Clear Sky Science · sv
En modell för spamdetektion baserad på ett diskriminerande TF-IDF-belief rule base
Varför smartare spamfilter är viktiga för alla
Våra inkorgar svämmar över av skräppost som försöker sälja falska produkter, stjäla lösenord eller lura oss att skicka pengar. De farligaste spamvågorna ser ofta nya och annorlunda ut, och dyker upp innan företagen har samlat tillräckligt många exempel för att träna traditionella detektionsverktyg. Denna artikel presenterar en ny typ av spamfilter som kan fungera väl även när endast ett litet antal misstänkta meddelanden observerats, samtidigt som det tydligt förklarar varför ett meddelande flaggas som spam eller som säkert.
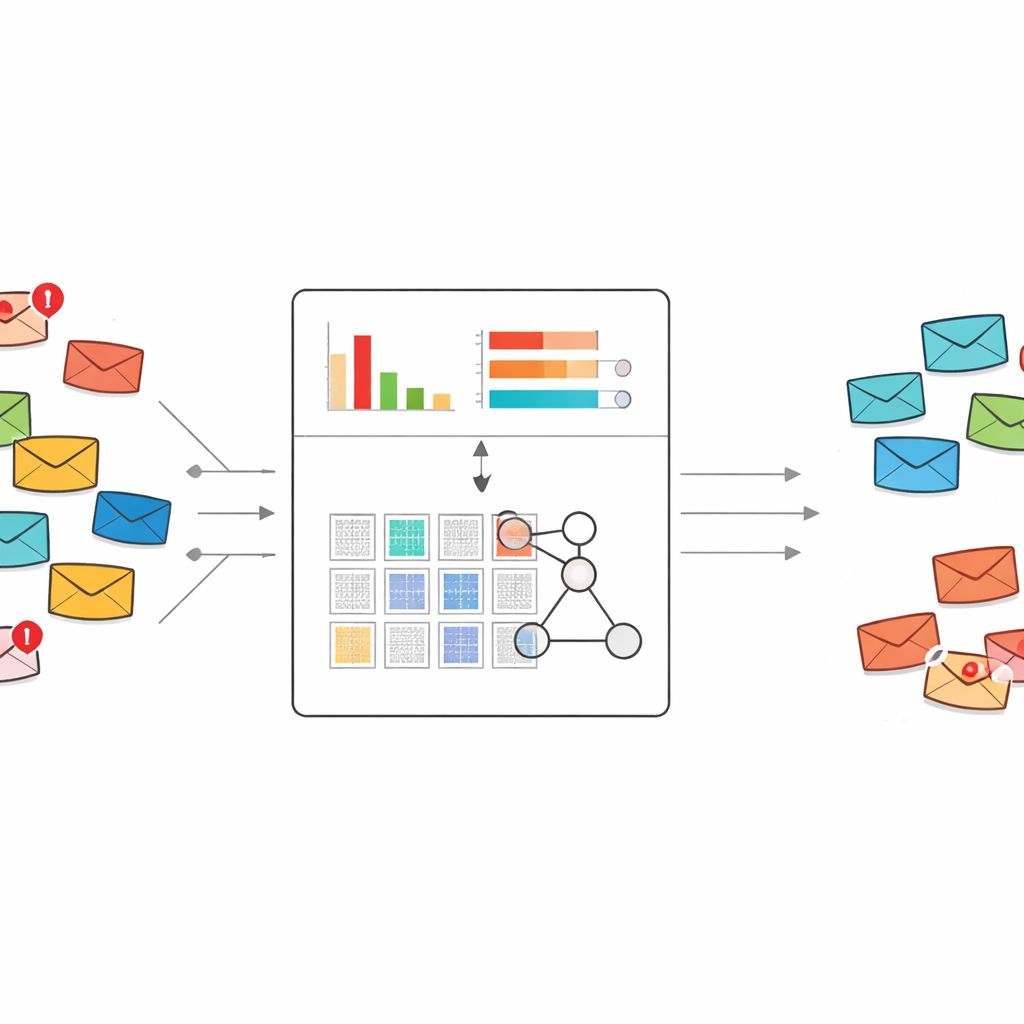
En ny metod för att läsa vad spam säger
De flesta spamfilter i dag bygger antingen på standard maskininlärning eller djupinlärning. Dessa system behöver vanligtvis tusentals eller miljontals märkta e-postmeddelanden och stora listor med ordfunktioner för att lära sig. De kan vara kraftfulla, men när en ny typ av bluff uppstår och endast några få exempel finns, har de ofta svårt eller fungerar som en svart låda. Författarna bygger istället vidare på ett expert-systemramverk kallat belief rule base, som representerar kunskap som människoläsbara "om–så"-regler och är naturligt lämpat för inlärning från små datamängder.
Att plocka ut orden som verkligen avslöjar spam
En direkt utmaning är att rå e-posttext innehåller ett enormt antal möjliga ord och fraser. Att mata in alla dessa i ett regelsystem skulle explodera till ett ohanterligt antal regler. För att undvika detta omformar författarna ett klassiskt textviktningsschema känt som TF–IDF så att det inte bara fångar hur viktigt ett ord är för ett dokument, utan hur starkt det lutar mot spam snarare än normalt brev. Deras "diskriminerande TF–IDF"-metod fokuserar först endast på spam-meddelanden för att bygga upp ett vokabulär av avslöjande ord och korta fraser. Därefter poängsätter den varje term efter om den förekommer mer i spam eller i normalt mail, och behåller bara de som tydligt lutar mot spam.
Att koka ner varje meddelande till två enkla signaler
I stället för att föra in hundratals eller tusentals ordindikatorer i regelsystemet komprimerar metoden varje meddelande till endast två tal. Det första är en övergripande spamscore, som summerar hur starkt de spam-lutande orden i meddelandet pekar mot problem. Det andra är en täthet av spamnyckelord, som mäter hur många av orden i meddelandet som kommer från det misstänkta vokabuläret. Dessa två värden skalas mellan noll och ett och används som de enda ingångarna till en kompakt uppsättning regler som beskriver hur olika kombinationer av poäng bör tolkas som spam eller säkra meddelanden, tillsammans med tillhörande grader av tro.
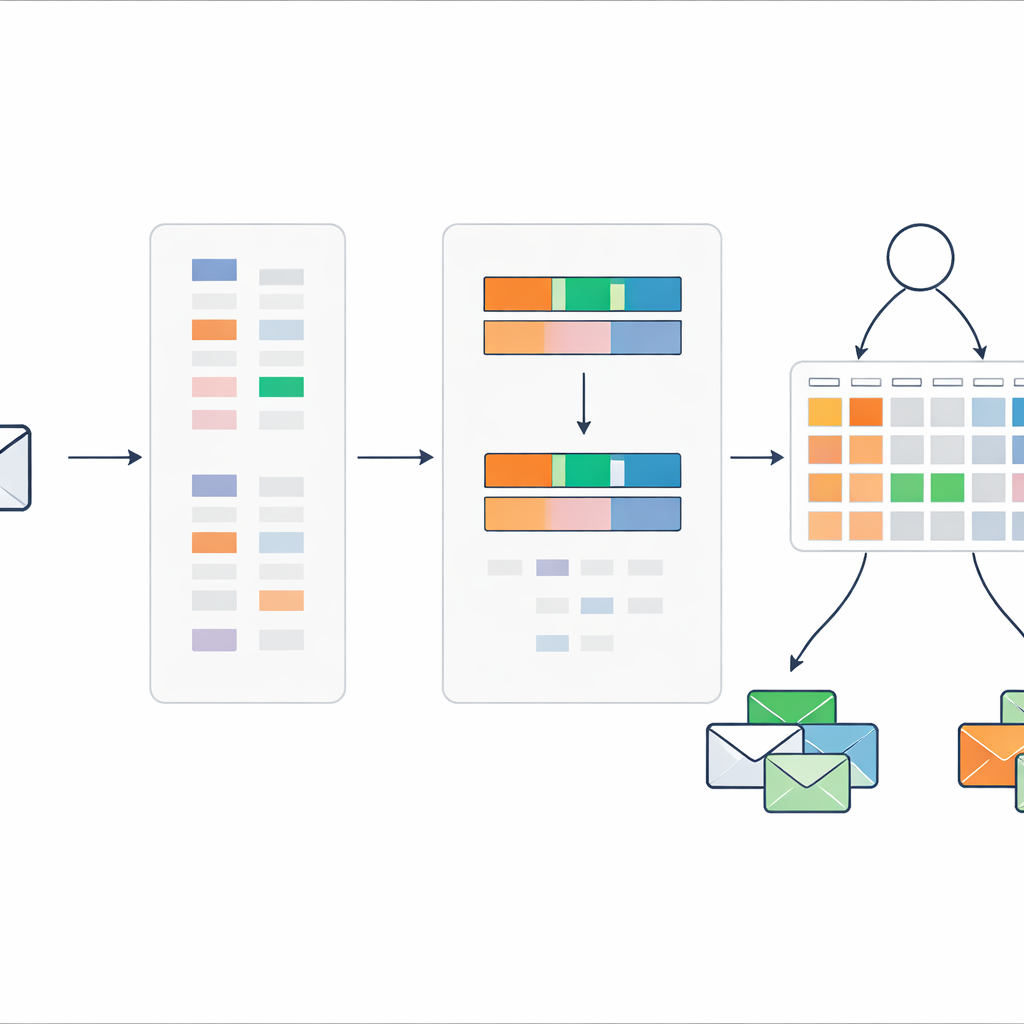
Regler som anpassar sig men förblir begripliga
Regelsystemet startar från expertkunskap: till exempel bör ett meddelande med både hög spamscore och hög spamnyckelordstäthet nästan säkert vara spam, medan motstridiga signaler kräver mer försiktiga bedömningar. För att finslipa dessa initiala inställningar använder författarna en evolutionär optimeringsprocedur som automatiskt justerar regelvikter och trosvärden samtidigt som logiska begränsningar respekteras. Detta tillåter modellen att ställa in sig på verkliga data utan att förlora sin transparenta, regelbaserade struktur. Varje slutligt beslut kan fortfarande spåras tillbaka genom en liten uppsättning människoläsbara regler och indata-poäng.
Att pröva metoden på verkliga meddelanden
Teamet testar sin modell på två publika dataset: en allmänt använd samling SMS-meddelanden och en separat uppsättning bedrägliga e-postmeddelanden. I båda fallen begränsar de sig till endast 200 märkta exempel—100 spam och 100 normala meddelanden—för att efterlikna ett tidigt skede av ett nytt spamutbrott. Över flera rundor av korsvalidering når deras modell en noggrannhet på omkring 91,5 % för SMS och 95,5 % för bedrägerie-post, och överträffar en rad traditionella maskininlärnings-, djupinlärnings- och fuzzy-logiksystem testade under samma lågdatasförhållanden. Den nya metodiken för poängsättning av funktioner visar sig också vara avgörande: när den tas bort i en ablationsstudie sjunker prestandan märkbart även om regelstrukturen förblir densamma.
Vad detta betyder för säkrare inkorgar
För icke-specialister är huvudresultatet att det är möjligt att bygga ett spamfilter som fungerar väl med mycket lite märkt data och fortfarande "visar sitt arbete" på ett sätt som människor kan förstå. Genom att destillera komplex text till bara två meningsfulla signaler och sedan tillämpa ett kompakt regelsystem som kan inspekteras och förfinas, erbjuder den föreslagna modellen både stark tidig upptäckt av ny spam och tydliga förklaringar till sina val. I praktiska termer kan detta hjälpa e-postleverantörer och säkerhetsteam att reagera snabbare på nya bluffkampanjer, minska överberoendet av opaka svartlådemodeller och ge experter tydligare insikt i hur spamtaktiker utvecklas.
Citering: Yang, X., Zhou, W., Duan, X. et al. A spam detection model based on the discriminative TF-IDF belief rule base. Sci Rep 16, 11962 (2026). https://doi.org/10.1038/s41598-026-42223-6
Nyckelord: spamdetektion, e-postsäkerhet, textklassificering, tolkbar AI, inlärning med få prov