Clear Sky Science · pt
Um modelo de detecção de spam baseado na base de regras de crença TF-IDF discriminativa
Por que filtros de spam mais inteligentes importam para todos
Nossas caixas de entrada estão inundadas por mensagens indesejadas que tentam vender produtos falsos, roubar senhas ou nos enganar para enviar dinheiro. As ondas de spam mais perigosas costumam parecer novas e diferentes, chegando antes que empresas tenham exemplos suficientes para treinar ferramentas de detecção tradicionais. Este artigo apresenta um novo tipo de filtro de spam que pode funcionar bem mesmo quando apenas um pequeno número de mensagens suspeitas foi observado, além de explicar de forma clara por que marca uma mensagem como spam ou segura.
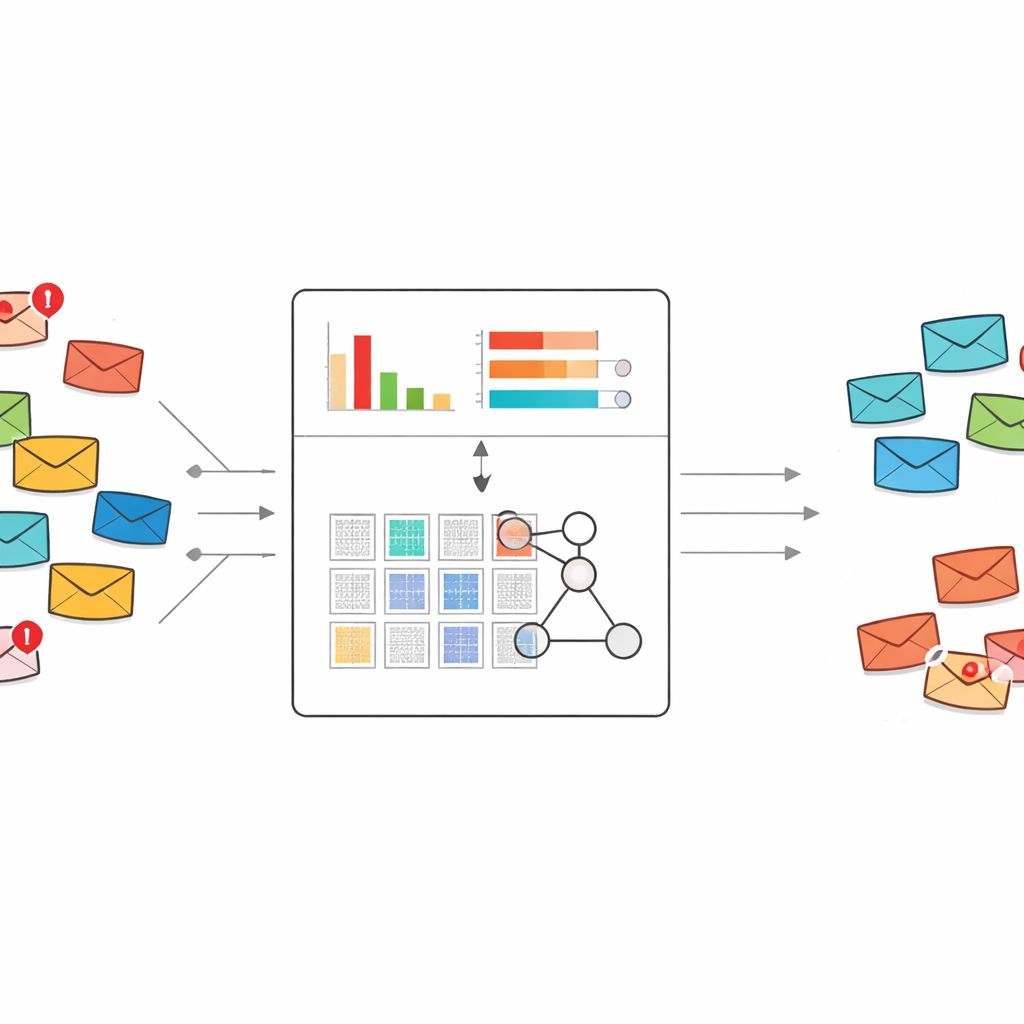
Uma nova maneira de ler o que o spam está dizendo
A maioria dos filtros de spam atuais baseia-se em aprendizado de máquina padrão ou aprendizado profundo. Esses sistemas geralmente exigem milhares ou milhões de e-mails rotulados e enormes listas de palavras como características para aprender. Podem ser poderosos, mas quando surge um novo estilo de golpe e há apenas poucos exemplos disponíveis, frequentemente têm dificuldades ou agem como uma caixa-preta. Os autores, em vez disso, partem de um quadro de sistema especialista chamado base de regras de crença, que representa o conhecimento como regras "se-então" legíveis por humanos e é naturalmente adequado para aprender a partir de conjuntos de dados pequenos.
Selecionando as palavras que realmente denunciam o spam
Um desafio direto é que o texto bruto de e-mail contém um número enorme de palavras e frases possíveis. Alimentar tudo isso em um sistema de regras explodiria em um número incontrolável de regras. Para evitar isso, os autores redesenham um esquema clássico de ponderação de texto conhecido como TF–IDF para que ele não capture apenas quão importante uma palavra é para um documento, mas o quanto ela tende para spam em vez de correio normal. Seu método de "TF–IDF discriminativa" foca primeiro apenas nas mensagens de spam para construir um vocabulário de palavras e frases curtas reveladoras. Em seguida, pontua cada termo de acordo com se aparece mais em spam ou em correio normal, e conserva apenas aqueles que se inclinam de forma clara para o spam.
Reduzindo cada mensagem a dois sinais simples
Em vez de passar centenas ou milhares de indicadores de palavras para o sistema de regras, o método comprime cada mensagem em apenas dois números. O primeiro é uma pontuação global de spam, que soma o quanto as palavras com viés para spam naquela mensagem apontam para problema. O segundo é uma densidade de palavras-chave de spam, medindo quantas das palavras na mensagem pertencem ao vocabulário suspeito. Esses dois valores são escalados entre zero e um e usados como as únicas entradas para um conjunto compacto de regras que descrevem como diferentes combinações de pontuações devem ser interpretadas como spam ou correio seguro, juntamente com graus de crença associados.
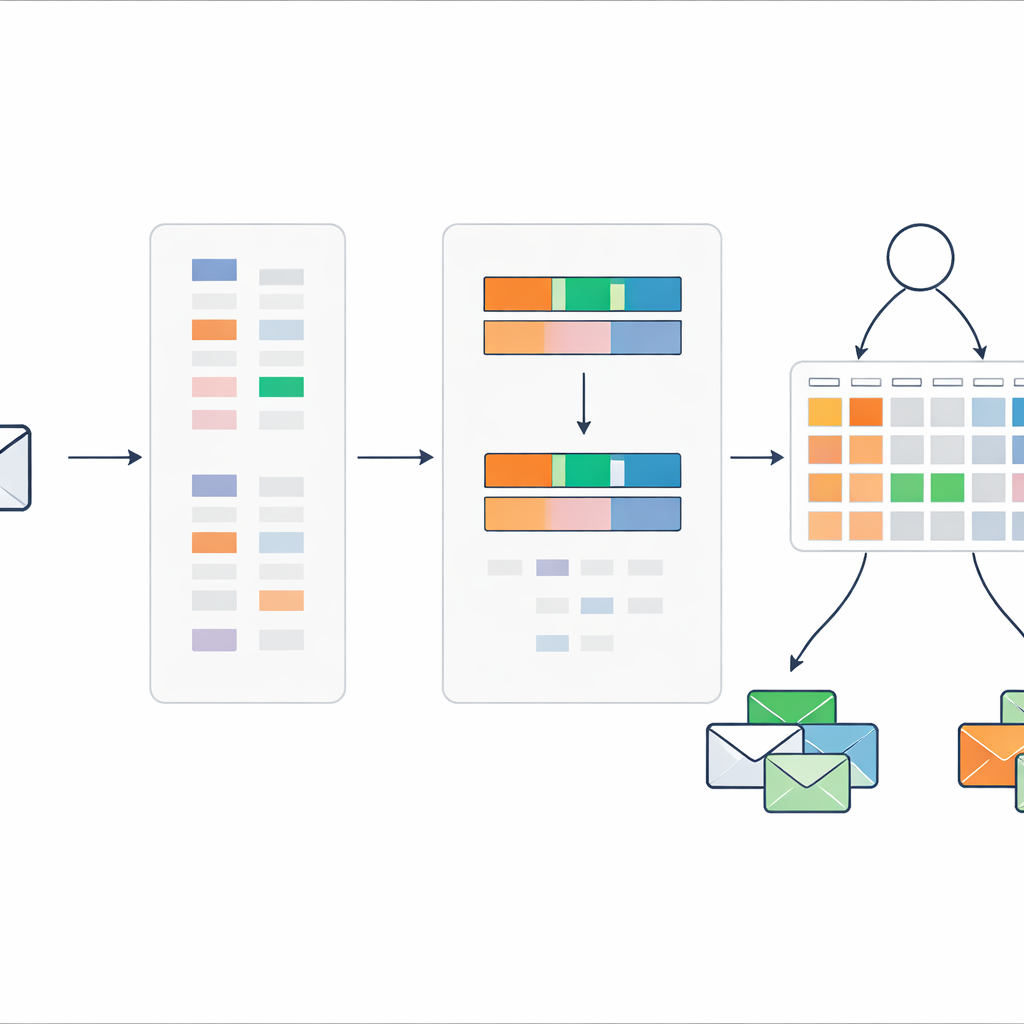
Regras que se adaptam mas permanecem compreensíveis
O sistema de regras começa a partir do conhecimento de especialistas: por exemplo, uma mensagem com alta pontuação de spam e alta densidade de palavras-chave de spam deveria ser quase certamente spam, enquanto sinais conflitantes exigem julgamentos mais cautelosos. Para refinar essas configurações iniciais, os autores usam um procedimento de otimização evolutiva que ajusta automaticamente pesos das regras e valores de crença respeitando restrições lógicas. Isso permite que o modelo se ajuste aos dados reais sem perder sua estrutura transparente baseada em regras. Cada decisão final ainda pode ser rastreada por um pequeno conjunto de regras legíveis por humanos e pontuações de entrada.
Comprovando a abordagem em mensagens do mundo real
A equipe testa seu modelo em dois conjuntos de dados públicos: uma coleção amplamente usada de mensagens de texto SMS e um conjunto separado de e-mails fraudulentos. Em cada caso, limitam-se a apenas 200 exemplos rotulados — 100 spam e 100 mensagens normais — para imitar o estágio inicial de um novo surto de spam. Em várias rodadas de validação cruzada, seu modelo alcança acurácias de cerca de 91,5% em SMS e 95,5% em e-mails fraudulentos, superando uma série de sistemas de aprendizado de máquina tradicionais, aprendizado profundo e lógica fuzzy testados nas mesmas condições de poucos dados. O novo método de pontuação de características também se mostra essencial: quando é removido em um estudo de ablação, o desempenho cai de forma perceptível, embora a estrutura de regras permaneça a mesma.
O que isso significa para caixas de entrada mais seguras
Para não especialistas, o resultado-chave é que é possível construir um filtro de spam que funciona bem com muito poucos dados rotulados e ainda "mostra seu trabalho" de um modo que as pessoas podem entender. Ao destilar textos complexos em apenas dois sinais significativos e então aplicar um sistema de regras compacto que pode ser inspecionado e refinado, o modelo proposto oferece tanto forte detecção precoce de novos spams quanto explicações claras para suas escolhas. Em termos práticos, isso pode ajudar provedores de e-mail e equipes de segurança a reagirem mais rápido a campanhas de golpe emergentes, reduzir a dependência excessiva em modelos opacos de caixa-preta e dar aos especialistas uma visão mais clara de como as táticas de spam estão evoluindo.
Citação: Yang, X., Zhou, W., Duan, X. et al. A spam detection model based on the discriminative TF-IDF belief rule base. Sci Rep 16, 11962 (2026). https://doi.org/10.1038/s41598-026-42223-6
Palavras-chave: detecção de spam, segurança de e-mail, classificação de texto, IA interpretável, aprendizado com poucos exemplos