Clear Sky Science · en
A spam detection model based on the discriminative TF-IDF belief rule base
Why smarter spam filters matter to everyone
Our inboxes are flooded with junk messages trying to sell fake products, steal passwords, or trick us into sending money. The most dangerous waves of spam often look new and different, arriving before companies have collected enough examples to train traditional detection tools. This paper presents a new kind of spam filter that can work well even when only a small number of suspicious messages have been seen, while also explaining clearly why it flags a message as spam or as safe.
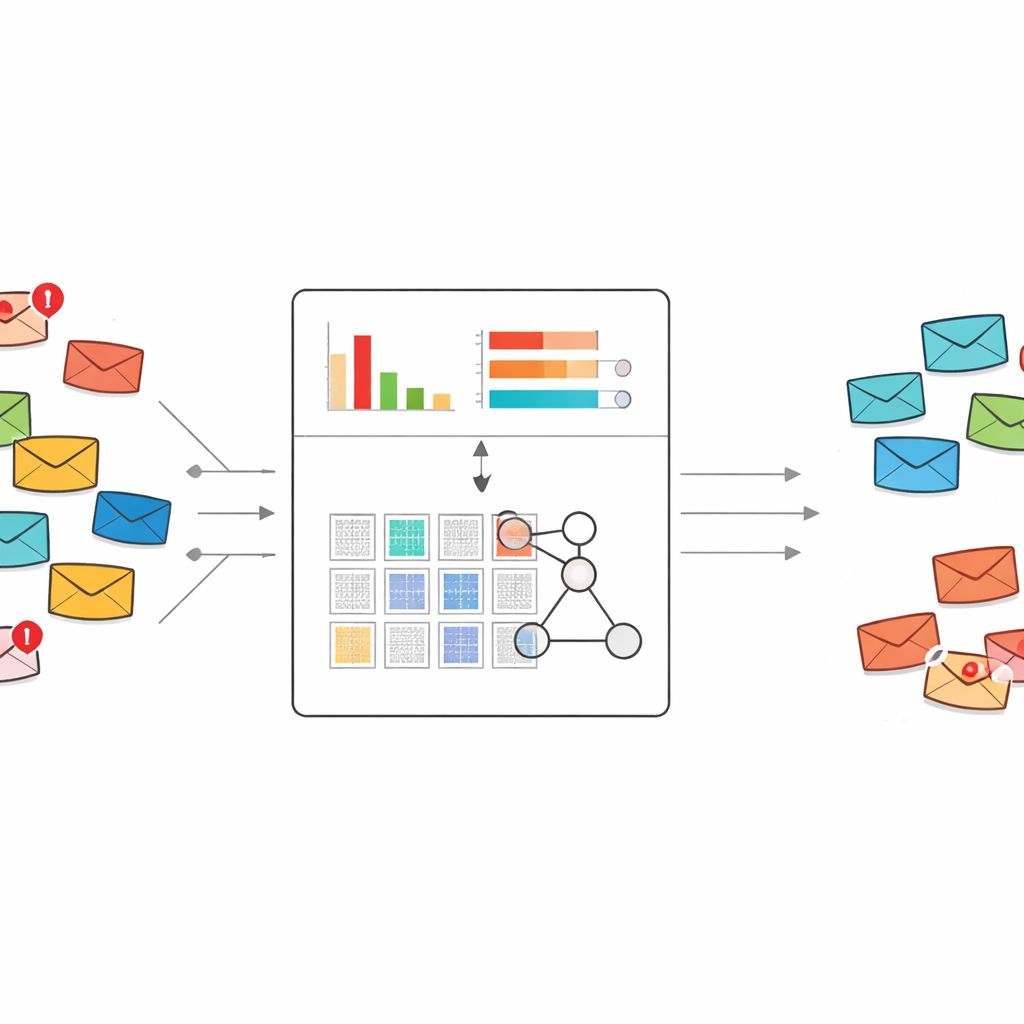
A fresh way to read what spam is saying
Most spam filters today rely on either standard machine learning or deep learning. These systems usually need thousands or millions of labeled emails and huge lists of word features to learn from. They can be powerful, but when a new style of scam appears and only a few examples are available, they often struggle or behave like a black box. The authors instead build on an expert-system framework called a belief rule base, which represents knowledge as human-readable "if–then" rules and is naturally suited to learning from small datasets.
Picking out the words that really give spam away
A direct challenge is that raw email text contains an enormous number of possible words and phrases. Feeding all of these into a rule system would explode into an unmanageable number of rules. To avoid this, the authors redesign a classic text weighting scheme known as TF–IDF so that it does not just capture how important a word is to a document, but how strongly it leans toward spam rather than normal mail. Their "discriminative TF–IDF" method first focuses only on spam messages to build a vocabulary of telltale words and short phrases. It then scores each term according to whether it appears more in spam or in normal mail, and keeps only those that lean clearly toward spam.
Boiling each message down to two simple signals
Instead of passing hundreds or thousands of word indicators into the rule system, the method compresses each message into just two numbers. The first is an overall spam score, which adds up how strongly the spam-leaning words in that message point toward trouble. The second is a spam keyword density, measuring how many of the words in the message come from the suspicious vocabulary. These two values are scaled between zero and one and used as the sole inputs to a compact set of rules that describe how different combinations of scores should be interpreted as spam or safe mail, together with associated degrees of belief.
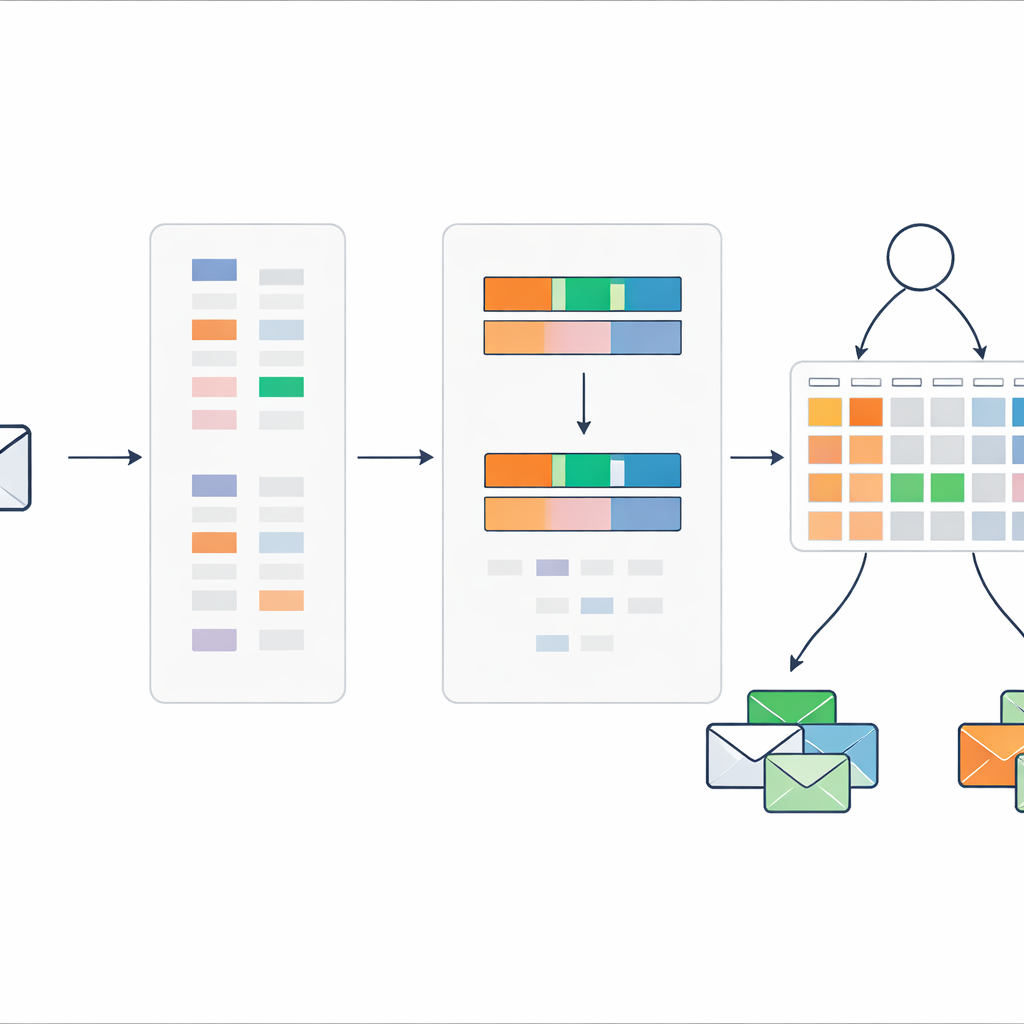
Rules that adapt but remain understandable
The rule system starts from expert knowledge: for example, a message with both a high spam score and a high spam keyword density should almost certainly be spam, while conflicting signals call for more cautious judgments. To refine these initial settings, the authors use an evolutionary optimization procedure that automatically adjusts rule weights and belief values while respecting logical constraints. This allows the model to tune itself on real data without losing its transparent, rule-based structure. Every final decision can still be traced back through a small set of human-readable rules and input scores.
Proving the approach on real-world messages
The team tests their model on two public datasets: a widely used collection of SMS text messages and a separate set of fraudulent emails. In each case they limit themselves to only 200 labeled examples—100 spam and 100 normal messages—to mimic the early stage of a new spam outbreak. Across multiple rounds of cross-validation, their model reaches accuracies of about 91.5% on SMS and 95.5% on fraud emails, outperforming a range of traditional machine learning, deep learning, and fuzzy-logic systems tested under the same low-data conditions. The new feature scoring method also proves essential: when it is removed in an ablation study, performance drops noticeably even though the rule structure stays the same.
What this means for safer inboxes
For non-specialists, the key result is that it is possible to build a spam filter that works well with very little labeled data and still "shows its work" in a way people can understand. By distilling complex text into just two meaningful signals, then applying a compact rule system that can be inspected and refined, the proposed model offers both strong early detection of new spam and clear explanations for its choices. In practical terms, this could help email providers and security teams react faster to emerging scam campaigns, reduce overreliance on opaque black-box models, and give experts clearer insight into how spam tactics are evolving.
Citation: Yang, X., Zhou, W., Duan, X. et al. A spam detection model based on the discriminative TF-IDF belief rule base. Sci Rep 16, 11962 (2026). https://doi.org/10.1038/s41598-026-42223-6
Keywords: spam detection, email security, text classification, interpretable AI, small-sample learning