Clear Sky Science · sv
Neurala nätverksmodeller vs. MT‑utvärderingsmått: en jämförelse mellan två tillvägagångssätt för automatiserad bedömning av informationsfidelitet vid konsekutiv tolkning
Varför denna forskning betyder något för vanliga språkbrukare
När du lyssnar på ett tal som tolkats från ett språk till ett annat förutsätter du att kärnbudskapet överlevt resan. Att kontrollera denna ”fidelitet” har länge krävt expertbedömningar av människor, vilket är långsamt och dyrt. Denna studie undersöker om modern artificiell intelligens kan hjälpa till att bedöma hur korrekt en tolk återgett informationen, och därigenom potentiellt göra språktjänster rättvisare, billigare och enklare att kvalitetsgranska i större skala.
Att förstå trogen tolkning
Tolkningskvalitet har många dimensioner, men yrkesverksamma är överväldigande ense om att informationsfidelitet – hur fullständigt och korrekt betydelsen förts över – är det viktigaste. Traditionellt lyssnar experter på originaltalet och den tolkade versionen, eller jämför tolkningen med en ideal skriven version, och poängsätter hur väl idéer, kopplingar mellan idéer och talarens ton bevarats. Dessa metoder är rika och nyanserade, men kräver högt utbildade personer som spenderar mycket tid på att spela upp inspelningar, växla mellan språk och göra finmaskiga bedömningar. Som en följd används detaljerade mänskliga bedömningar oftast i provsituationer eller forskning, inte i vardaglig träning och storskalig kvalitetskontroll.
Från översättningsmätstickor till smarta modeller
För att avlasta mänskliga bedömare har forskare lånat verktyg från maskinöversättning, där datorprogram jämför ett systems output med flera betrodda mänskliga översättningar. Klassiska mått som BLEU och METEOR letar efter överlappande ordmönster mellan det som sagts och en uppsättning referensversioner och ger ett numeriskt värde. De fungerar bäst när flera högkvalitativa referensöversättningar finns tillgängliga, men sådana referenser är kostsamma att producera, och ord‑för‑ord‑överensstämmelse missar ofta den större meningen, särskilt mellan strukturellt olika språk som engelska och kinesiska.
Hur studien testade människor och maskiner
Denna forskning fokuserade på konsekutiv tolkning mellan engelska och kinesiska utförd av blivande tolkar. Författarna valde tre provtolkningar som representerade hög, medel och låg kvalitet från en större uppsättning. De transkriberade både originaltalet på engelska och de kinesiska tolkningarna, rensade bort utfyllnadsord och kopplade ihop dem i 94 matchande meningspar. Två erfarna bedömare poängsatte sedan varje par för fidelitet – omfattande huvudidéer, hur idéer länkar ihop, stödjande detaljer samt talarens attityd och avsikt – och uppnådde mycket hög överensstämmelse sinsemellan. Parallellt beräknade forskarna automatiska poäng för varje mening med två familjer av verktyg: traditionella översättningsmått (BLEU och METEOR, baserade på flera reviderade maskinöversättningar av källtalet som referenser) och en uppsättning neurala modeller som mäter tvärspråklig likhet direkt mellan den engelska meningen och dess tolkade kinesiska version.
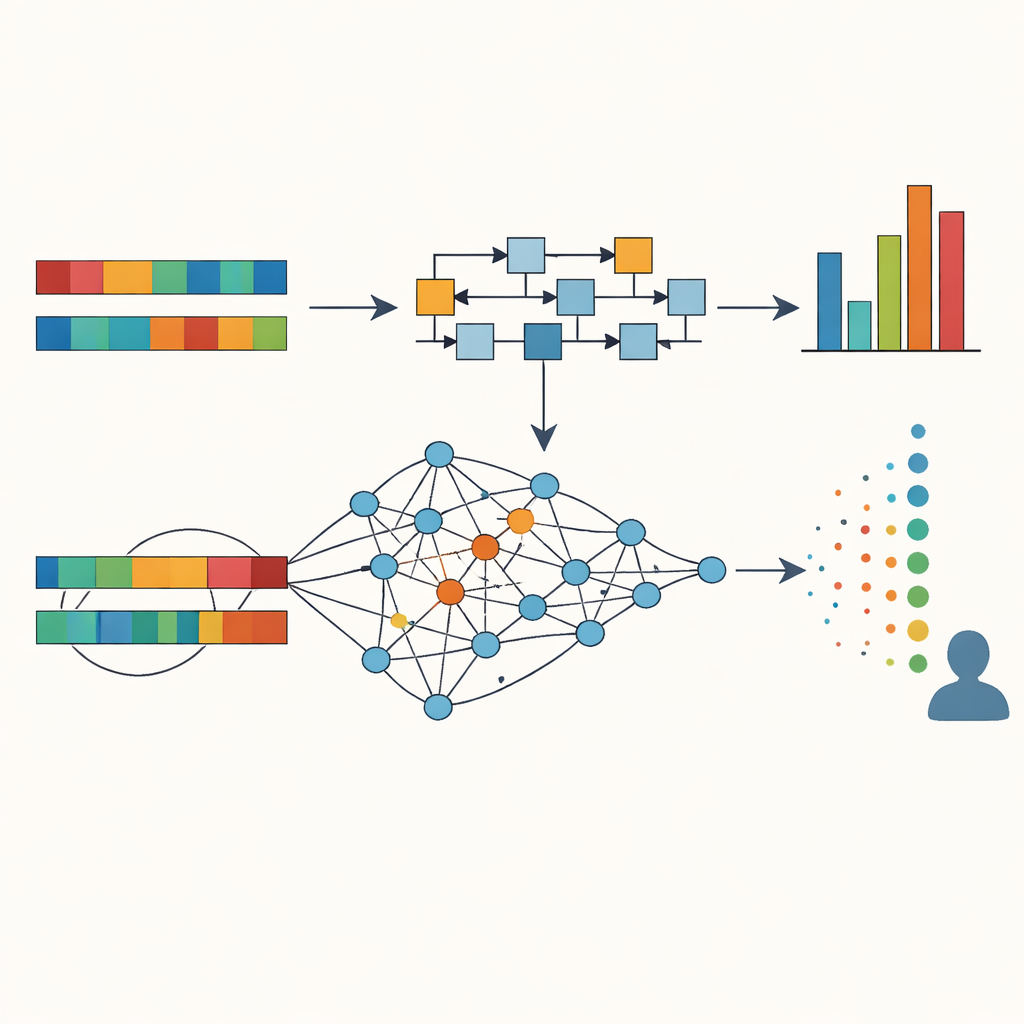
Vad maskinerna såg i tolkningarna
Studien jämförde maskinpoäng med de mänskliga bedömningarna med hjälp av statistiska korrelationer. Traditionella mått visade måttlig överensstämmelse: i genomsnitt följde deras poäng mänskliga omdömen rimligt väl (kring r = 0,45), där den enklaste BLEU‑varianten presterade något bättre än METEOR. Neurala tillvägagångssätt gjorde det bättre överlag, särskilt de som omvandlar meningar på olika språk till delade numeriska ”embeddingar” som fångar betydelse. En flerspråkig menings‑embeddingmodell kallad MUSE visade starkast överensstämmelse med människopoängen (r = 0,55), medan embeddingar från stora språkmodeller som GPT och LLaMA, och direkt GPT‑baserad poängsättning, också korrelerade måttligt väl. Viktigt är att dessa modeller hanterade naturlig omformulering bättre, till exempel när en kinesisk mening omorganiserade en engelsk mening men bevarade dess innebörd, där ordöverensstämmelsemått felaktigt kunde signalera misslyckande. Klusteranalyser, som grupperade tolkningarna efter deras maskinpoäng, visade att en kombination av flera mått kunde skilja låga, medel och höga kvaliteter på ett sätt som tydligt efterliknade mänskliga bedömningar.
Vad detta innebär för framtidens språkbeträdning
För icke‑specialister är slutsatsen att dagens AI redan kan ge användbara, om än inte perfekta, indikationer på hur troget en tolk framfört ett tal. Tvärspråkliga neurala modeller som jämför betydelser direkt, snarare än att bara räkna delade ord mot referenstexter, ligger närmast mänskliga bedömningar och kan identifiera goda tolkningar även när de använder annan formulerings- eller strukturoch ordning. Korrelationerna är tillräckligt starka för att vara statistiskt meningsfulla men inte för att helt ersätta expertbedömare. Istället föreslår studien att man använder en blandning av neurala poäng och traditionella mått som ett snabbt, lågkostnadsstöd i ”lågrisk”‑situationer: klassrumsfeedback, övningssessioner eller förberedande sortering vid storskaliga bedömningar. Mänsklig expertis förblir avgörande för höginsatsbeslut och för att fånga nyanser av stil, kontext och etik som dagens maskiner inte fullt ut kan greppa, men AI‑baserade verktyg är på väg att bli värdefulla samarbetspartners för att värna tolkningsfideliteten.
Citering: Wang, X., Wang, B. Neural network models vs. MT evaluation metrics: a comparison between two approaches to automated assessment of information fidelity in consecutive interpreting. Humanit Soc Sci Commun 13, 567 (2026). https://doi.org/10.1057/s41599-026-06562-z
Nyckelord: tolkningskvalitet, informationsfidelitet, utvärdering med neurala nätverk, maskinöversättningsmått, engelska–kinesiska tolkningar