Clear Sky Science · nl
Een spamdetectiemodel gebaseerd op de discriminatieve TF-IDF belief rule base
Waarom slimere spamfilters voor iedereen belangrijk zijn
Onze inboxen lopen vol met ongevraagde berichten die nepproducten willen verkopen, wachtwoorden proberen te stelen of ons willen misleiden om geld te sturen. De gevaarlijkste golven van spam zien er vaak nieuw en afwijkend uit en verschijnen voordat bedrijven genoeg voorbeelden hebben verzameld om traditionele detectietools te trainen. Dit artikel presenteert een nieuw soort spamfilter dat goed kan werken zelfs wanneer slechts een klein aantal verdachte berichten beschikbaar is, en dat bovendien duidelijk uitlegt waarom het een bericht als spam of veilig markeert.
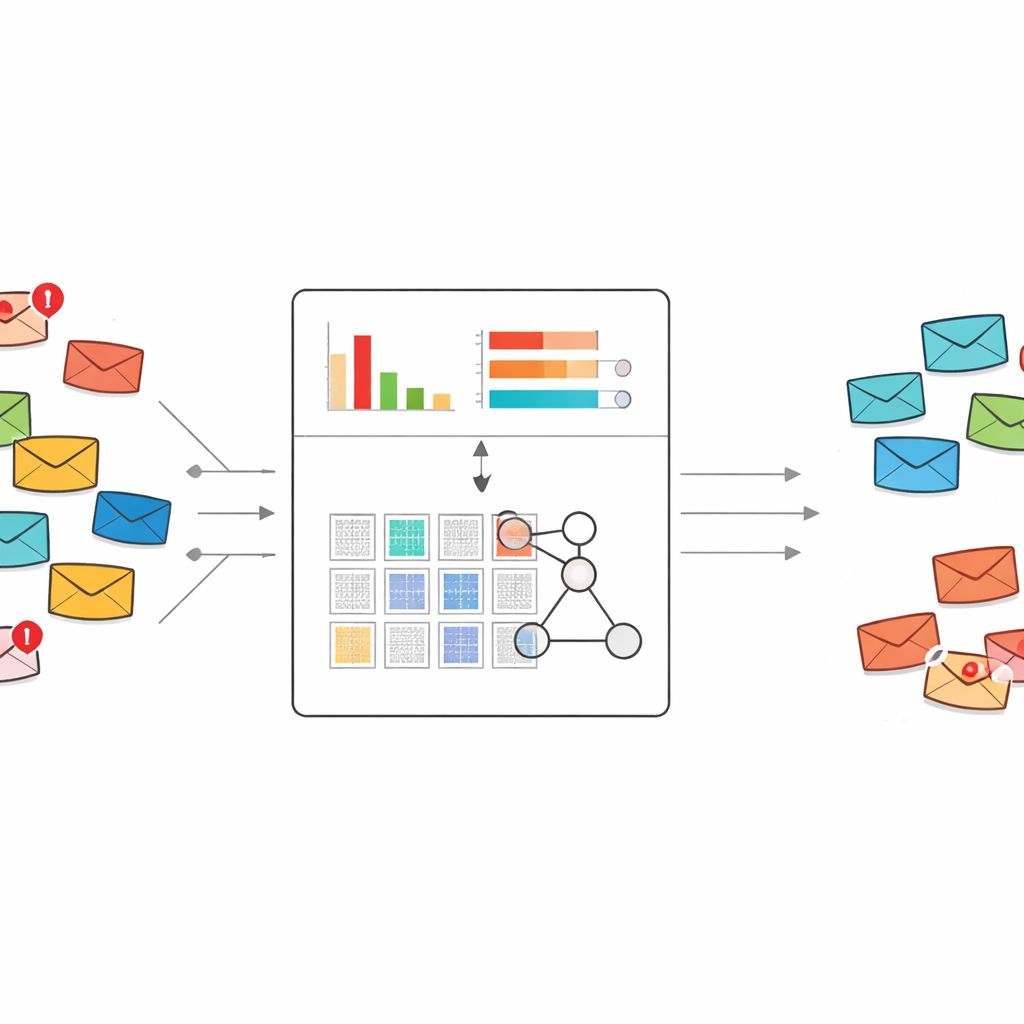
Een frisse manier om te lezen wat spam zegt
De meeste spamfilters van vandaag vertrouwen op standaard machine learning of deep learning. Deze systemen hebben doorgaans duizenden of miljoenen gelabelde e-mails en enorme lijsten met woordkenmerken nodig om van te leren. Ze kunnen krachtig zijn, maar wanneer er een nieuwe oplichterstijl verschijnt en slechts enkele voorbeelden beschikbaar zijn, hebben ze vaak moeite of gedragen ze zich als een black box. De auteurs bouwen in plaats daarvan voort op een expert-systeemkader genaamd belief rule base, dat kennis representeert als voor mensen leesbare "als–dan"-regels en van nature geschikt is om te leren van kleine datasets.
De woorden eruit pikken die echt verraden dat het spam is
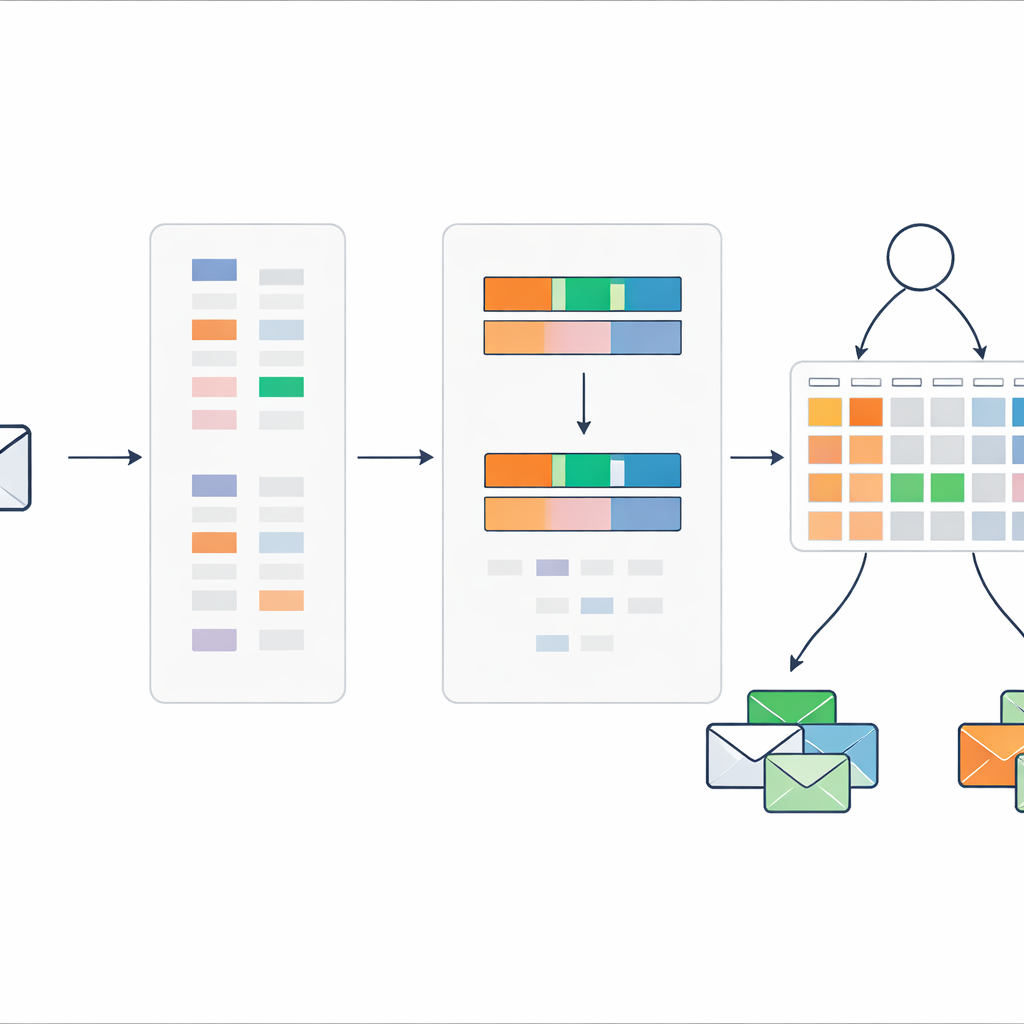
Een directe uitdaging is dat ruwe e-mailtekst een enorme hoeveelheid mogelijke woorden en woordgroepen bevat. Al deze in een regelsysteem stoppen zou leiden tot een onhandelbaar groot aantal regels. Om dit te vermijden, herontwerpen de auteurs een klassieke tekstwegingstechniek bekend als TF–IDF zodat die niet alleen vastlegt hoe belangrijk een woord is voor een document, maar hoe sterk het naar spam neigt in plaats van normale mail. Hun "discriminatieve TF–IDF"-methode richt zich eerst alleen op spamberichten om een vocabulaire van veelzeggende woorden en korte zinnen op te bouwen. Vervolgens scoort het elke term op basis van of die vaker in spam of in normale mail voorkomt, en behoudt alleen die termen die duidelijk naar spam neigen.
Elk bericht terugbrengen tot twee eenvoudige signalen
In plaats van honderden of duizenden woordindicatoren naar het regelsysteem te sturen, comprimeert de methode elk bericht tot slechts twee getallen. De eerste is een algemene spamscore, die optelt hoe sterk de spam-neigende woorden in dat bericht naar problemen wijzen. De tweede is de dichtheid van spamzoekwoorden, die meet hoeveel van de woorden in het bericht afkomstig zijn uit het verdachte vocabulaire. Deze twee waarden worden geschaald tussen nul en één en gebruikt als de enige inputs voor een compact stel regels dat beschrijft hoe verschillende combinaties van scores moeten worden geïnterpreteerd als spam of veilige mail, samen met bijbehorende graden van vertrouwen.
Regels die zich aanpassen maar begrijpelijk blijven
Het regelsysteem begint bij expertkennis: bijvoorbeeld, een bericht met zowel een hoge spamscore als een hoge dichtheid aan spamzoekwoorden zal vrijwel zeker spam zijn, terwijl tegenstrijdige signalen om voorzichtiger oordelen vragen. Om deze begininstellingen te verfijnen gebruiken de auteurs een evolutionaire optimalisatieprocedure die automatisch regelgewichten en belief-waarden aanpast binnen logische beperkingen. Dit stelt het model in staat zichzelf op echte data af te stemmen zonder zijn transparante, regelgebaseerde structuur te verliezen. Elke definitieve beslissing is nog steeds te herleiden via een klein aantal voor mensen leesbare regels en inputscores.
De aanpak bewijzen op berichten uit de echte wereld
Het team test hun model op twee openbare datasets: een veelgebruikte verzameling SMS-teksten en een aparte set frauduleuze e-mails. In beide gevallen beperken ze zich tot slechts 200 gelabelde voorbeelden — 100 spam en 100 normale berichten — om het vroege stadium van een nieuwe spamaanval na te bootsen. Over meerdere ronden van cross-validatie behaalt hun model nauwkeurigheden van ongeveer 91,5% op SMS en 95,5% op frauduleuze e-mails, en overtreft daarmee een reeks traditionele machine learning-, deep learning- en fuzzy-logic-systemen die onder dezelfde datalage condities werden getest. De nieuwe methode voor feature-scoren blijkt ook essentieel: wanneer deze wordt verwijderd in een ablatiestudie daalt de prestatie merkbaar, ook al blijft de regelsstructuur hetzelfde.
Wat dit betekent voor veiligere inboxen
Voor niet-specialisten is de kernresultaat dat het mogelijk is een spamfilter te bouwen dat goed werkt met heel weinig gelabelde data en toch "zijn werk toont" op een manier die mensen kunnen begrijpen. Door complexe tekst te destilleren tot slechts twee betekenisvolle signalen en vervolgens een compact regelsysteem toe te passen dat geïnspecteerd en verfijnd kan worden, biedt het voorgestelde model zowel sterke vroege detectie van nieuwe spam als heldere verklaringen voor zijn keuzes. Praktisch gezien kan dit e-mailproviders en beveiligingsteams helpen sneller te reageren op opkomende oplichtingscampagnes, overmatig vertrouwen op ondoorzichtige black-boxmodellen verminderen en experts beter inzicht geven in hoe spamtactieken zich ontwikkelen.
Bronvermelding: Yang, X., Zhou, W., Duan, X. et al. A spam detection model based on the discriminative TF-IDF belief rule base. Sci Rep 16, 11962 (2026). https://doi.org/10.1038/s41598-026-42223-6
Trefwoorden: spamdetectie, e-mailbeveiliging, tekstclassificatie, interpreteerbare AI, leren met kleine steekproeven