Clear Sky Science · ru
Модель обнаружения спама на основе дискриминативной TF-IDF belief rule base
Почему более умные фильтры спама важны для всех
Наши почтовые ящики завалены нежелательными сообщениями, которые пытаются продать поддельные товары, украсть пароли или выманить деньги. Самые опасные волны спама часто выглядят новыми и необычными — они появляются до того, как компании соберут достаточно примеров для обучения традиционных инструментов обнаружения. В этой статье предлагается новый тип фильтра спама, который эффективно работает даже при малом числе доступных подозрительных сообщений и при этом ясно объясняет, почему помечает сообщение как спам или как безопасное.
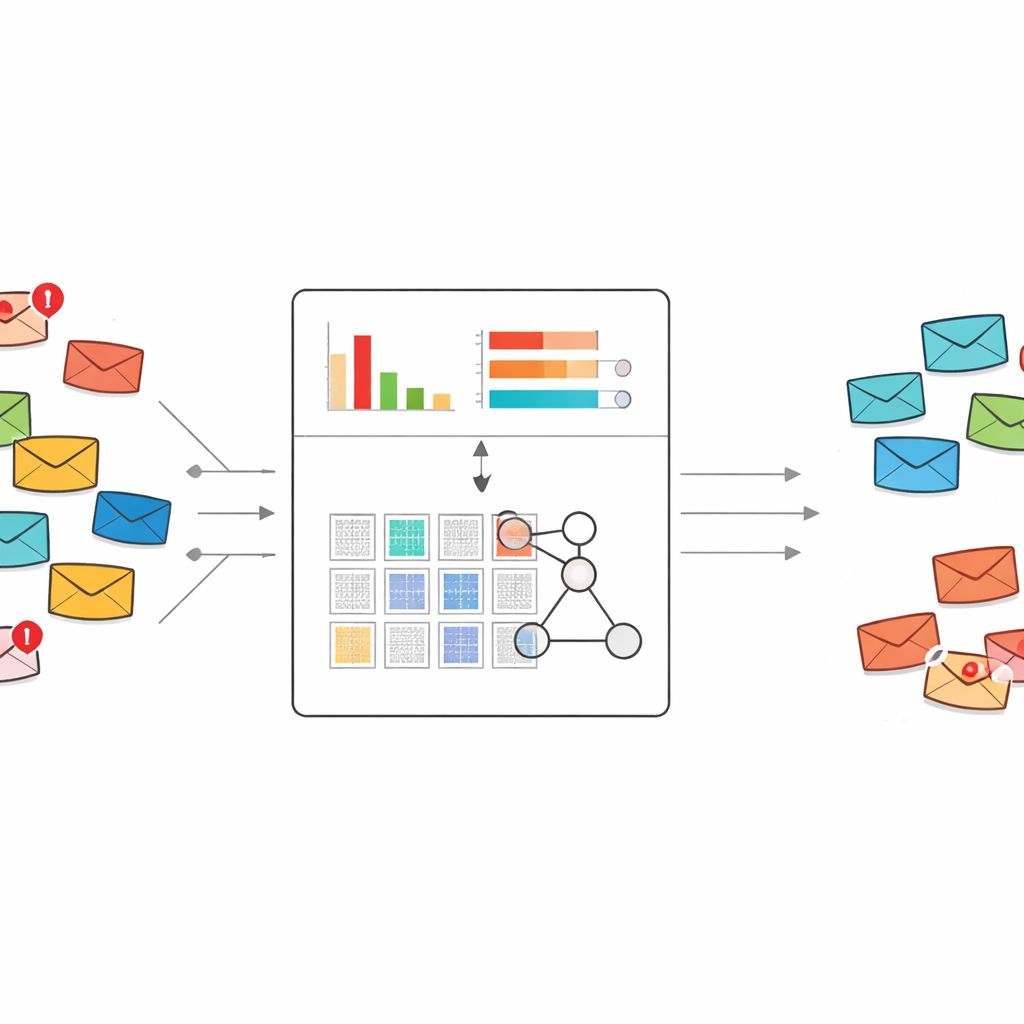
Новый способ интерпретации сигналов спама
Большинство современных фильтров спама опираются либо на классические методы машинного обучения, либо на глубокое обучение. Эти системы обычно требуют тысяч или миллионов размеченных писем и больших списков слов-признаков для обучения. Они могут быть мощными, но когда появляется новый тип мошенничества и доступно лишь несколько примеров, такие модели часто ошибаются или ведут себя как черный ящик. Авторы вместо этого опираются на экспертную систему под названием belief rule base, которая представляет знания в виде человекочитаемых «если—то» правил и естественно подходит для обучения на небольших наборах данных.
Отбор слов, которые действительно выдают спам
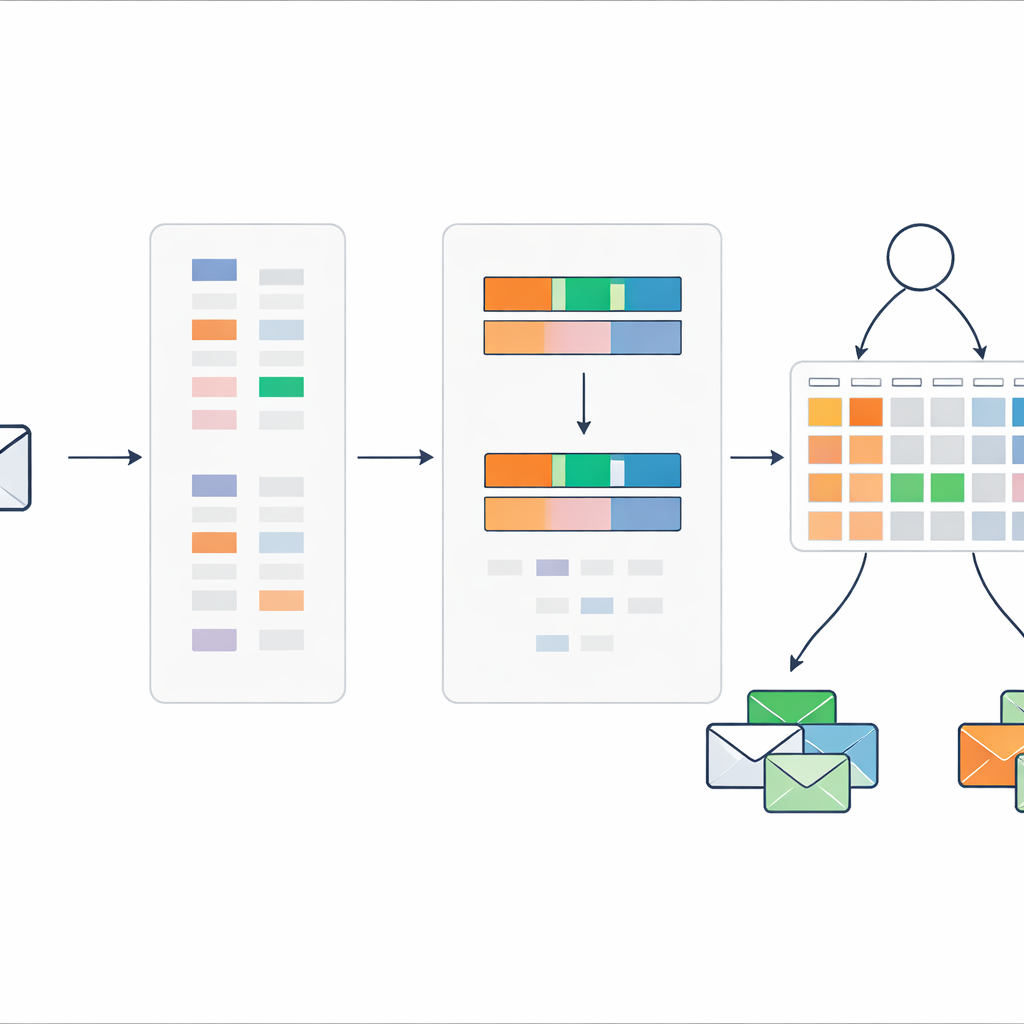
Прямая проблема в том, что сырой текст письма содержит огромное количество возможных слов и фраз. Подключение всех этих признаков к системе правил привело бы к взрывному росту числа правил. Чтобы этого избежать, авторы переработали классическую схему взвешивания текста TF–IDF так, чтобы она учитывала не только важность слова для документа, но и то, насколько слово склоняется к спаму, а не к обычной почте. Их метод «дискриминативного TF–IDF» сначала фокусируется только на спам-сообщениях, формируя словарь характерных слов и коротких фраз. Затем каждый термин оценивается по тому, встречается ли он чаще в спаме или в нормальной почте, и сохраняются только те, которые явно склоняются в сторону спама.
Сведение каждого сообщения к двум простым сигналам
Вместо передачи сотен или тысяч индикаторов слов в систему правил, метод сжимает каждое сообщение до всего двух чисел. Первое — общий спам-скор, который суммирует силу признаков слов, склонных к спаму, в этом сообщении. Второе — плотность ключевых слов спама, измеряющая долю слов в сообщении, попадающих в подозрительный словарь. Эти два значения масштабируются от нуля до единицы и используются как единственные входы компактного набора правил, которые описывают, как различные комбинации значений следует интерпретировать как спам или как безопасную почту, вместе со связанными степенями уверенности.
Правила, которые адаптируются, оставаясь понятными
Система правил начинается с экспертных знаний: например, сообщение с высоким спам-скором и высокой плотностью ключевых слов спама почти наверняка является спамом, в то время как противоречивые сигналы требуют более осторожной оценки. Для уточнения начальных настроек авторы используют эволюционную оптимизацию, которая автоматически корректирует веса правил и значения степени уверенности при соблюдении логических ограничений. Это позволяет модели подстраиваться под реальные данные, не теряя прозрачной правиловой структуры. Каждое итоговое решение по-прежнему можно проследить через небольшой набор человекочитаемых правил и входных показателей.
Проверка подхода на реальных сообщениях
Авторы тестируют свою модель на двух общедоступных наборах данных: широко используемом наборе SMS-сообщений и отдельном наборе мошеннических электронных писем. В каждом случае они ограничиваются всего 200 размеченными примерами — 100 спама и 100 обычных сообщений — чтобы имитировать раннюю стадию новой волны спама. В ходе многократной кросс-валидации их модель достигает примерно 91.5% точности на SMS и 95.5% на мошеннических письмах, превосходя ряд традиционных методов машинного обучения, глубокого обучения и систем нечеткой логики, протестированных в тех же условиях малых данных. Новая схема оценки признаков также оказывается критически важной: при её удалении в эксперименте абляции производительность заметно падает, хотя структура правил сохраняется.
Что это значит для безопасных почтовых ящиков
Для неспециалистов ключевой вывод заключается в том, что возможно создать фильтр спама, который хорошо работает при очень малом объёме размеченных данных и при этом «показывает свою работу» в понятной форме. Сводя сложный текст к двум информативным сигналам и применяя компактную систему правил, которую можно просмотреть и донастроить, предложенная модель обеспечивает раннее эффективное обнаружение новых типов спама и даёт ясные объяснения своих решений. На практике это может помочь почтовым провайдерам и командам безопасности быстрее реагировать на появление мошеннических кампаний, снизить зависимость от непрозрачных «черных ящиков» и дать экспертам более четкое понимание эволюции тактик спамеров.
Цитирование: Yang, X., Zhou, W., Duan, X. et al. A spam detection model based on the discriminative TF-IDF belief rule base. Sci Rep 16, 11962 (2026). https://doi.org/10.1038/s41598-026-42223-6
Ключевые слова: обнаружение спама, безопасность электронной почты, классификация текста, интерпретируемый ИИ, обучение на малых выборках