Clear Sky Science · de
Reversible Datenverbergung für 3D-Mesh-Modelle basierend auf räumlicher Polygonvorhersage und dualer Sortierung
Nachrichten in 3D-Objekten verbergen
Da 3D-Modelle in Filmen, Spielen, Ingenieurwesen und Medizin zunehmend verbreitet sind, wächst der Bedarf, sie mit Eigentumskennzeichen und Sicherheitscodes zu versehen, ohne ihr Aussehen zu verändern. Diese Arbeit untersucht eine Methode, geheime Informationsbits in ein 3D-Objekt – etwa eine digitale Statue oder ein Maschinenteil – einzubetten, sodass die Oberfläche optisch weitgehend unverändert bleibt und das ursprüngliche Modell später vollständig wiederhergestellt werden kann.
Warum reversible Verbergung wichtig ist
Reversible Datenverbergung ist wie das Schreiben mit unsichtbarer Tinte, die sich vollständig entfernen lässt, ohne Spuren zu hinterlassen. Sie erlaubt es Urheberrechtshinweise, Integritätsprüfungen oder Notizen in digitale Medien einzubetten und gleichzeitig zu garantieren, dass jedes ursprüngliche Detail wiederhergestellt werden kann. Das ist in Bereichen wie medizinischen Scans, Verteidigung und digitalen Archiven von entscheidender Bedeutung, wo selbst kleinste, permanente Veränderungen inakzeptabel sein können. Während solche Techniken für 2D-Bilder gut entwickelt sind, ist ihre Anwendung auf 3D-Modelle schwieriger, weil die Formen unregelmäßig und komplex verbunden sind, wodurch es heikel wird, Daten zu verbergen, ohne die Geometrie sichtbar zu stören.
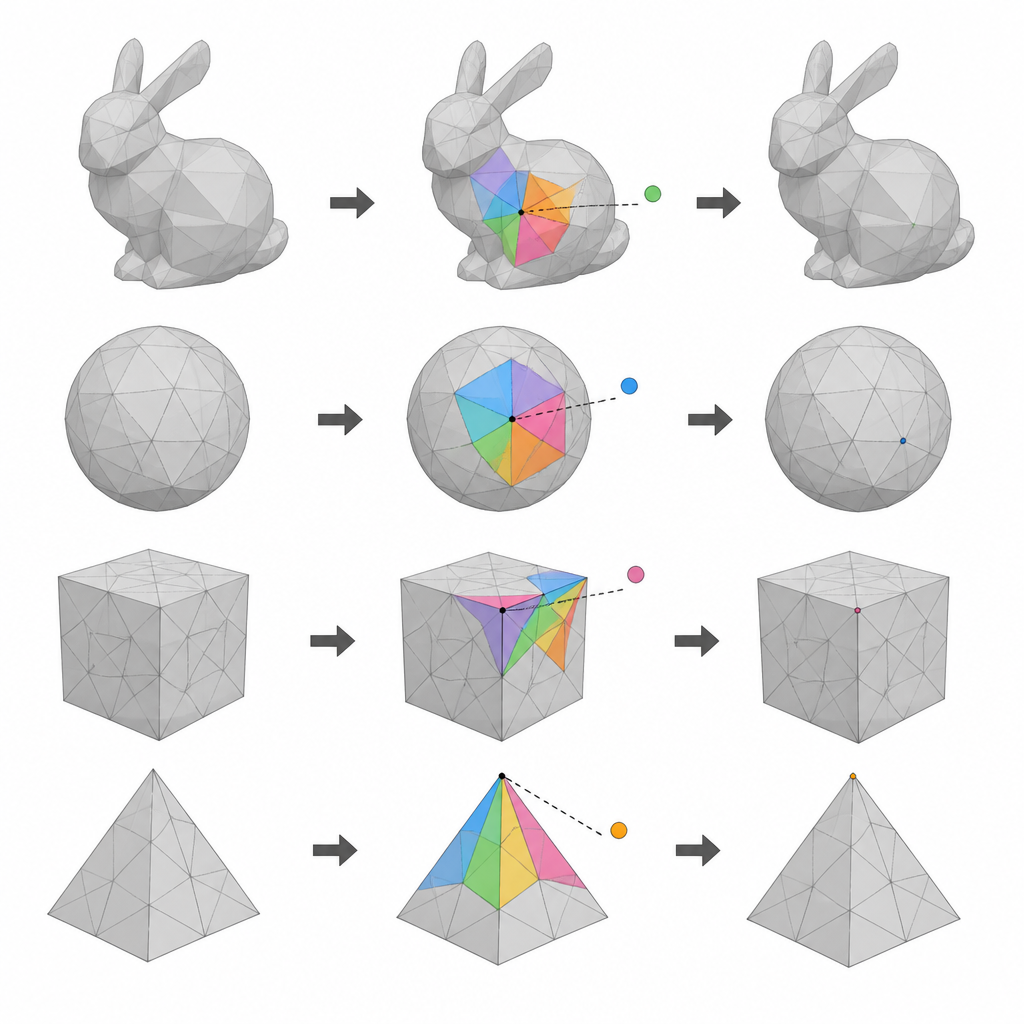
Verwendung von Schichten von Punkten auf einer 3D-Oberfläche
Die Autoren konzentrieren sich auf 3D-Mesh-Modelle, die ein Objekt als Netzwerk von Punkten (Scheitelpunkten) beschreiben, die zu kleinen Flächen verbunden sind. Ihre erste Idee ist, alle Scheitelpunkte anhand ihrer Indexnummern in drei Gruppen zu unterteilen. Zwei dieser Gruppen dienen abwechselnd als Kandidaten für die Datenverbergung, während die verbleibende Gruppe Referenzpunkte liefert, die während eines Durchgangs unverändert bleiben müssen. Durch zwei Runden des Verbergens und das Wechseln, welche Gruppe als Kandidaten und welche als Referenzen dient, kann die Methode deutlich mehr Scheitelpunkte für die Datenübertragung nutzen als frühere Einzel-Durchgangs-Schemata, ohne die Fähigkeit zu verlieren, das Originalmodell wiederherzustellen.
Benachbarte Punkte einander vorhersagen lassen
Die zweite Schlüsselidee beruht auf der Tatsache, dass benachbarte Punkte auf einer glatten 3D-Oberfläche in der Regel nahe einer einfachen Durchschnittsposition liegen. Für jeden Kandidaten-Scheitelpunkt bildet die Methode ein kleines Polygon aus den meisten seiner Nachbarn, die sich derzeit in der Referenzgruppe befinden. Anschließend sagt sie anhand dieser Nachbarn voraus, wo der Scheitelpunkt liegen sollte, und misst die kleine Differenz zwischen Vorhersage und tatsächlicher Position. Diese Vorhersagefehler bilden eine kompakte, gutartige Wertemenge, die vorsichtig gedehnt und verschoben werden kann, um Datenbits zu codieren. Weil die unberührten Nachbarn fest bleiben, können dieselben Vorhersagen später wiederholt werden, was sowohl für das Wiedergewinnen der versteckten Daten als auch für die Wiederherstellung der ursprünglichen Koordinaten essentiell ist.
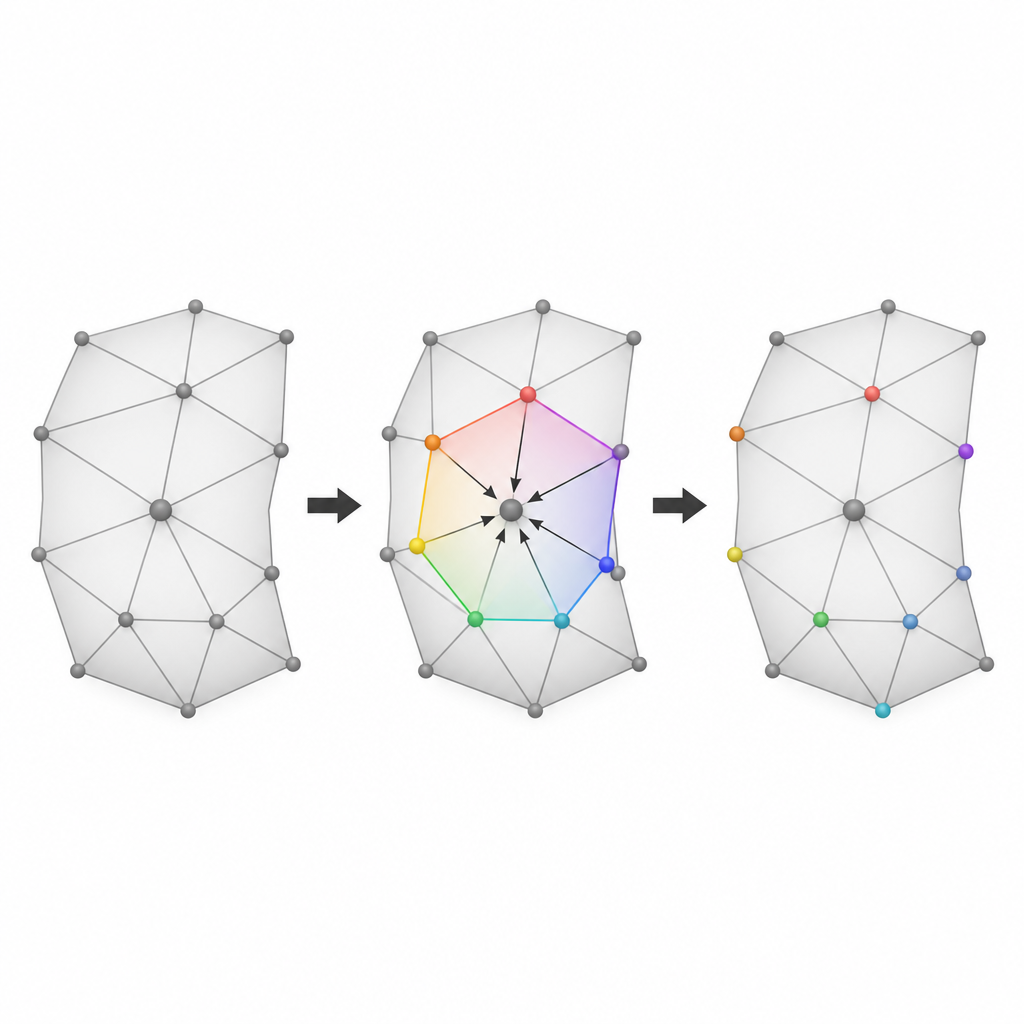
Die glattesten Stellen zum Verbergen auswählen
Die dritte Idee besteht darin, wählerisch zu sein, wo mit dem Verbergen begonnen wird. Die Autoren bewerten jede kleine Nachbarschaft um einen Kandidaten-Scheitelpunkt danach, wie glatt und regelmäßig sie ist. Ein Maß prüft, wie nahe die Summe ihrer Winkel der eines flachen Polygons kommt, während ein anderes die Ähnlichkeit der Kantenlängen bewertet. Diese beiden Werte werden zu einem einzigen Prioritätswert kombiniert. Nachbarschaften, die glatter und regelmäßiger sind, erzeugen wahrscheinlich kleinere Vorhersagefehler, sodass Verschiebungen die Oberfläche weniger stören. Indem alle Kandidatenregionen nach diesem kombinierten Glattheitsmaß sortiert und Daten beginnend mit den besten Regionen eingebettet werden, hält die Methode sichtbare Verzerrungen auch bei der Verbergung großer Informationsmengen gering.
Tests an verbreiteten 3D-Modellen
Das Team evaluierte seine Methode an bekannten 3D-Meshes wie dem Stanford Bunny, einem Pferd, einer Hand und einem Drachen und verglich sie mit mehreren führenden Techniken. Sie maßen sowohl, wie viele Bits pro Scheitelpunkt gespeichert werden konnten, als auch wie stark sich die Geometrie änderte, unter Verwendung einer standardisierten Signal-Rausch-Metrik. Ihr Ansatz erreichte eine höhere Datenkapazität als die anderen Verfahren bei gleichzeitiger Beibehaltung geringer Formveränderungen und verbesserte häufig die Qualitätsbewertung um mehrere Dezibel. Selbst beim Speichern von mehr als eineinhalb Bits pro Scheitelpunkt blieben die meisten Modelle optisch nahezu unverändert, und die Methode lief in Sekunden bis zu einigen Dutzend Sekunden, selbst bei Meshes mit Hunderttausenden von Scheitelpunkten.
Was das für digitale 3D-Inhalte bedeutet
Praktisch zeigt diese Arbeit, dass es möglich ist, beträchtliche Informationsmengen in detaillierte 3D-Modelle einzubetten und dabei sowohl das Aussehen zu bewahren als auch die Möglichkeit, perfekt zum Original zurückzukehren. Durch die Kombination der geschichteten Nutzung von Scheitelpunkten, nachbarschaftsbasierter Vorhersage und einer sorgfältigen Auswahl der Einbettungsorte bietet die Methode ein besseres Verhältnis zwischen Speicherkapazität und Formqualität als frühere Ansätze. Das macht sie zu einem vielversprechenden Baustein für sichere Kennzeichnung, Integritätsprüfung und Annotation des wachsenden Universums 3D-basierter Inhalte.
Zitation: Wang, Q., Zhang, Q., Song, X. et al. Reversible data hiding for 3D mesh models based on spatial polygon prediction and dual sorting. Sci Rep 16, 16097 (2026). https://doi.org/10.1038/s41598-026-47050-3
Schlüsselwörter: reversible Datenverbergung, 3D-Mesh, digitale Wasserzeichen, Urheberrechtsschutz, geometrische Verzerrung