Clear Sky Science · tr
Ayırıcı TF-IDF inanç kural tabanına dayalı bir spam tespit modeli
Neden daha akıllı spam filtreleri herkes için önemli
Gelen kutularımız sahte ürün satmaya, şifreleri çalmaya veya para göndertmeye çalışan gereksiz mesajlarla dolu. En tehlikeli spam dalgaları genellikle yeni ve farklı görünür; şirketlerin geleneksel tespit araçlarını eğitmek için yeterli örnek toplamadan önce ortaya çıkarlar. Bu makale, az sayıda şüpheli mesaj görüldüğünde bile iyi çalışabilen ve bir mesajı neden spam veya güvenli olarak işaretlediğini açıkça açıklayan yeni bir tür spam filtresini tanıtıyor.
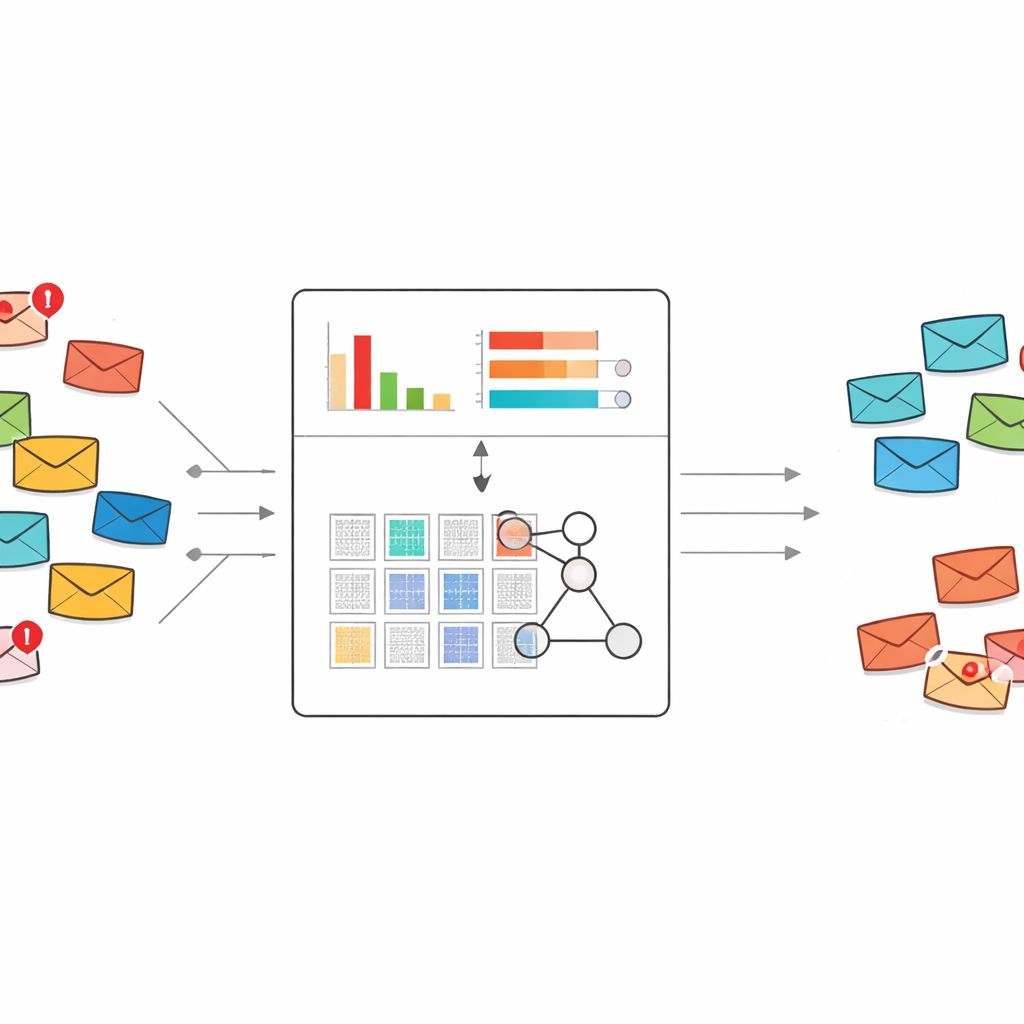
Spammerlerin ne dediğini okumaya yeni bir yaklaşım
Bugün çoğu spam filtresi ya standart makine öğrenmesi ya da derin öğrenmeye dayanıyor. Bu sistemler genellikle öğrenmek için binlerce veya milyonlarca etiketli e-posta ve büyük kelime özellik listeleri gerektirir. Güçlü olabilirler, ancak yeni bir dolandırıcılık türü ortaya çıktığında ve yalnızca birkaç örnek mevcutsa sık sık zorlanır veya kara kutu gibi davranırlar. Yazarlar bunun yerine bilginin insan tarafından okunabilir "eğer–ise" kuralları olarak temsil edildiği ve küçük veri kümelerinden öğrenmeye doğal olarak uygun olan bir uzman sistem çerçevesi olan inanç kural tabanına dayanıyorlar.
Gerçekte spam olduğunu gösteren kelimeleri seçmek
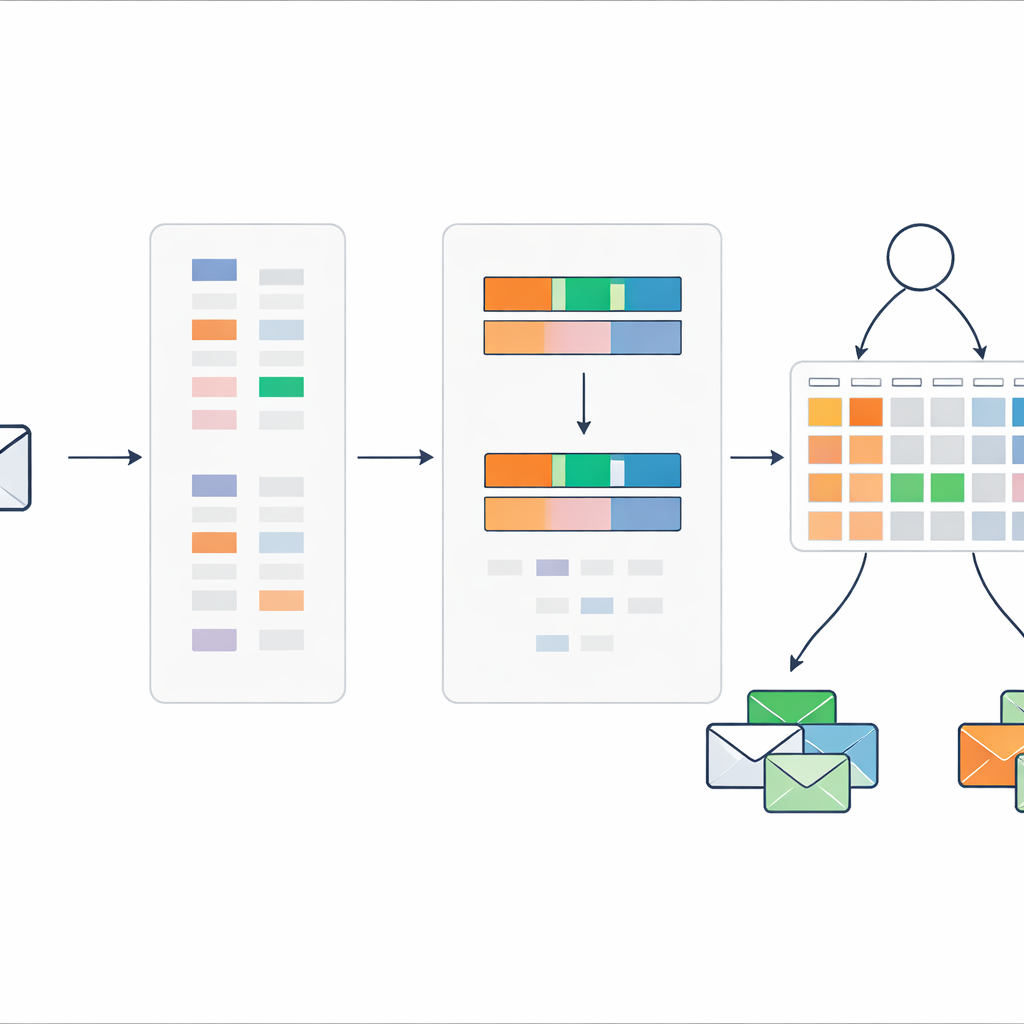
Doğrudan bir zorluk, ham e-posta metninin muazzam sayıda olası kelime ve ifade içermesidir. Tüm bunları bir kural sistemine vermek yönetilemez sayıda kurala yol açar. Bunu önlemek için yazarlar, klasik bir metin ağırlıklandırma şeması olan TF–IDF'yi, bir kelimenin bir belge için ne kadar önemli olduğunu yakalamakla kalmayıp aynı zamanda bunun spam yerine normal posta lehine mi yoksa spam lehine mi eğildiğini de gösterir şekilde yeniden tasarlıyorlar. Onların "ayırıcı TF–IDF" yöntemi önce sadece spam mesajlarına odaklanarak belirleyici kelime ve kısa ifadelerden oluşan bir kelime hazinesi oluşturuyor. Ardından her terimi spamde mi yoksa normal postada mı daha sık göründüğüne göre puanlıyor ve açıkça spam eğilimli olanları tutuyor.
Her mesajı iki basit sinyale indirgemek
Yüzlerce veya binlerce kelime göstergesini kural sistemine vermek yerine yöntem, her mesajı yalnızca iki sayıya sıkıştırıyor. İlki, o mesajdaki spam-eğilimli kelimelerin ne kadar güçlü şekilde tehlike işaret ettiğini toplayan genel bir spam puanı. İkincisi, mesajdaki kelimelerin ne kadarının şüpheli kelime hazinesinden geldiğini ölçen bir spam anahtar kelime yoğunluğu. Bu iki değer sıfır ile bir arasında ölçekleniyor ve farklı puan kombinasyonlarının nasıl spam veya güvenli posta olarak yorumlanması gerektiğini ve buna bağlı inanç derecelerini tanımlayan kompakt bir kural kümesinin tek girdileri olarak kullanılıyor.
Uyum sağlayan ama anlaşılabilir kalan kurallar
Kural sistemi uzman bilgisinden başlıyor: örneğin hem yüksek bir spam puanına hem de yüksek bir spam anahtar kelime yoğunluğuna sahip bir mesaj neredeyse kesinlikle spam olmalıdır; çelişkili sinyaller ise daha temkinli yargılar gerektirir. Bu başlangıç ayarlarını ince ayar yapmak için yazarlar, mantıksal kısıtları korurken kural ağırlıklarını ve inanç değerlerini otomatik olarak ayarlayan evrimsel bir optimizasyon prosedürü kullanıyorlar. Bu, modelin şeffaf, kural tabanlı yapısını kaybetmeden gerçek veri üzerinde kendini ayarlamasını sağlıyor. Her nihai karar hâlâ küçük bir insan tarafından okunabilir kural ve giriş puanları setine geri izlenebilir.
Gerçek dünya mesajlarında yaklaşımı kanıtlamak
Araştırma ekibi modelini iki halka açık veri setinde test ediyor: yaygın olarak kullanılan bir SMS metin mesajı koleksiyonu ve ayrı bir sahte e-posta seti. Her iki durumda da yeni bir spam salgınının erken aşamasını taklit etmek için kendilerini yalnızca 200 etiketli örnekle sınırlıyorlar—100 spam ve 100 normal mesaj. Çoklu çapraz doğrulama turlarında, modelleri SMS'te yaklaşık %91,5, sahte e-postalarda ise %95,5 doğruluk elde ediyor ve aynı düşük veri koşulları altında test edilen çeşitli geleneksel makine öğrenmesi, derin öğrenme ve bulanık mantık sistemlerini geride bırakıyor. Yeni özellik puanlama yöntemi de vazgeçilmez olduğunu kanıtlıyor: bir eksiltme çalışmasında kaldırıldığında, kural yapısı aynı kalsa bile performans belirgin biçimde düşüyor.
Bu, daha güvenli gelen kutuları için ne anlama geliyor
Uzman olmayanlar için ana sonuç, çok az etiketli veriye sahipken bile iyi çalışan ve insanların anlayabileceği şekilde "yaptığını gösteren" bir spam filtresi oluşturmanın mümkün olduğu. Karmaşık metni yalnızca iki anlamlı sinyale indirgedikten sonra denetlenip iyileştirilebilen kompakt bir kural sistemi uygulayarak önerilen model, yeni spamlara karşı güçlü erken tespit ve kararları için net açıklamalar sunuyor. Pratik anlamda bu, e-posta sağlayıcılarının ve güvenlik ekiplerinin ortaya çıkan dolandırıcılık kampanyalarına daha hızlı tepki vermesine, şeffaf olmayan kara kutu modellere aşırı bağımlılığı azaltmasına ve uzmanlara spam taktiklerinin nasıl evrildiğine dair daha net içgörüler sağlamasına yardımcı olabilir.
Atıf: Yang, X., Zhou, W., Duan, X. et al. A spam detection model based on the discriminative TF-IDF belief rule base. Sci Rep 16, 11962 (2026). https://doi.org/10.1038/s41598-026-42223-6
Anahtar kelimeler: spam tespiti, e-posta güvenliği, metin sınıflandırma, anlaşılabilir yapay zeka, küçük örnekle öğrenme