Clear Sky Science · it
DRLO-VANET: un framework di offloading basato su deep reinforcement learning per l’esecuzione di compiti a bassa latenza e a basso consumo energetico nelle VANET
Perché il calcolo più intelligente nelle auto conta
Le automobili moderne, in particolare quelle a guida autonoma, stanno diventando dei computer su ruote. Interpretano continuamente flussi video, radar, mappe e informazioni sul traffico per mantenere i passeggeri al sicuro e il traffico fluido. Ma tutto questo elaborare richiede tempo ed energia. Oggi le auto possono elaborare i dati a bordo o inviarli a computer stradali nelle vicinanze. Scegliere male può significare ritardi, compiti scaduti o spreco di batteria. Questo articolo esplora un nuovo modo per prendere queste decisioni automaticamente e in modo intelligente, usando algoritmi di apprendimento che si adattano in tempo reale alle condizioni del traffico e della rete.
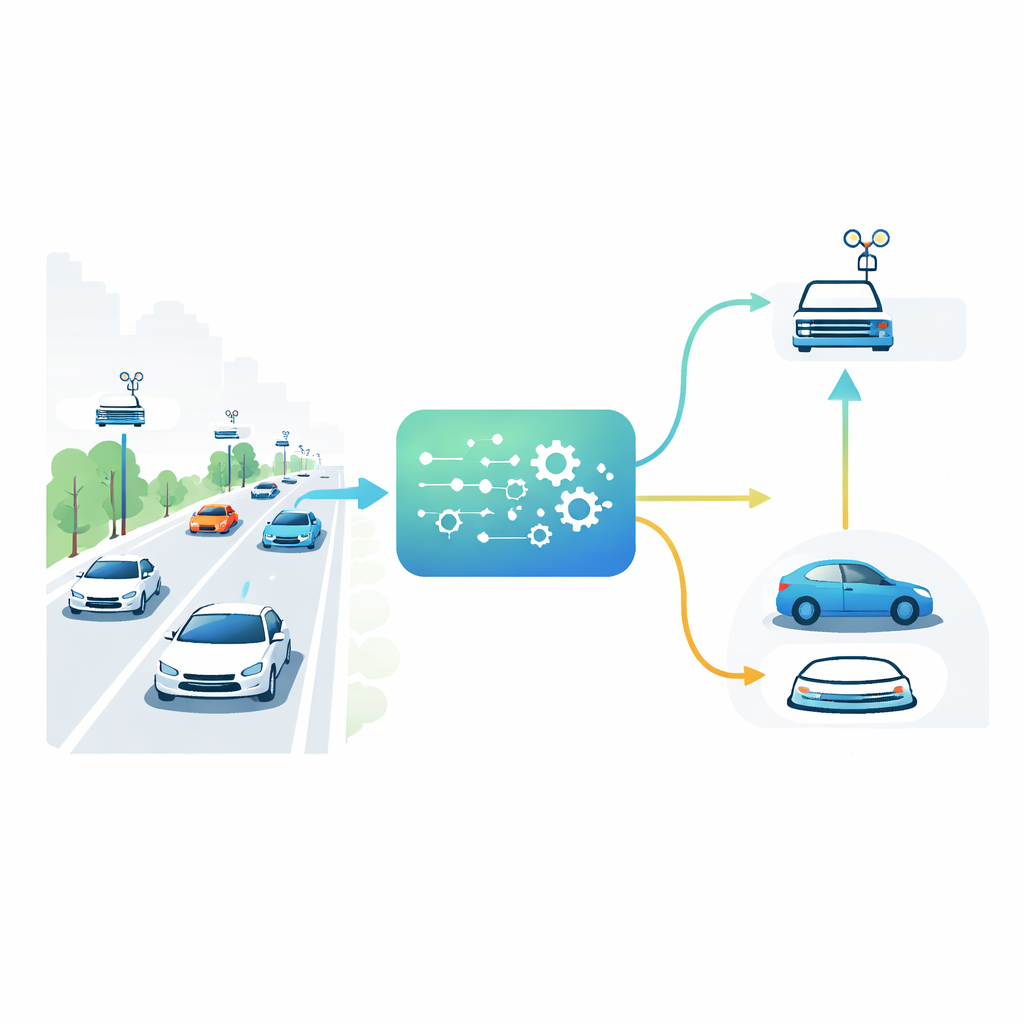
Auto, strade e helper nelle vicinanze
Nelle città del futuro i veicoli non solo parleranno tra loro ma anche con piccoli computer integrati in unità stradali lungo le vie. Queste unità agiscono come mini-data center locali, molto più vicine dei server cloud remoti. Un’auto che si avvicina a un’incrocio potrebbe dover eseguire un compito oneroso, come combinare dati da telecamere e sensori per rilevare pedoni nascosti. Può elaborare quel compito sul processore limitato a bordo o scaricarlo su una delle unità stradali. La scelta migliore dipende da quanto è affollata la strada, da quanto sono cariche le singole unità stradali, dalla qualità del segnale wireless e dall’urgenza del compito. Poiché tutte queste condizioni cambiano di secondo in secondo, regole statiche — per esempio usare sempre l’unità stradale più vicina — falliscono nel traffico reale.
Lasciare che il sistema impari da solo
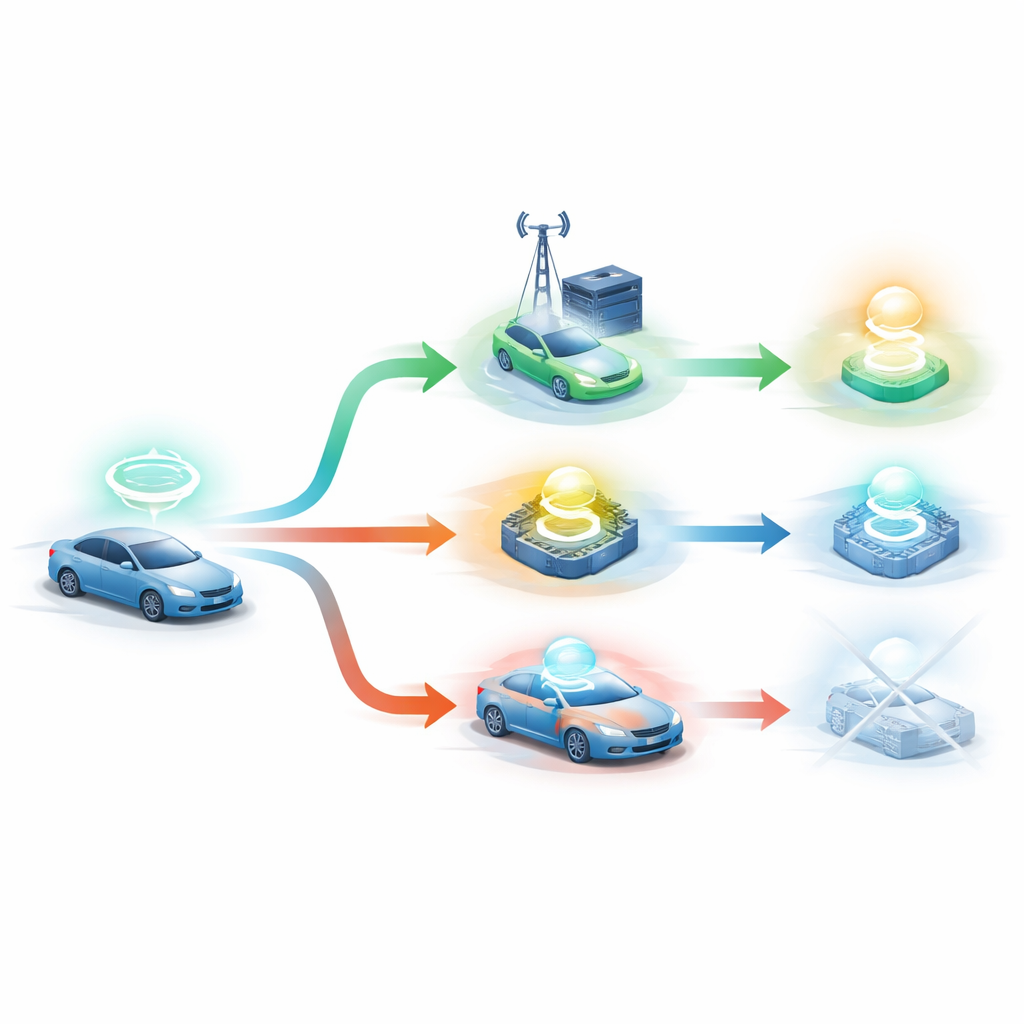
Gli autori propongono DRLO-VANET, un framework che permette al sistema di apprendere buone decisioni per tentativi ed errori invece di basarsi su regole fatte a mano. Nel loro approccio ogni veicolo è trattato come un decisore che osserva l’intorno — densità di veicoli, qualità del segnale, livello di batteria, dimensione e deadline dei compiti, e quanto sono cariche le unità stradali. Un agente di apprendimento sceglie quindi tra diverse opzioni: processare localmente, inviare il compito a una delle unità stradali, o perfino dividere il lavoro tra auto e unità stradale. Dopo ogni decisione il sistema misura quanto tempo ha impiegato il compito, quanta energia ha consumato, se è stato completato entro la deadline, quanto è stato bilanciato l’utilizzo delle unità stradali e quante volte l’auto ha dovuto cambiare unità stradale durante il movimento. Questi risultati sono combinati in un unico punteggio di feedback che spinge l’agente di apprendimento verso scelte migliori nel tempo.
Costruire un banco di prova realistico
Per valutare se la strategia appresa funzionerebbe nella pratica, i ricercatori hanno costruito una simulazione dettagliata collegando il simulatore di rete ns-3 a un toolkit di reinforcement learning. La loro città virtuale include strade che si incrociano, veicoli in movimento a velocità diverse e unità stradali disposte a griglia in modo che le aree di copertura si sovrappongano come in un’installazione reale. I collegamenti wireless seguono modelli realistici per autostrade aperte e “canyon” urbani densi, dove gli edifici provocano riflessioni e perdita di segnale. Su ogni veicolo arrivano compiti di dimensioni e deadline differenti, e i computer stradali sono modellati con code e capacità di elaborazione limitata, così da poter diventare congestionati quando molte auto effettuano offload contemporaneamente. Due metodi di apprendimento diffusi, Deep Q-Networks e Soft Actor-Critic, sono usati per addestrare politiche decisionali su molte guide simulate e condizioni dei canali.
Quanto bene funziona l’approccio di apprendimento
Il team ha confrontato DRLO-VANET con tre alternative comuni: elaborare sempre a bordo, scaricare sempre sull’unità stradale più vicina e una strategia “greedy” che insegue il ritardo immediato più basso senza pensare al futuro. In traffico scarso tutti i metodi si comportano in modo accettabile, ma con l’aumentare delle auto nella rete emergono le debolezze delle regole semplici. L’offload verso l’unità più vicina sovraccarica poche unità stradali, causando lunghe code. La strategia greedy minimizza inizialmente il ritardo ma costringe i veicoli a cambiare ripetutamente unità stradali, aggiungendo overhead e instabilità. Al contrario, la politica appresa da DRLO-VANET distribuisce il carico in modo più uniforme, evita chiaramente i link wireless svantaggiosi e limita i handover non necessari. Nelle simulazioni riduce il ritardo dei compiti fino a circa il 40%, abbassa il consumo energetico del 30–35%, mantiene più del 90% dei compiti in tempo a traffico medio e dimezza approssimativamente gli eventi di handover rispetto al metodo greedy.
Cosa significa per gli automobilisti di tutti i giorni
Per i non specialisti, la conclusione fondamentale è che auto e infrastrutture stradali possono cooperare in modo molto più intelligente rispetto a oggi. Invece di regole rigide, un controllore basato sull’apprendimento può osservare quanto sono occupati la strada e la rete e scegliere silenziosamente dove deve essere eseguito ciascun compito digitale in modo che le risposte restino rapide, le batterie durino più a lungo e le apparecchiature stradali non vengano sovraccaricate. Sebbene questo studio sia basato su simulazioni piuttosto che su auto reali, indica verso un futuro in cui il “pensiero” necessario per la guida autonoma viene automaticamente diviso tra i veicoli e l’infrastruttura vicina, rendendo servizi avanzati di sicurezza e navigazione più affidabili anche nel traffico affollato e in rapido cambiamento.
Citazione: Neelima, S., Sree, S.R. & Ramakrishnaiah, N. DRLO-VANET: a deep reinforcement learning-based offloading framework for low-latency and energy-efficient task execution in VANETs. Sci Rep 16, 10582 (2026). https://doi.org/10.1038/s41598-026-46336-w
Parole chiave: veicoli autonomi, edge computing, reti veicolari, reinforcement learning, offloading di compiti