Clear Sky Science · es
Un modelo de detección de spam basado en la base de reglas de creencia TF-IDF discriminativa
Por qué los filtros de spam más inteligentes importan a todos
Nuestros buzones se llenan de mensajes basura que intentan vender productos falsos, robar contraseñas o engañarnos para que enviemos dinero. Las oleadas de spam más peligrosas suelen parecer nuevas y distintas, llegando antes de que las empresas hayan recopilado suficientes ejemplos para entrenar las herramientas de detección tradicionales. Este artículo presenta un nuevo tipo de filtro de spam que puede funcionar bien incluso cuando solo se han visto un número reducido de mensajes sospechosos, y que además explica con claridad por qué marca un mensaje como spam o como seguro.
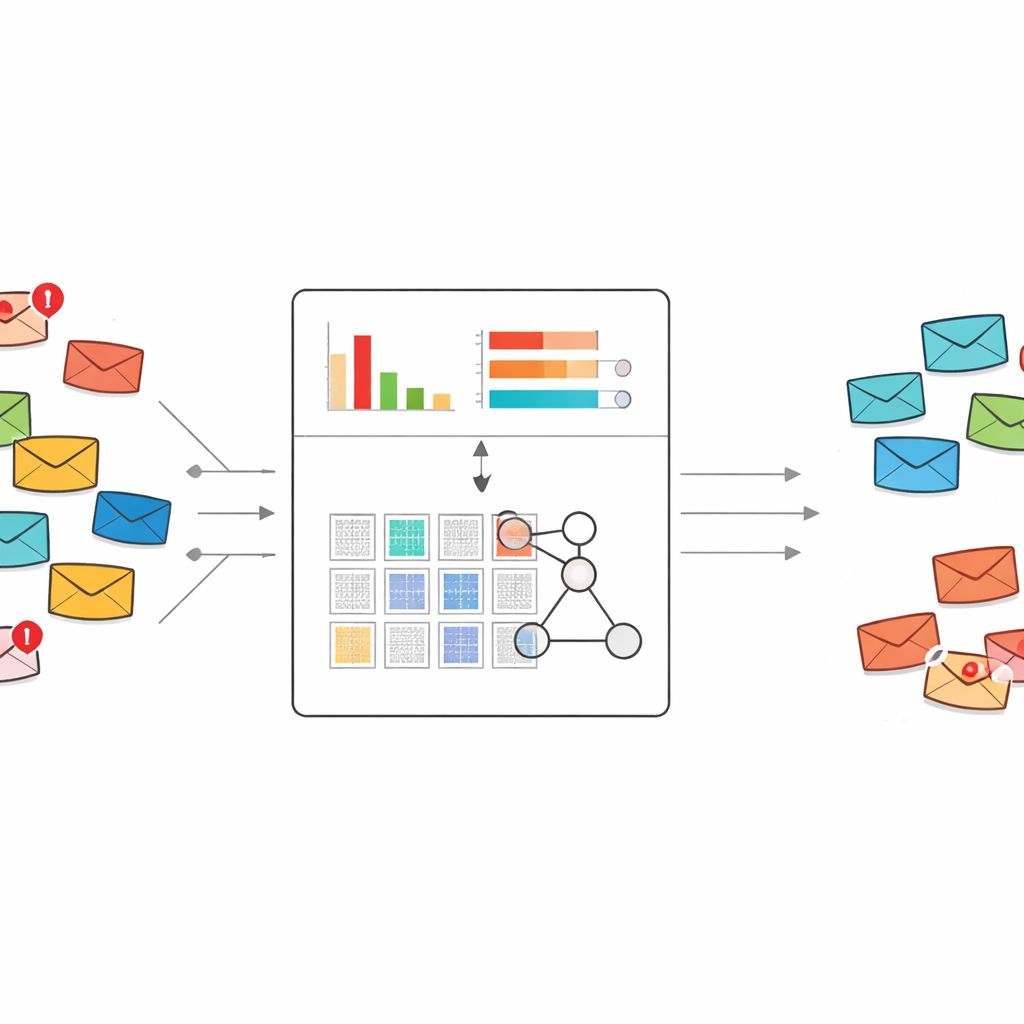
Una forma nueva de leer lo que dice el spam
La mayoría de los filtros de spam actuales se basan en aprendizaje automático estándar o en aprendizaje profundo. Estos sistemas normalmente necesitan miles o millones de correos etiquetados y enormes listas de palabras como características para aprender. Pueden ser potentes, pero cuando aparece un nuevo estilo de estafa y solo hay unos pocos ejemplos disponibles, a menudo tienen dificultades o se comportan como una caja negra. Los autores, en cambio, se basan en un marco de sistemas expertos llamado base de reglas de creencia, que representa el conocimiento como reglas «si–entonces» legibles por humanos y está naturalmente diseñado para aprender a partir de conjuntos de datos pequeños.
Seleccionando las palabras que realmente delatan el spam
Un reto directo es que el texto bruto de los correos contiene un número enorme de posibles palabras y frases. Alimentar todas ellas a un sistema de reglas haría explotar el número de reglas hasta volverlo inmanejable. Para evitarlo, los autores rediseñan un esquema clásico de ponderación de texto conocido como TF–IDF para que no solo capture cuán importante es una palabra para un documento, sino cuánto se inclina hacia el spam frente al correo normal. Su método de «TF–IDF discriminativa» se centra primero únicamente en los mensajes de spam para construir un vocabulario de palabras y frases reveladoras. Luego puntúa cada término según si aparece más en spam o en correo normal, y conserva solo aquellos que se inclinan claramente hacia el spam.
Reducir cada mensaje a dos señales simples
En lugar de pasar cientos o miles de indicadores de palabras al sistema de reglas, el método comprime cada mensaje en solo dos números. El primero es una puntuación general de spam, que suma la intensidad con que las palabras inclinadas al spam en ese mensaje apuntan a peligro. El segundo es una densidad de palabras clave de spam, que mide cuántas de las palabras del mensaje proceden del vocabulario sospechoso. Estos dos valores se escalan entre cero y uno y se usan como únicas entradas para un conjunto compacto de reglas que describen cómo deben interpretarse distintas combinaciones de puntuaciones como spam o correo seguro, junto con grados de creencia asociados.
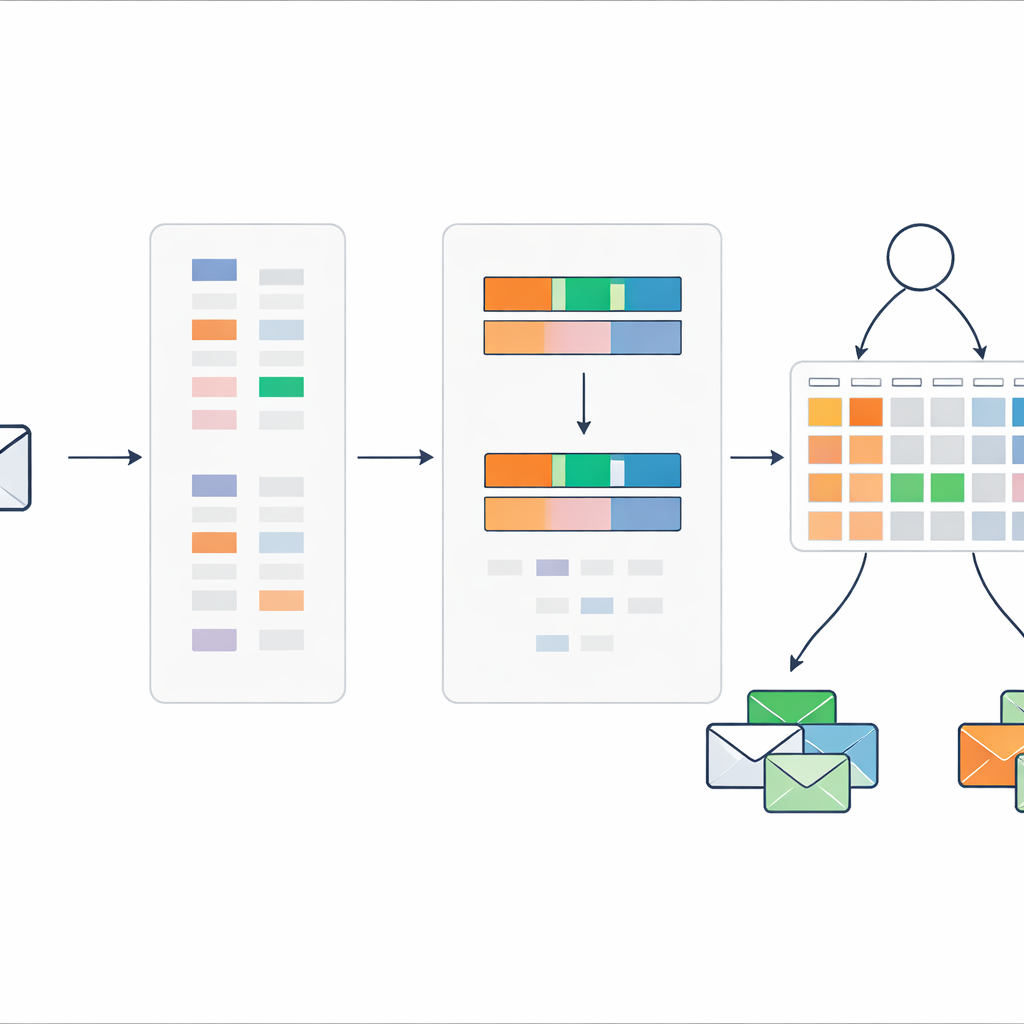
Reglas que se adaptan pero siguen siendo comprensibles
El sistema de reglas parte del conocimiento experto: por ejemplo, un mensaje con una puntuación de spam alta y una densidad de palabras clave de spam alta debería ser casi con seguridad spam, mientras que señales contradictorias exigen juicios más cautelosos. Para refinar estos ajustes iniciales, los autores utilizan un procedimiento de optimización evolutiva que ajusta automáticamente los pesos de las reglas y los valores de creencia respetando restricciones lógicas. Esto permite que el modelo se ajuste con datos reales sin perder su estructura transparente basada en reglas. Cada decisión final todavía puede rastrearse a través de un pequeño conjunto de reglas legibles por humanos y de las puntuaciones de entrada.
Demostrar el enfoque con mensajes del mundo real
El equipo prueba su modelo en dos conjuntos de datos públicos: una colección ampliamente usada de mensajes SMS y un conjunto separado de correos fraudulentos. En cada caso se limitan a solo 200 ejemplos etiquetados —100 spam y 100 mensajes normales— para imitar la etapa temprana de un nuevo brote de spam. A lo largo de múltiples rondas de validación cruzada, su modelo alcanza precisiones de alrededor del 91,5 % en SMS y del 95,5 % en correos fraudulentos, superando a una gama de sistemas de aprendizaje automático tradicionales, aprendizaje profundo y lógica difusa probados bajo las mismas condiciones de pocos datos. El nuevo método de puntuación de características también resulta esencial: cuando se elimina en un estudio de ablación, el rendimiento cae notablemente aunque la estructura de reglas permanezca igual.
Qué significa esto para buzones más seguros
Para quienes no son especialistas, el resultado clave es que es posible construir un filtro de spam que funcione bien con muy pocos datos etiquetados y que además «muestre su razonamiento» de forma comprensible. Al destilar el texto complejo en solo dos señales significativas y aplicar un sistema de reglas compacto que pueda inspeccionarse y refinarse, el modelo propuesto ofrece tanto una detección temprana sólida de nuevo spam como explicaciones claras de sus decisiones. En términos prácticos, esto podría ayudar a proveedores de correo y equipos de seguridad a reaccionar más rápido ante campañas de estafa emergentes, reducir la dependencia de modelos opacos de caja negra y dar a los expertos una visión más clara de cómo evolucionan las tácticas de spam.
Cita: Yang, X., Zhou, W., Duan, X. et al. A spam detection model based on the discriminative TF-IDF belief rule base. Sci Rep 16, 11962 (2026). https://doi.org/10.1038/s41598-026-42223-6
Palabras clave: detección de spam, seguridad del correo electrónico, clasificación de texto, IA interpretable, aprendizaje con pocas muestras