Clear Sky Science · pl
Model wykrywania spamu oparty na dyskryminacyjnej bazie reguł wiary TF-IDF
Dlaczego inteligentniejsze filtry antyspamowe są ważne dla wszystkich
Nasze skrzynki odbiorcze zalewane są niechcianymi wiadomościami, które próbują sprzedawać fałszywe produkty, kraść hasła lub oszukiwać, aby wyłudzić pieniądze. Najniebezpieczniejsze fale spamu często wyglądają na nowe i inne, pojawiając się zanim firmy zdążą zebrać wystarczająco dużo przykładów do trenowania tradycyjnych narzędzi wykrywających. W artykule przedstawiono nowy rodzaj filtra antyspamowego, który działa dobrze nawet przy bardzo małej liczbie obserwowanych podejrzanych wiadomości, a jednocześnie jasno wyjaśnia, dlaczego oznacza wiadomość jako spam lub bezpieczną.
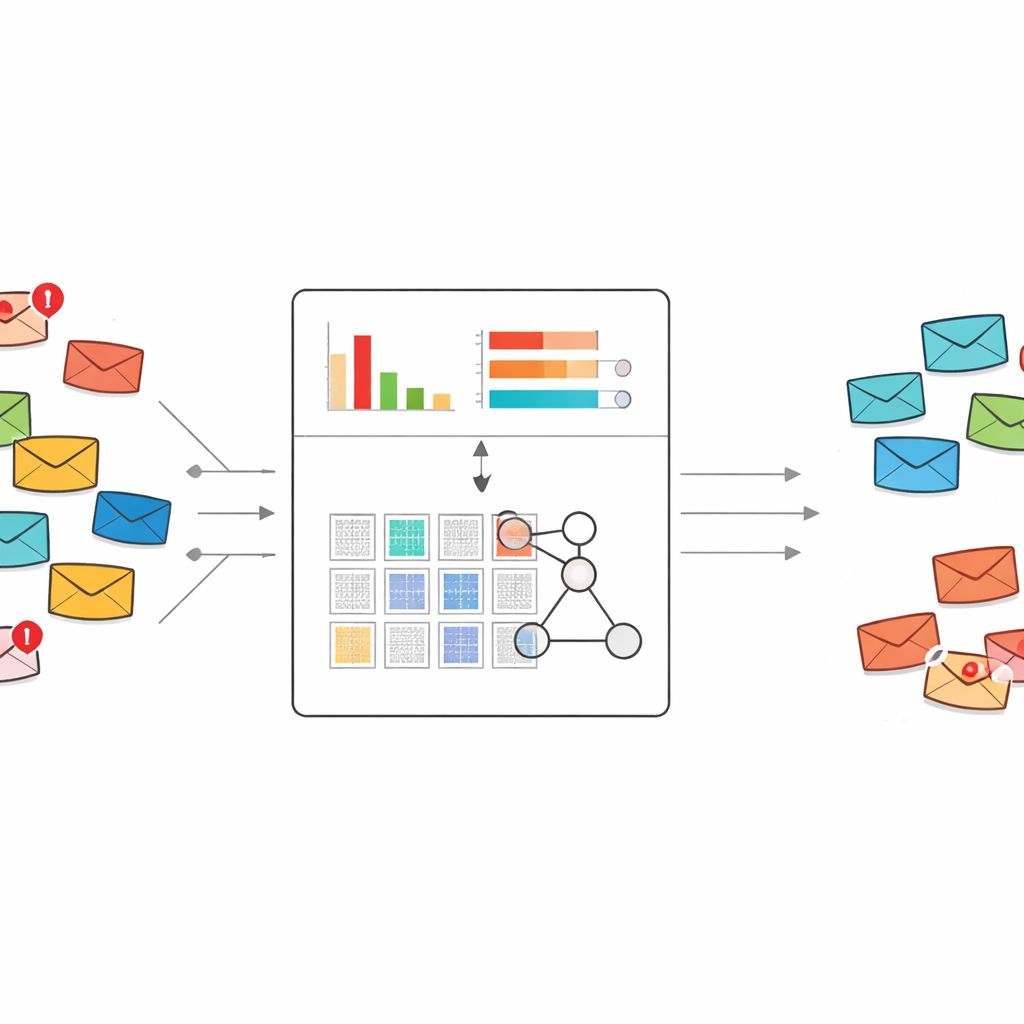
Nowe podejście do odczytywania, co mówi spam
Większość dzisiejszych filtrów antyspamowych opiera się na standardowym uczeniu maszynowym lub uczeniu głębokim. Systemy te zwykle potrzebują tysięcy lub milionów oznaczonych e-maili i obszernej listy cech słownych do nauki. Mogą być potężne, ale gdy pojawia się nowy rodzaj oszustwa i dostępnych jest tylko kilka przykładów, często sobie nie radzą lub działają jak czarna skrzynka. Autorzy zamiast tego opierają się na ramach systemu eksperckiego zwanych bazą reguł wiary (belief rule base), która reprezentuje wiedzę jako zrozumiałe dla człowieka reguły „jeśli–to” i naturalnie nadaje się do uczenia z małych zbiorów danych.
Wydobywanie słów, które naprawdę zdradzają spam
Bezpośrednim wyzwaniem jest to, że surowy tekst e-maila zawiera ogromną liczbę możliwych słów i fraz. Wprowadzenie wszystkich tych elementów do systemu reguł doprowadziłoby do eksplozji liczby reguł. Aby temu zapobiec, autorzy przeprojektowali klasyczną metodę ważenia tekstu znaną jako TF–IDF tak, żeby nie tylko uchwycić, jak ważne jest słowo dla dokumentu, lecz także jak silnie skłania się ku spamowi zamiast do poczty normalnej. Ich metoda „dyskryminacyjnego TF–IDF” koncentruje się najpierw wyłącznie na wiadomościach spamowych, aby zbudować słownictwo charakterystycznych słów i krótkich fraz. Następnie ocenia każdy termin pod kątem tego, czy pojawia się częściej w spamie, czy w poczcie normalnej, i zachowuje tylko te, które wyraźnie wskazują na spam.
Redukcja każdej wiadomości do dwóch prostych sygnałów
Zamiast przekazywać setki lub tysiące wskaźników słownych do systemu reguł, metoda kompresuje każdą wiadomość do zaledwie dwóch liczb. Pierwsza to ogólny wynik spamu, który sumuje, jak silnie spamowe słowa w wiadomości wskazują na problem. Druga to gęstość słów-kluczy spamu, mierząca, ile słów w wiadomości pochodzi ze słownika podejrzanych terminów. Te dwie wartości są skalowane między zerem a jedynką i używane jako jedyne wejścia do zwartego zestawu reguł, które opisują, jak różne kombinacje wyników powinny być interpretowane jako spam lub poczta bezpieczna, wraz z przypisanymi stopniami wiary.
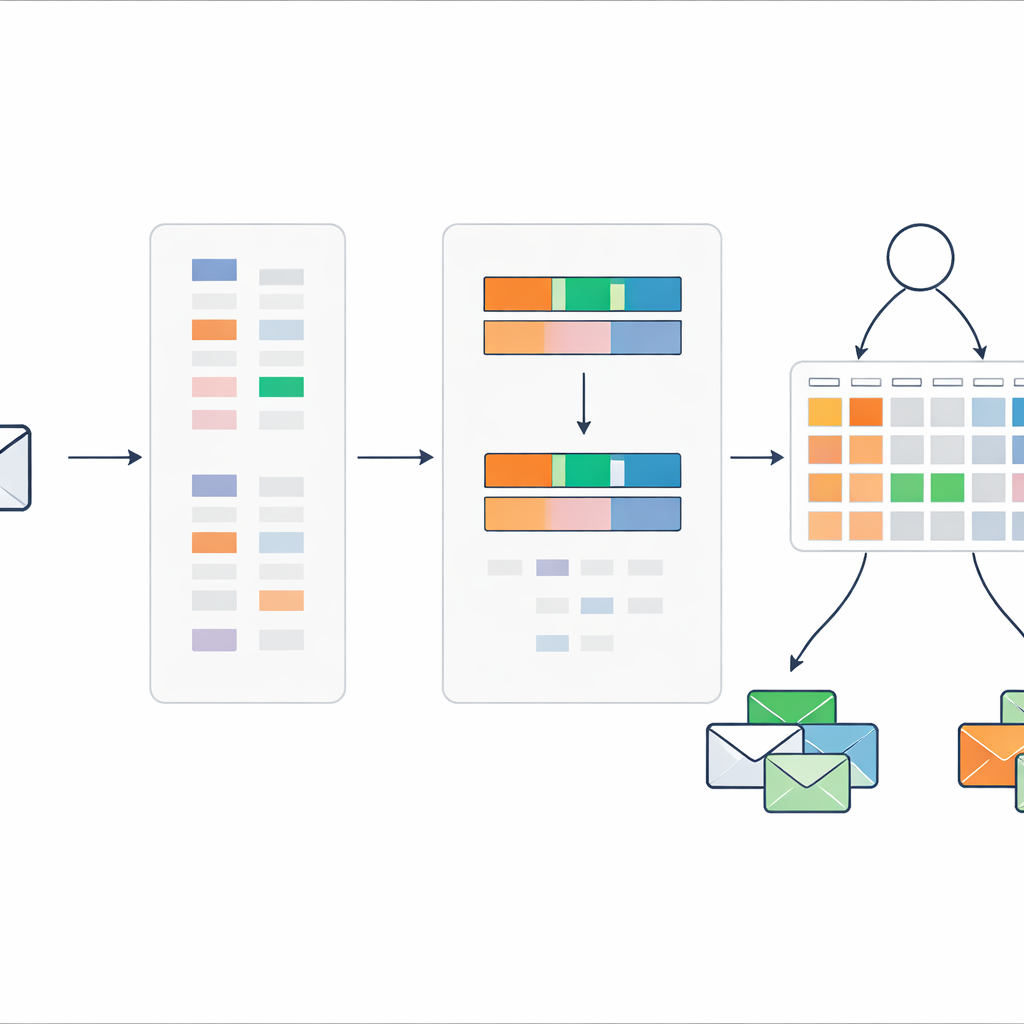
Reguły, które dostosowują się, ale pozostają zrozumiałe
System reguł zaczyna od wiedzy eksperckiej: na przykład wiadomość z wysokim wynikiem spamu i wysoką gęstością słów-kluczy spamu powinna niemal na pewno być spamem, podczas gdy sprzeczne sygnały wymagają bardziej ostrożnych ocen. Aby dopracować te początkowe ustawienia, autorzy stosują procedurę optymalizacji ewolucyjnej, która automatycznie dostosowuje wagi reguł i wartości wiary, zachowując jednocześnie logiczne ograniczenia. Pozwala to modelowi dostroić się do rzeczywistych danych bez utraty przejrzystej, opartej na regułach struktury. Każda końcowa decyzja nadal może być prześledzona przez niewielki zestaw czytelnych reguł i wartości wejściowych.
Weryfikacja podejścia na wiadomościach z prawdziwego świata
Zespół testuje swój model na dwóch publicznych zbiorach danych: powszechnie używanym zestawie wiadomości SMS oraz oddzielnym zbiorze oszukańczych e-maili. W obu przypadkach ograniczają się do zaledwie 200 oznaczonych przykładów — 100 spamów i 100 wiadomości normalnych — aby naśladować wczesny etap pojawienia się nowej fali spamu. W wielokrotnych rundach walidacji krzyżowej ich model osiąga dokładność około 91,5% na SMS-ach i 95,5% na e-mailach oszustw, przewyższając różne tradycyjne systemy uczenia maszynowego, uczenia głębokiego i logiki rozmytej testowane w tych samych warunkach ograniczonych danych. Nowa metoda punktacji cech okazuje się również kluczowa: gdy zostaje usunięta w badaniu ablacyjnym, wydajność zauważalnie spada, mimo że struktura reguł pozostaje niezmieniona.
Co to oznacza dla bezpieczniejszych skrzynek odbiorczych
Dla osób spoza specjalizacji kluczowy wniosek jest taki, że można zbudować filtr antyspamowy, który działa dobrze przy bardzo niewielkiej liczbie oznaczonych danych i jednocześnie „pokazuje swoje rozumowanie” w sposób zrozumiały dla ludzi. Poprzez sprowadzenie złożonego tekstu do zaledwie dwóch znaczących sygnałów, a następnie zastosowanie zwartego systemu reguł, który można sprawdzić i dopracować, proponowany model oferuje zarówno silne wczesne wykrywanie nowego spamu, jak i jasne wyjaśnienia swoich decyzji. W praktyce może to pomóc dostawcom poczty i zespołom bezpieczeństwa szybciej reagować na pojawiające się kampanie oszustw, zmniejszyć nadmierne poleganie na nieprzejrzystych modelach czarnej skrzynki i dać ekspertom wyraźniejszy wgląd w to, jak ewoluują taktyki spamerów.
Cytowanie: Yang, X., Zhou, W., Duan, X. et al. A spam detection model based on the discriminative TF-IDF belief rule base. Sci Rep 16, 11962 (2026). https://doi.org/10.1038/s41598-026-42223-6
Słowa kluczowe: wykrywanie spamu, bezpieczeństwo poczty, klasyfikacja tekstu, interpretowalna sztuczna inteligencja, uczenie przy małej liczbie próbek