Clear Sky Science · ar
نموذج اكتشاف الرسائل المزعجة مبني على قاعدة قواعد المعتقد TF‑IDF التمييزية
لماذا تهم الفلاتر الذكية للجميع
تمتلئ صناديق البريد الوارد لدينا برسائل غير مرغوب فيها تحاول بيع منتجات مزيفة أو سرقة كلمات المرور أو خداعنا لإرسال أموال. غالبًا ما تظهر موجات الرسائل الخطرة بمظهر جديد ومختلف، وتصل قبل أن تتمكن الشركات من جمع أمثلة كافية لتدريب أدوات الكشف التقليدية. تقدم هذه الورقة نوعًا جديدًا من مرشحات الرسائل المزعجة يمكنه العمل بشكل جيد حتى عند وجود عدد قليل من الرسائل المشبوهة، مع تقديم تفسير واضح لسبب تصنيفه رسالة على أنها مزعجة أو آمنة.
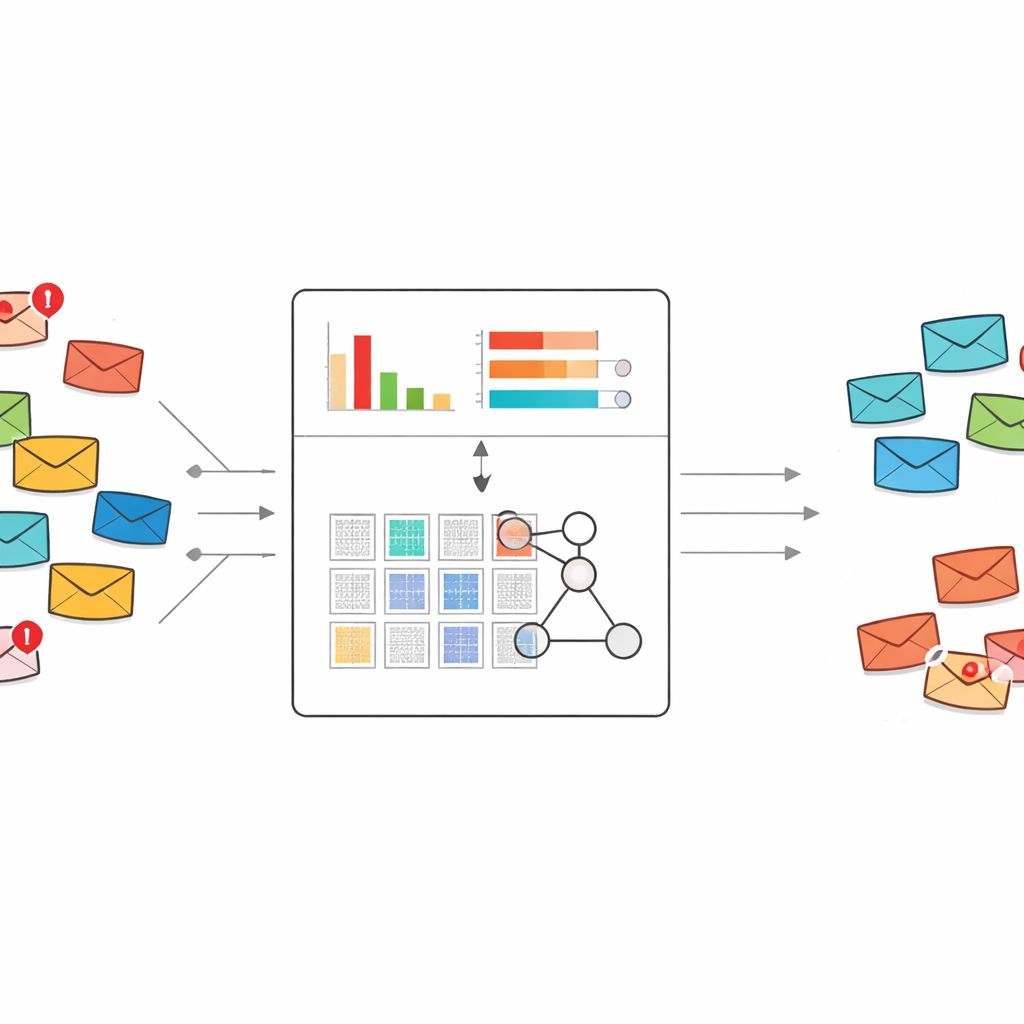
نهج جديد لقراءة ما تقوله الرسائل المزعجة
تعتمد معظم مرشحات الرسائل اليوم إما على التعلم الآلي التقليدي أو التعلم العميق. عادة ما تحتاج هذه الأنظمة إلى آلاف أو ملايين الرسائل المصنفة وقوائم ضخمة من ميزات الكلمات للتعلم منها. قد تكون قوية، لكن عندما يظهر أسلوب احتيال جديد ويتوفر عدد قليل من الأمثلة فقط، غالبًا ما تكافح أو تتصرف كصندوق أسود. يبني المؤلفون بدلاً من ذلك على إطار نظام خبير يسمى قاعدة قواعد المعتقد، التي تمثل المعرفة كقواعد "إن — فـ" قابلة للقراءة البشرية ومؤهلة بطبيعتها للتعلم من مجموعات بيانات صغيرة.
استخراج الكلمات التي تكشف حقيقة الرسائل المزعجة
التحدي المباشر هو أن نص البريد الخام يحتوي على عدد هائل من الكلمات والعبارات المحتملة. إدخال كل هذه إلى نظام قواعد سيؤدي إلى انفجار في عدد القواعد غير القابل للإدارة. لتجنب ذلك، يعيد المؤلفون تصميم مخطط وزن النص الكلاسيكي المعروف بـ TF–IDF بحيث لا يلتقط فقط مدى أهمية الكلمة داخل مستند، بل إلى أي مدى تميل هذه الكلمة نحو كونها مؤشرًا على الرسائل المزعجة بدلاً من البريد العادي. تركز طريقتهم "TF–IDF التمييزية" أولاً على الرسائل المزعجة لبناء مفردات من الكلمات والعبارات الدالة، ثم تقوّم كل مصطلح بحسب ما إذا كان يظهر أكثر في الرسائل المزعجة أو في البريد العادي، وتحتفظ فقط بتلك التي تميل بوضوح نحو الرسائل المزعجة.
تلخيص كل رسالة إلى إشارتين بسيطتين
بدلاً من تمرير مئات أو آلاف مؤشرات الكلمات إلى نظام القواعد، تضغط الطريقة كل رسالة إلى رقمين فقط. الأول هو درجة إجمالية للرسائل المزعجة، تجمع مدى ميل الكلمات المشبوهة في تلك الرسالة نحو الخطر. الثاني هو كثافة كلمات الرسائل المزعجة، التي تقيس عدد الكلمات في الرسالة المأخوذة من المفردات المشكوك فيها. تُقاس هاتان القيمتان بين الصفر وواحد وتستخدمان كمدخلين وحيدين لمجموعة مضغوطة من القواعد التي تصف كيفية تفسير تركيبات الدرجات المختلفة كبريد مزعج أو آمن، مع درجات اعتقاد مرتبطة.
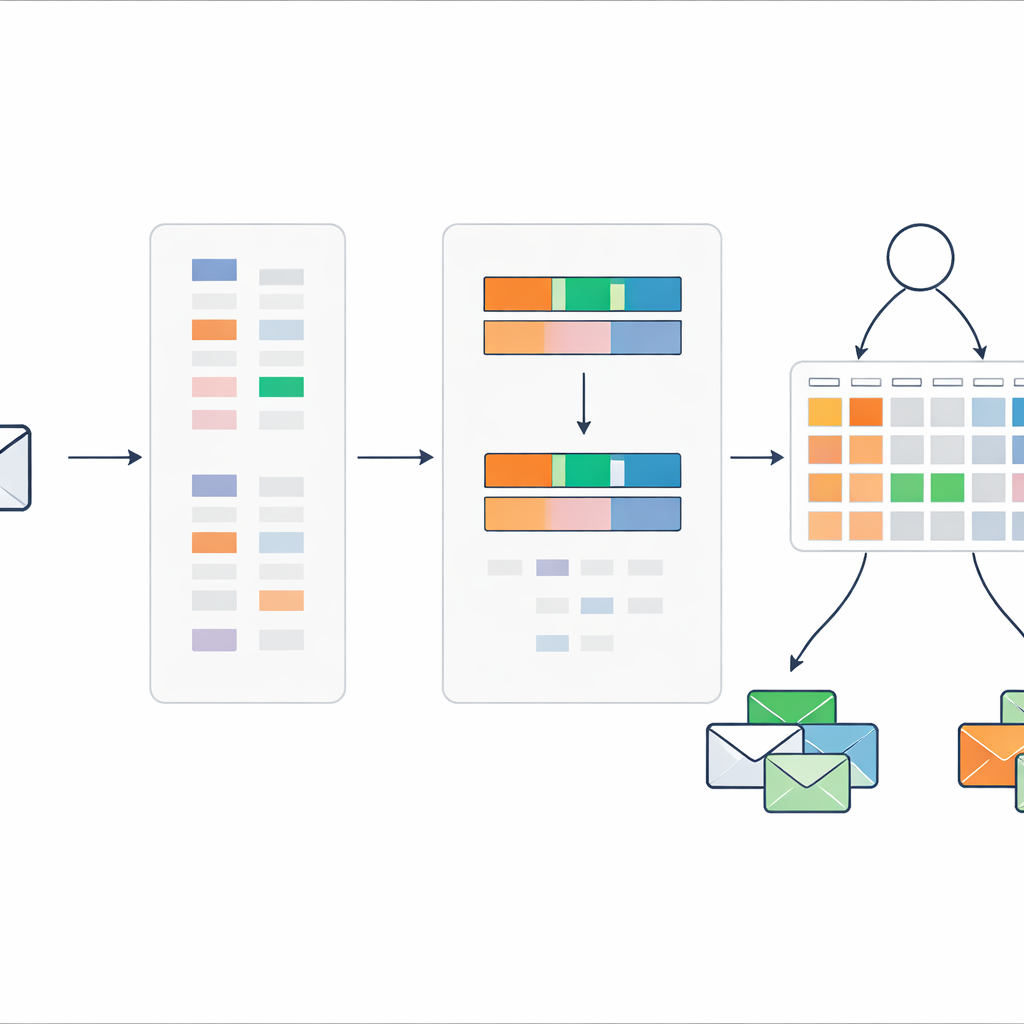
قواعد تتكيف وتظل مفهومة
يبدأ نظام القواعد من معرفة خبراء: على سبيل المثال، يجب أن تكون الرسالة التي تجمع بين درجة عالية للرسائل المزعجة وكثافة عالية لكلمات الرسائل المزعجة على الأرجح رسالة مزعجة، بينما تستدعي الإشارات المتضاربة أحكامًا أكثر حذرًا. لتعديل هذه الإعدادات الأولية، يستخدم المؤلفون إجراء تحسين تطوريًا يضبط تلقائيًا أوزان القواعد وقيم المعتقد مع احترام القيود المنطقية. هذا يسمح للنموذج بضبط نفسه على بيانات حقيقية دون فقدان هيكله الشفاف القائم على القواعد. يمكن تتبع كل قرار نهائي عبر مجموعة صغيرة من القواعد القابلة للقراءة البشرية ودرجات المدخلات.
إثبات النهج على رسائل العالم الحقيقي
يختبر الفريق نموذجه على مجموعتي بيانات عامتين: مجموعة مُستخدمة على نطاق واسع من رسائل نصية قصيرة (SMS) ومجموعة منفصلة من رسائل البريد الاحتيالية. في كل حالة يقتصرون على 200 مثال مُصنَّف فقط — 100 رسالة مزعجة و100 رسالة عادية — لمحاكاة المرحلة المبكرة من تفشي رسائل مزعجة جديدة. عبر جولات متعددة من التحقق المتقاطع، يصل نموذجهم إلى دقة تقارب 91.5% على رسائل SMS و95.5% على رسائل الاحتيال عبر البريد الإلكتروني، متفوقًا على مجموعة من أنظمة التعلم الآلي التقليدي والتعلم العميق والمنطق الضبابي التي اختُبرت تحت نفس شروط قلة البيانات. كما تثبت طريقة تسجيل الميزات الجديدة أهميتها: عندما تُزال في دراسة إلغاء المكون، تنخفض الأداء بشكل ملحوظ رغم بقاء هيكل القواعد كما هو.
ما يعنيه هذا لصناديق بريد أكثر أمانًا
بالنسبة لغير المتخصصين، النتيجة الأساسية هي أنه من الممكن بناء مرشح رسائل مزعجة يعمل جيدًا ببيانات موسومة قليلة جدًا ولا يزال "يوضح عمله" بطريقة يمكن للناس فهمها. من خلال تقطير النص المعقد إلى إشارتين ذات معنى فقط، ثم تطبيق نظام قواعد مضغوط يمكن تفقده وتنقيحه، يقدم النموذج المقترح كلاً من كشف مبكر قوي للرسائل المزعجة الجديدة وتفسيرات واضحة لقراراته. عمليًا، قد يساعد ذلك مزودي البريد الإلكتروني وفرق الأمن على الاستجابة بسرعة أكبر لحملات الاحتيال الناشئة، وتقليل الاعتماد المفرط على نماذج الصناديق السوداء، ومنح الخبراء رؤية أوضح حول كيفية تطور تكتيكات الرسائل المزعجة.
الاستشهاد: Yang, X., Zhou, W., Duan, X. et al. A spam detection model based on the discriminative TF-IDF belief rule base. Sci Rep 16, 11962 (2026). https://doi.org/10.1038/s41598-026-42223-6
الكلمات المفتاحية: اكتشاف الرسائل المزعجة, أمن البريد الإلكتروني, تصنيف النصوص, الذكاء الاصطناعي القابل للتفسير, التعلّم من عينات صغيرة