Clear Sky Science · it
Un modello di rilevamento dello spam basato sulla belief rule base discriminativa TF-IDF
Perché filtri antispam più intelligenti contano per tutti
Le nostre caselle di posta sono invase da messaggi indesiderati che cercano di vendere prodotti falsi, rubare password o indurci a inviare denaro. Le ondate più pericolose di spam spesso sembrano nuove e diverse, arrivando prima che le aziende riescano a raccogliere esempi sufficienti per addestrare gli strumenti di rilevamento tradizionali. Questo articolo presenta un nuovo tipo di filtro antispam in grado di funzionare bene anche quando sono disponibili solo poche e-mail sospette, oltre a spiegare in modo chiaro perché segnala un messaggio come spam o come sicuro.
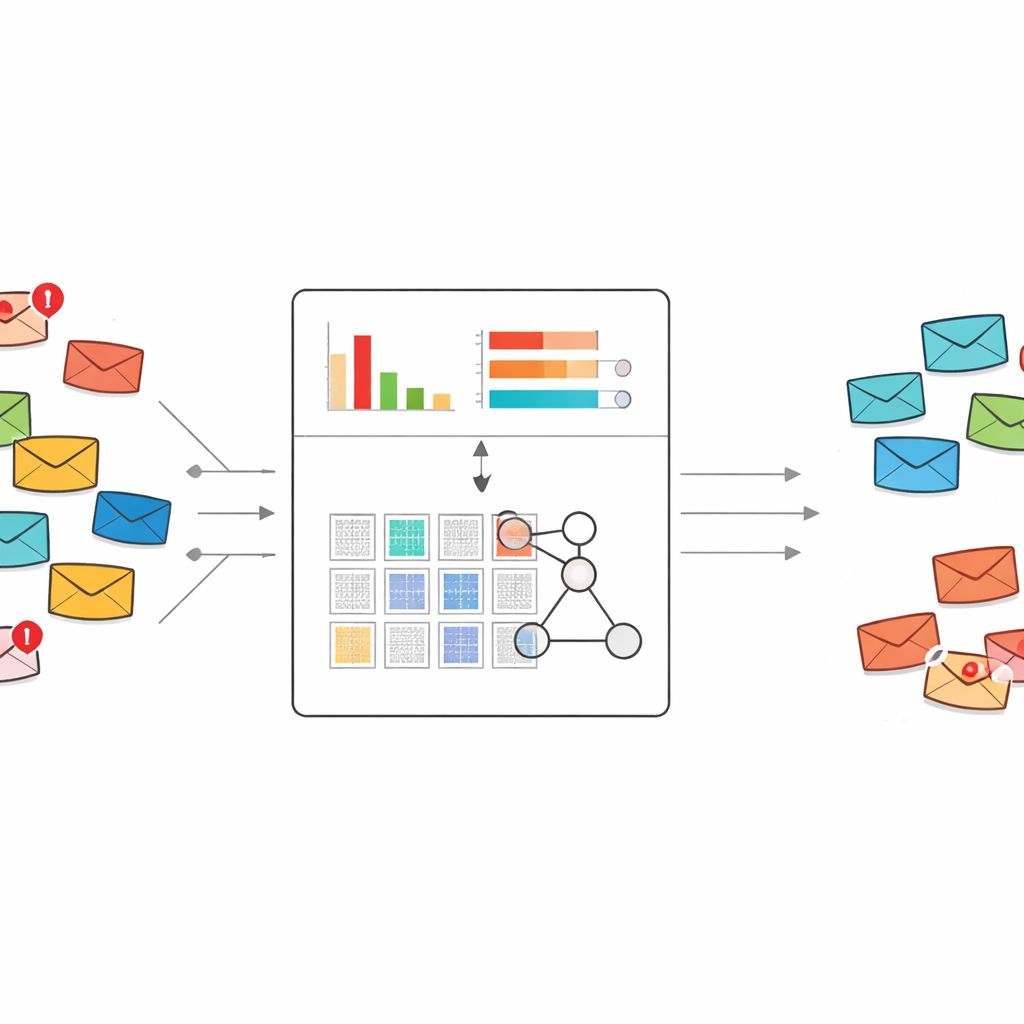
Un modo nuovo per interpretare ciò che dice lo spam
La maggior parte dei filtri antispam attuali si basa su machine learning classico o deep learning. Questi sistemi in genere necessitano di migliaia o milioni di e-mail etichettate e di lunghe liste di caratteristiche lessicali da cui apprendere. Possono essere potenti, ma quando appare un nuovo tipo di truffa e sono disponibili soltanto pochi esempi, spesso faticano o si comportano come una scatola nera. Gli autori invece partono da un framework a sistema esperto chiamato belief rule base, che rappresenta la conoscenza come regole "se–allora" leggibili dall'uomo ed è naturalmente adatto ad apprendere da dataset ridotti.
Selezionare le parole che davvero svelano lo spam
Una sfida diretta è che il testo grezzo delle e-mail contiene un numero enorme di parole e frasi possibili. Inserire tutto questo in un sistema a regole porterebbe a un’esplosione del numero di regole, diventando ingestibile. Per evitarlo, gli autori riprogettano uno schema classico di pesatura del testo noto come TF–IDF in modo che non catturi solo quanto una parola sia importante in un documento, ma quanto essa tenda verso lo spam piuttosto che verso la posta normale. Il loro metodo di "TF–IDF discriminativo" si concentra inizialmente solo sui messaggi spam per costruire un vocabolario di parole e brevi frasi indicatrici. Assegna quindi a ogni termine un punteggio in base alla sua prevalenza nello spam rispetto alla posta normale e conserva soltanto quelli che mostrano un chiaro orientamento verso lo spam.
Ridurre ogni messaggio a due segnali semplici
Invece di passare centinaia o migliaia di indicatori lessicali al sistema a regole, il metodo comprime ogni messaggio in appena due numeri. Il primo è un punteggio complessivo di spam, che somma quanto fortemente le parole con tendenza allo spam in quel messaggio indichino rischio. Il secondo è la densità di parole chiave spam, che misura quante delle parole del messaggio provengono dal vocabolario sospetto. Questi due valori sono scalati tra zero e uno e usati come unici input per un compatto insieme di regole che descrivono come diverse combinazioni di punteggi debbano essere interpretate come spam o posta sicura, assieme ai relativi gradi di credenza.
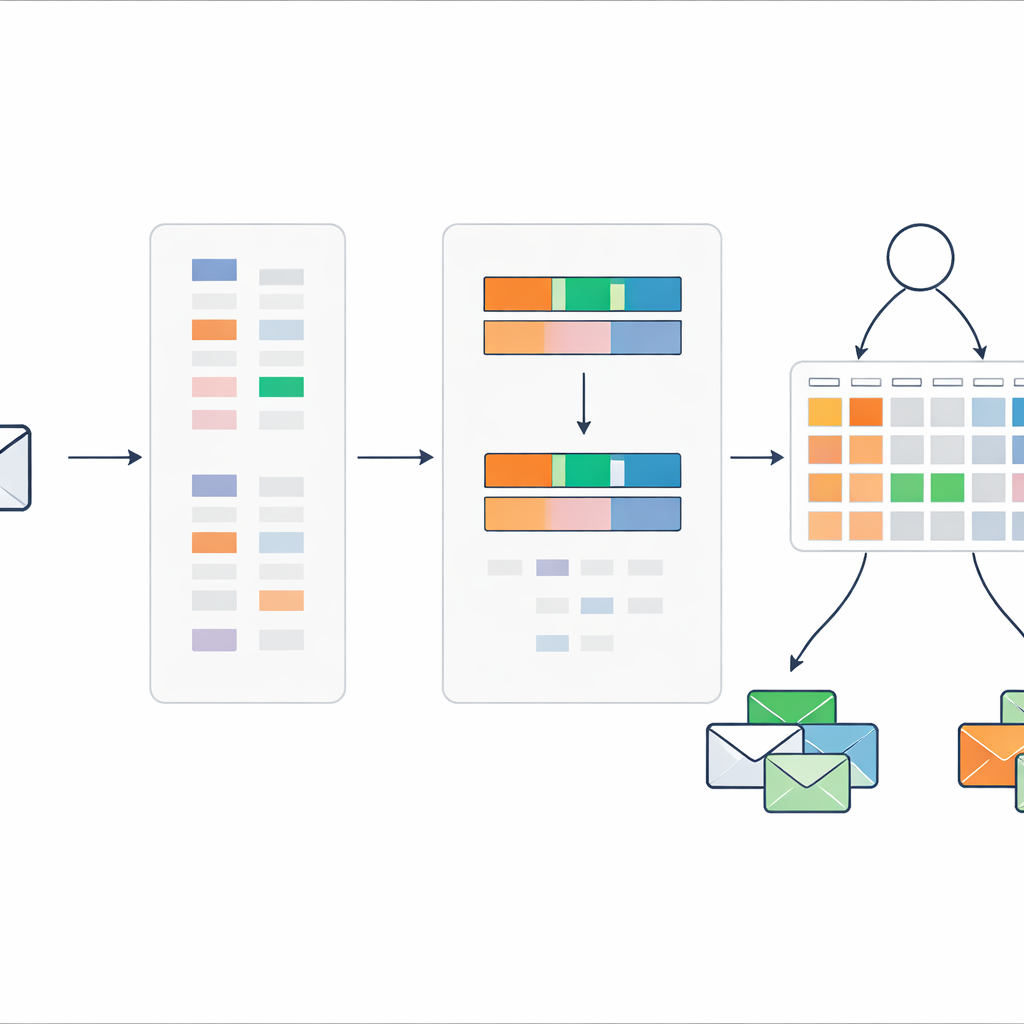
Regole che si adattano ma restano comprensibili
Il sistema a regole parte dalla conoscenza esperta: per esempio, un messaggio con sia un alto punteggio di spam sia un’alta densità di parole chiave spam dovrebbe quasi certamente essere spam, mentre segnali contrastanti richiedono giudizi più cauti. Per perfezionare queste impostazioni iniziali, gli autori utilizzano una procedura di ottimizzazione evolutiva che aggiusta automaticamente i pesi delle regole e i valori di credenza rispettando vincoli logici. Questo permette al modello di sintonizzarsi sui dati reali senza perdere la sua struttura trasparente basata su regole. Ogni decisione finale può ancora essere ricondotta a un piccolo insieme di regole leggibili dall'uomo e ai punteggi di input.
Dimostrare l’approccio su messaggi reali
Il team testa il modello su due dataset pubblici: una raccolta ampiamente usata di messaggi di testo SMS e un set separato di e-mail fraudolente. In entrambi i casi si limitano a soli 200 esempi etichettati—100 spam e 100 messaggi normali—per imitare la fase iniziale di una nuova ondata di spam. In molteplici round di cross-validazione, il loro modello raggiunge accuratezze di circa il 91,5% sugli SMS e il 95,5% sulle e-mail fraudolente, superando una gamma di sistemi di machine learning tradizionale, deep learning e logica fuzzy testati nelle stesse condizioni di pochi dati. Anche il nuovo metodo di valutazione delle caratteristiche si dimostra essenziale: quando viene rimosso in uno studio di ablazione, le prestazioni calano sensibilmente nonostante la struttura delle regole rimanga la stessa.
Cosa significa questo per caselle di posta più sicure
Per i non specialisti, il risultato chiave è che è possibile costruire un filtro antispam che funziona bene con pochissimi dati etichettati e che continua a "mostrare il proprio lavoro" in modo comprensibile. Distillando il testo complesso in appena due segnali significativi e quindi applicando un sistema di regole compatto che può essere ispezionato e perfezionato, il modello proposto offre sia una forte rilevazione precoce di nuovo spam sia spiegazioni chiare delle sue scelte. In termini pratici, ciò potrebbe aiutare i fornitori di posta e i team di sicurezza a reagire più rapidamente a campagne di truffa emergenti, ridurre la dipendenza da modelli opachi a scatola nera e dare agli esperti una visione più nitida di come evolvono le tattiche dello spam.
Citazione: Yang, X., Zhou, W., Duan, X. et al. A spam detection model based on the discriminative TF-IDF belief rule base. Sci Rep 16, 11962 (2026). https://doi.org/10.1038/s41598-026-42223-6
Parole chiave: rilevamento spam, sicurezza email, classificazione di testo, IA interpretabile, apprendimento da piccoli campioni