Clear Sky Science · sv
Reversibel datainbäddning för 3D-meshmodeller baserad på spatial polygonprediktion och dubbel sortering
Gömma meddelanden i 3D-objekt
När 3D-modeller blir vanliga inom film, spel, teknik och medicin ökar behovet av att märka dem med ägandeskap och säkerhetskoder utan att förändra deras utseende. Denna artikel undersöker ett sätt att stoppa in hemliga informationsbitar i ett 3D-objekt, såsom en digital staty eller en maskindel, på ett sätt som håller ytan nästan visuellt identisk och även tillåter att den ursprungliga modellen kan återställas perfekt senare.
Varför reversibel inbäddning är viktig
Reversibel datainbäddning liknar att skriva med osynligt bläck som går att ta bort helt utan spår. Den låter skapare bädda in upphovsrätt, integritetskontroller eller anteckningar i digitalt material samtidigt som den garanterar att varje ursprunglig detalj kan återställas. Detta är avgörande inom områden som medicinska skanningar, försvar och digitala arkiv, där även små permanenta förändringar kan vara oacceptabla. Medan sådana tekniker är väl utvecklade för 2D-bilder är det svårare att överföra dem till 3D-modeller eftersom formerna är oregelbundna och sammanlänkade på komplexa sätt, vilket gör det svårt att dölja data utan att synligt störa geometrin.
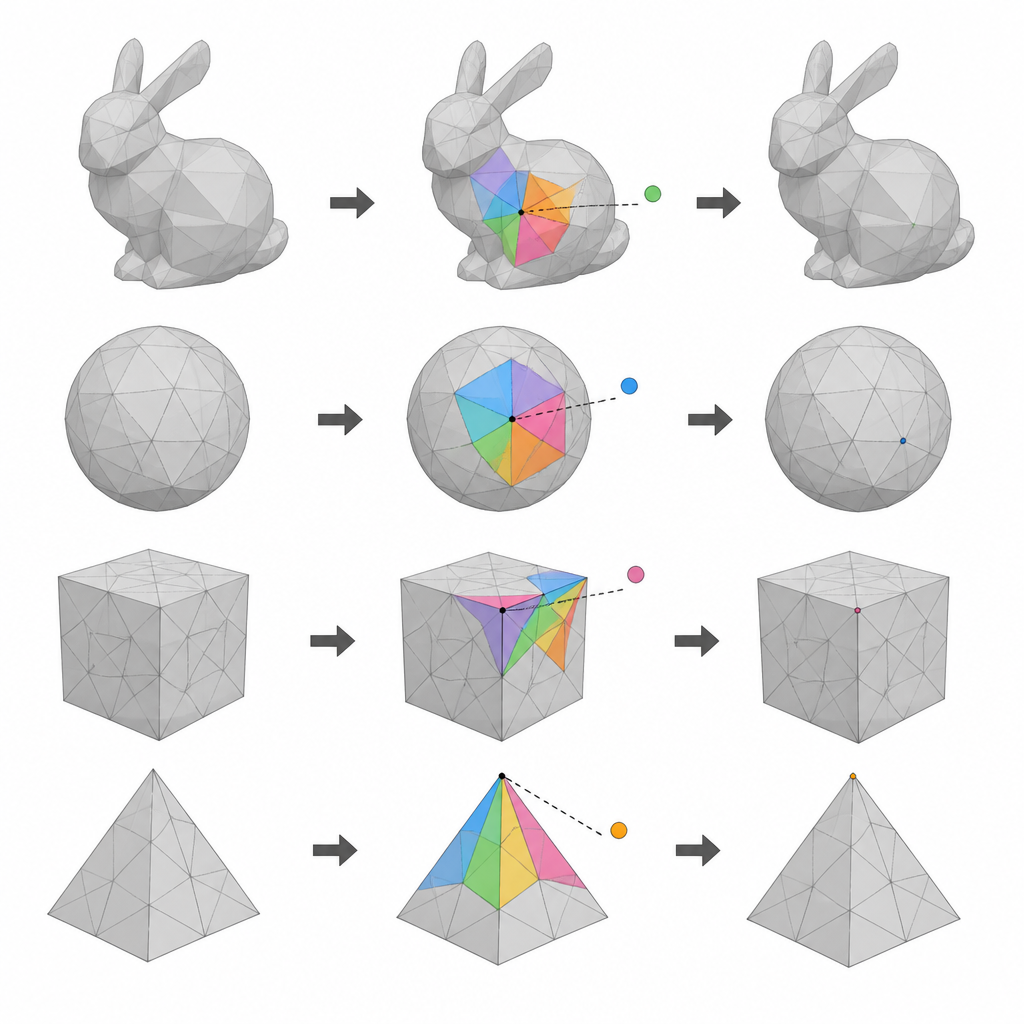
Använda lager av punkter på en 3D-yta
Författarna fokuserar på 3D-meshmodeller, som beskriver ett objekt som ett nätverk av punkter (vertexar) sammanfogade till små ytor. Deras första idé är att dela upp alla vertexar i tre grupper med hjälp av deras indexnummer. Två av dessa grupper turas om att fungera som kandidater för datainbäddning, medan den återstående gruppen förser referenspunkter som måste förbli orörda under varje pass. Genom att utföra två rundor av inbäddning och växla vilken grupp som används som kandidater respektive referenser kan metoden använda många fler vertexar för att bära data än tidigare endera passerande scheman, utan att tappa förmågan att återställa den ursprungliga modellen.
Låt intilliggande punkter förutsäga varandra
Den andra nyckelidén bygger på att närliggande punkter på en slät 3D-yta vanligtvis ligger nära en enkel genomsnittlig position. För varje kandidatvertex formar metoden en liten polygon av de flesta av dess grannar som för närvarande ingår i referensgruppen. Den förutsäger sedan var vertexen bör ligga baserat på dessa grannar och mäter den lilla skillnaden mellan prediktionen och den faktiska positionen. Dessa prediktionsfel bildar en kompakt, välbehållen mängd värden som kan försiktigt sträckas och förskjutas för att koda databitar. Eftersom de orörda grannarna förblir fasta kan samma prediktioner upprepas senare, vilket är avgörande både för att återvinna den dolda datan och för att återställa de ursprungliga koordinaterna.
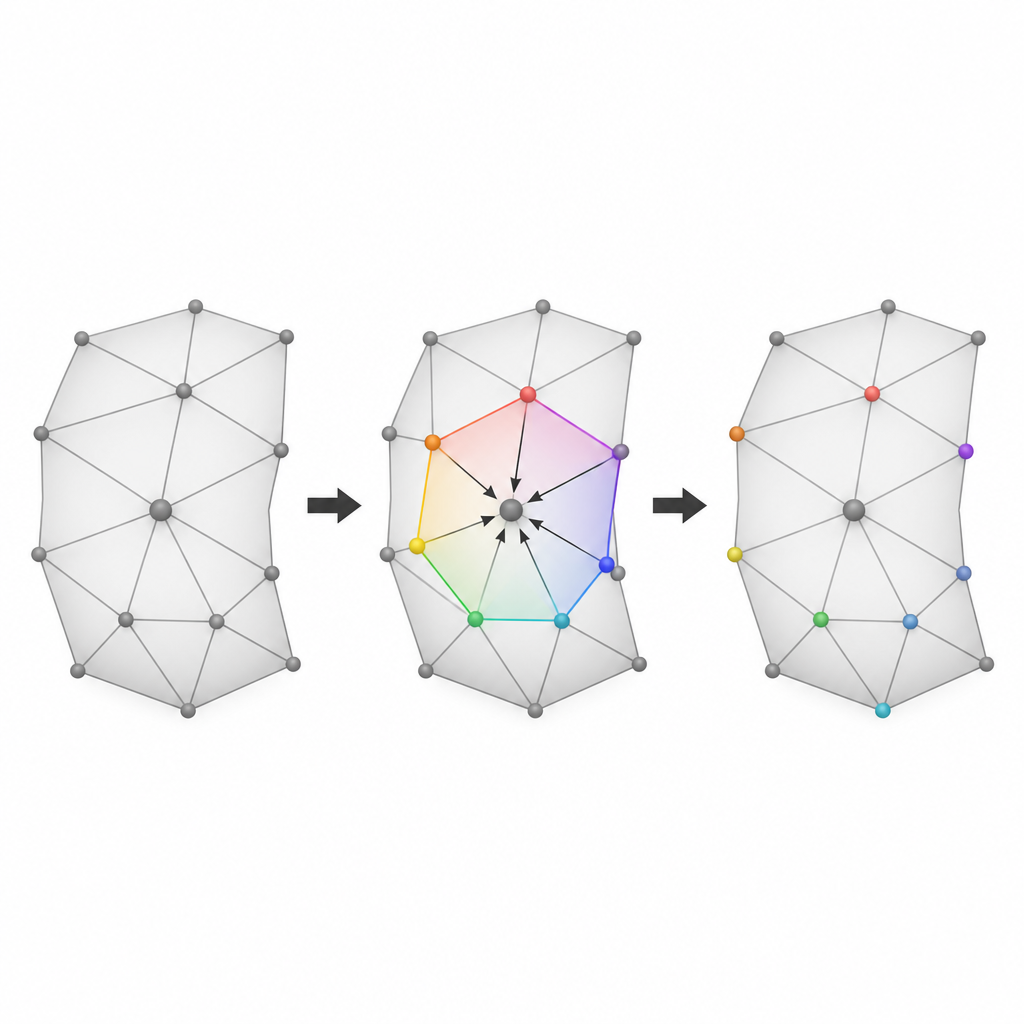
Välja de jämnaste ställena för att dölja data
Den tredje idén är att vara kräsna med var man börjar dölja. Författarna bedömer varje litet närområde runt en kandidatvertex efter hur slätt och regelbundet det är. Ett mått kontrollerar hur nära summan av dess vinklar ligger den för en plan polygon, medan ett annat kontrollerar hur lika längderna på dess kanter är. Dessa två poäng kombineras till ett enda prioriteringsvärde. Nätområden som är slätare och mer regelbundna tenderar att ge mindre prediktionsfel, så förskjutningar påverkar ytan mindre. Genom att sortera alla kandidatregioner enligt detta kombinerade släthetstema och bädda in data med start i de bästa regionerna håller metoden synlig förvrängning låg även vid inbäddning av stora informationsmängder.
Testning på vanliga 3D-modeller
Teamet utvärderade sin metod på välkända 3D-meshar som Stanford Bunny, en häst, en hand och en drake, och jämförde den med flera ledande tekniker. De mätte både hur många bitar som kunde lagras per vertex och hur mycket geometrin förändrades, med ett standardmått för signal-till-brus-förhållande. Deras tillvägagångssätt uppnådde högre datakapacitet än de andra samtidigt som formförändringen hölls liten, ofta med en förbättring av kvalitetsmåttet med flera decibel. Även vid lagring av mer än en och en halv bit per vertex förblev de flesta modeller visuellt nästan oförändrade, och metoden körde på sekunder till tiotals sekunder även för meshar med hundratusentals vertexar.
Vad detta betyder för digitalt 3D-innehåll
I praktiska termer visar detta arbete att det är möjligt att bädda in betydande mängder information i detaljerade 3D-modeller samtidigt som både utseende och möjligheten att återgå perfekt till originalet bevaras. Genom att kombinera lagerindelning av vertexar, grannebaserad prediktion och ett noggrant val av var inbäddning sker erbjuder metoden en bättre kompromiss mellan lagringskapacitet och formkvalitet än tidigare tillvägagångssätt. Det gör den till en lovande byggsten för säker märkning, integritetskontroller och annotering av den växande mängden 3D-innehåll.
Citering: Wang, Q., Zhang, Q., Song, X. et al. Reversible data hiding for 3D mesh models based on spatial polygon prediction and dual sorting. Sci Rep 16, 16097 (2026). https://doi.org/10.1038/s41598-026-47050-3
Nyckelord: reversibel datainbäddning, 3D-mesh, digital vattenmärkning, upphovsrättsskydd, geometrisk förvrängning