camera feeds, radar, maps and traffic information in order to keep passengers safe and traffic flowing. But all this thinking takes time and energy. Today’s cars can either crunch the numbers on-board or send them to nearby roadside computers. Choosing wrong can mean delays, dropped tasks or wasted battery power. This paper explores a new way to make those choices automatically and intelligently, using learning algorithms that adapt to traffic and network conditions in real time.
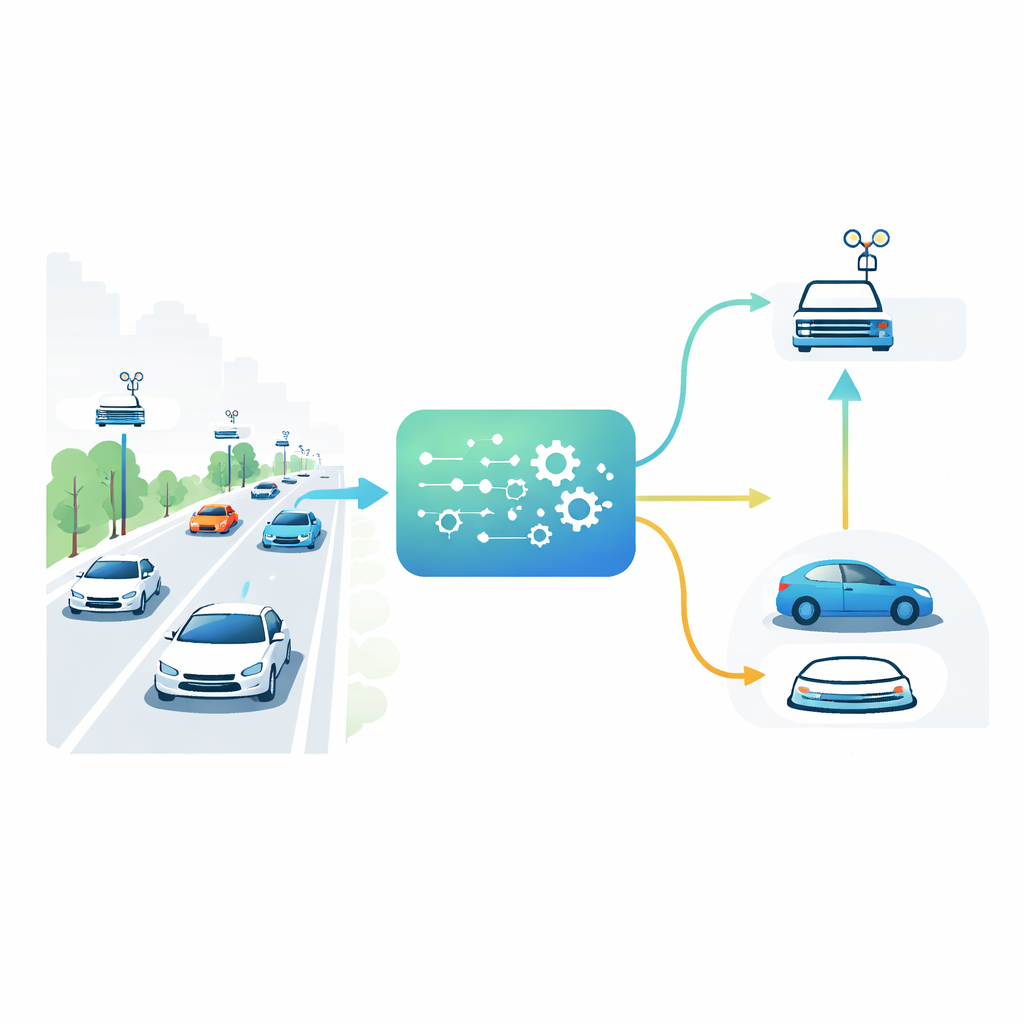
Cars, Roads and Nearby Helpers
In future cities, vehicles will not only talk to each other but also to small computers built into roadside units along the streets. These roadside units act like local mini–data centers, much closer than distant cloud servers. A car approaching an intersection might have to run a demanding task, such as combining camera and sensor data to detect hidden pedestrians. It can either process that task on its own limited processor or offload it to one of the roadside units. The best choice depends on how crowded the road is, how busy each roadside computer is, how strong the wireless signal is and how urgent the task is. Because all of these conditions shift second by second, static rules—like always using the nearest roadside unit—break down under real traffic.
Letting the System Learn on Its Own
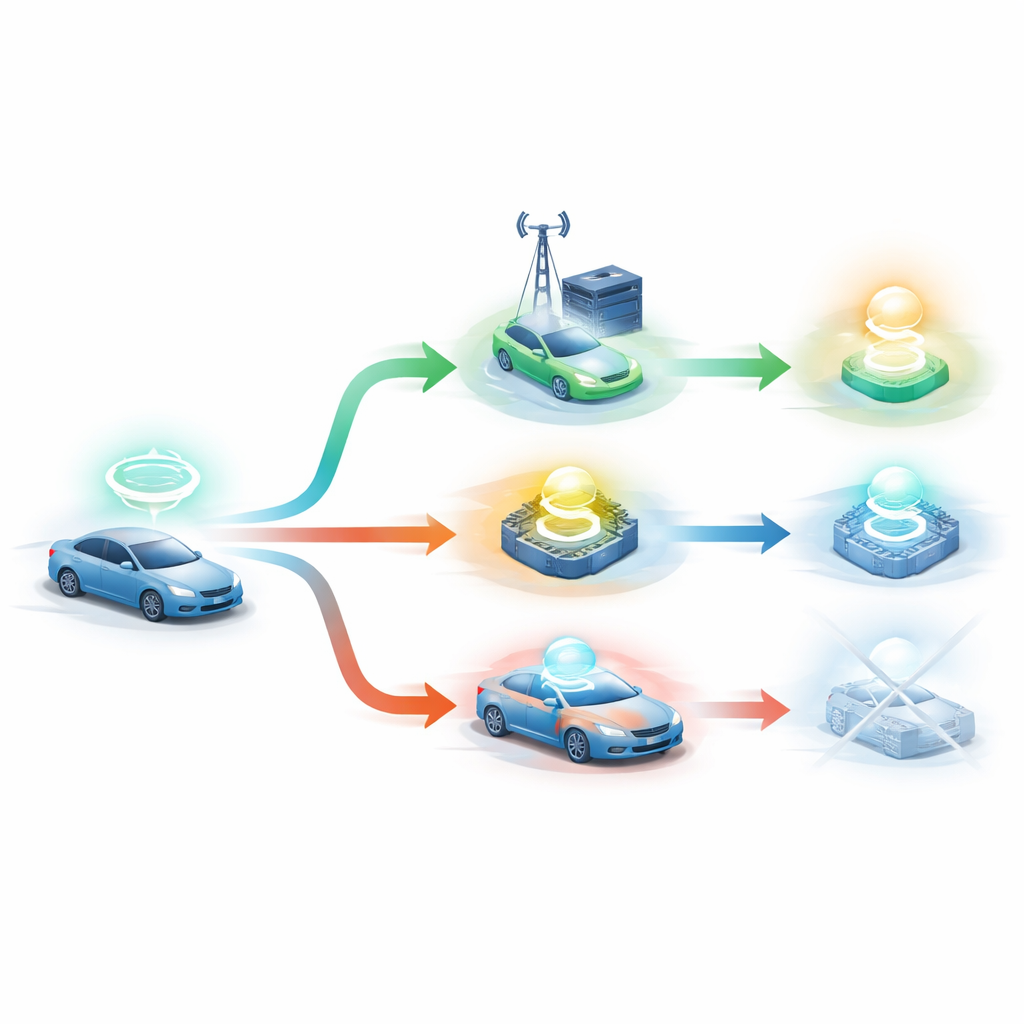
The authors propose DRLO-VANET, a framework that lets the system learn good decisions by trial and error instead of relying on hand-crafted rules. In their setup, each vehicle is treated as a decision-maker that observes its surroundings—vehicle density, signal quality, its own battery level, the size and deadline of each task, and how loaded the roadside units are. A learning agent then chooses among several options: process locally, send the task to one of several roadside units, or even split the job between car and roadside. After each decision, the system measures how long the task took, how much energy it consumed, whether it finished before its deadline, how balanced the roadside usage was and how many times the car had to switch from one roadside unit to another while moving. These outcomes are folded into a single feedback score that nudges the learning agent toward better choices over time.
Building a Realistic Test Playground
To judge whether the learned strategy would work in practice, the researchers built a detailed computer simulation using the ns-3 network simulator linked to a reinforcement learning toolkit. Their virtual city includes crossing roads, moving vehicles with different speeds, and roadside units placed in a grid so that coverage areas overlap as in a real deployment. The wireless links follow realistic models for open highways and dense urban “canyons,” where buildings cause reflections and signal loss. Tasks of different sizes and deadlines arrive on each vehicle, and the roadside computers are modeled with queues and limited processing power, so they can become congested when many cars offload at once. Two popular learning methods, Deep Q-Networks and Soft Actor-Critic, are used to train decision policies over many simulated drives and channel conditions.
How Well the Learning Approach Performs
The team compared DRLO-VANET with three common alternatives: always processing on-board, always offloading to the nearest roadside unit and a “greedy” strategy that chases the lowest immediate delay without thinking ahead. In light traffic, all methods perform reasonably, but as more cars enter the network the weaknesses of the simple rules are exposed. Nearest-unit offloading overloads a few roadside computers, causing long queues. The greedy strategy minimizes delay at first but forces vehicles to switch repeatedly between roadside units, adding overhead and instability. By contrast, the learned DRLO-VANET policy spreads the load more evenly, avoids clearly bad wireless links and limits unnecessary handovers. In simulations, it cuts task delay by up to about 40 percent, lowers energy use by 30–35 percent, keeps more than 90 percent of tasks on time at medium traffic and roughly halves handover events compared with the greedy method.
What This Means for Everyday Drivers
For non-specialists, the key takeaway is that cars and roads can cooperate much more intelligently than they do today. Instead of rigid rules, a learning-based controller can watch how busy the road and the network are and quietly choose where each digital task should run so that responses stay quick, batteries last longer and roadside equipment is not overwhelmed. Although this study is based on simulation rather than real cars, it points toward a future in which the "thinking" needed for autonomous driving is automatically split between vehicles and nearby infrastructure, making advanced safety and navigation services more reliable even in crowded, fast-changing traffic.
Citation: Neelima, S., Sree, S.R. & Ramakrishnaiah, N. DRLO-VANET: a deep reinforcement learning-based offloading framework for low-latency and energy-efficient task execution in VANETs. Sci Rep 16, 10582 (2026). https://doi.org/10.1038/s41598-026-46336-w
Keywords: autonomous vehicles, edge computing, vehicular networks, reinforcement learning, task offloading