Clear Sky Science · es
Inserción de datos reversible para modelos de malla 3D basada en predicción espacial de polígonos y doble ordenación
Ocultar mensajes en objetos 3D
A medida que los modelos 3D se vuelven habituales en cine, videojuegos, ingeniería y medicina, existe una necesidad creciente de etiquetarlos con marcas de propiedad y códigos de seguridad sin alterar su aspecto. Este artículo explora una forma de incrustar bits secretos de información en un objeto 3D, como una estatua digital o una pieza mecánica, de manera que la superficie permanezca casi idéntica a nivel visual y además permita recuperar perfectamente el modelo original más adelante.
Por qué importa la inserción reversible
La inserción de datos reversible es como escribir con tinta invisible que puede borrarse por completo sin dejar rastro. Permite a los creadores incorporar derechos de autor, comprobaciones de integridad o notas dentro de medios digitales garantizando que se pueda restaurar cada detalle original. Esto es vital en áreas como exploraciones médicas, defensa y archivos digitales, donde incluso pequeños cambios permanentes pueden ser inaceptables. Aunque estas técnicas están bien desarrolladas para imágenes 2D, aplicarlas a modelos 3D es más difícil porque las formas son irregulares y están conectadas de manera compleja, lo que complica ocultar datos sin alterar visiblemente la geometría.
Usar capas de puntos en una superficie 3D
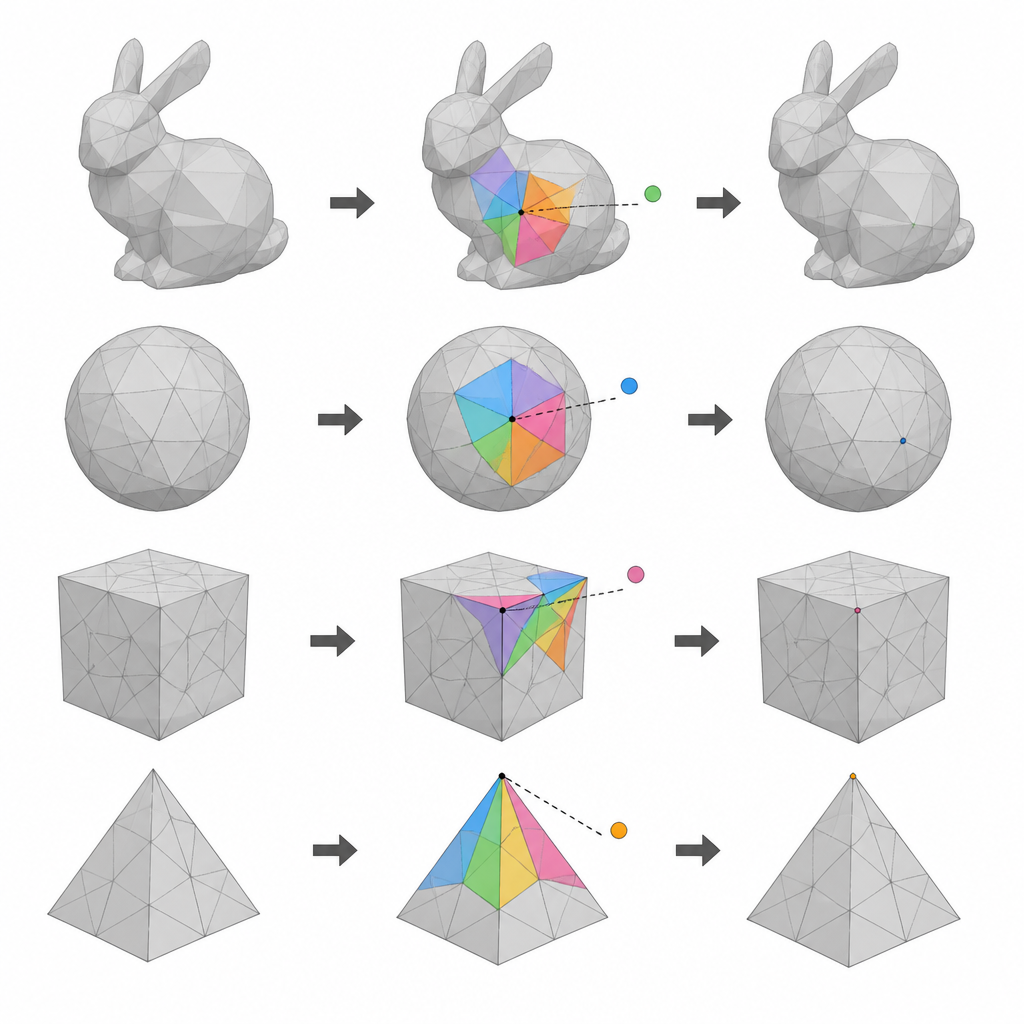
Los autores se centran en modelos de malla 3D, que describen un objeto como una red de puntos (vértices) conectados en pequeñas caras. Su primera idea es dividir todos los vértices en tres grupos usando sus números de índice. Dos de estos grupos van turnándose como candidatos para ocultar datos, mientras que el grupo restante suministra puntos de referencia que deben permanecer intactos en cada pasada. Al realizar dos rondas de inserción y cambiar qué grupo se usa como candidatos y cuál como referencias, el método puede usar muchos más vértices para portar datos que los esquemas anteriores de una sola pasada, sin perder la capacidad de restaurar el modelo original.
Permitir que los puntos cercanos se predigan entre sí
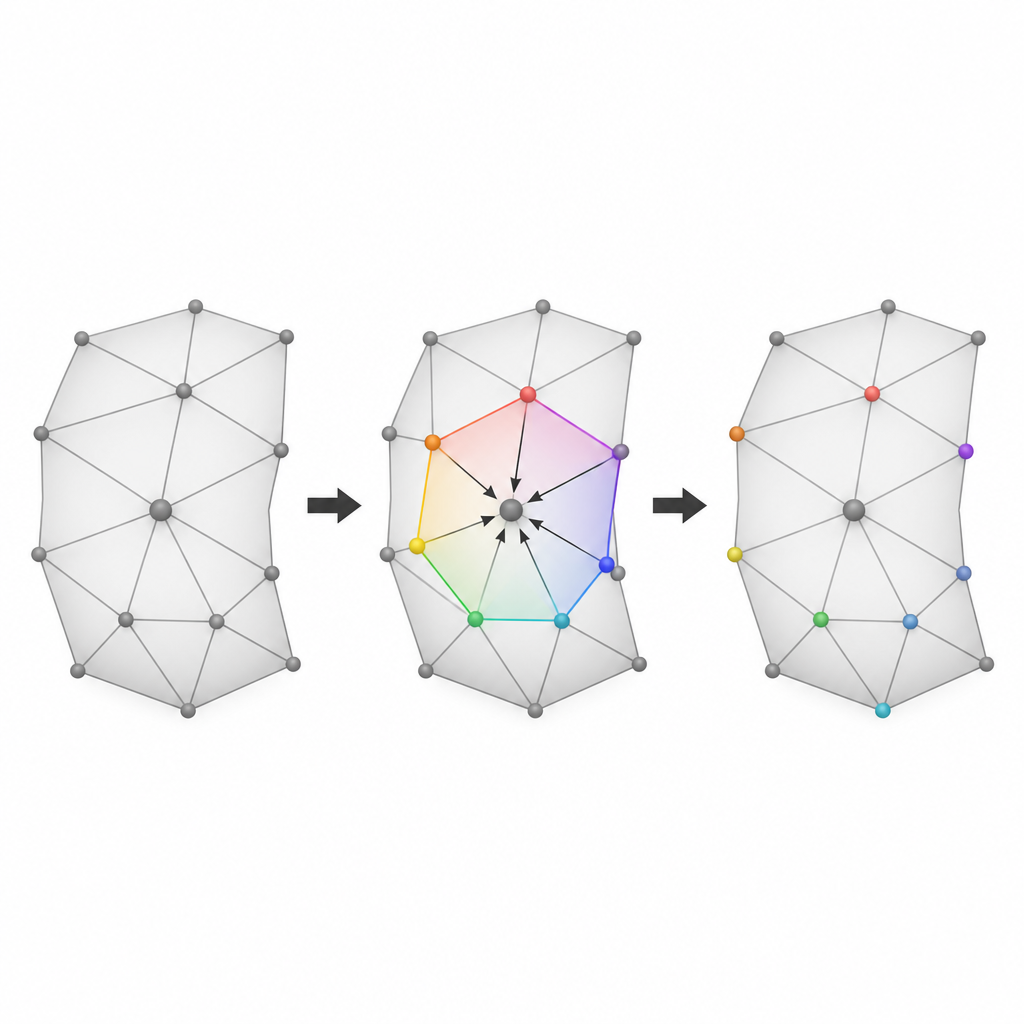
La segunda idea clave se basa en el hecho de que los puntos vecinos en una superficie 3D suave suelen estar cerca de una posición media simple. Para cualquier vértice candidato, el método forma un pequeño polígono con la mayoría de sus vecinos que actualmente están en el grupo de referencia. A continuación predice dónde debería situarse el vértice en función de esos vecinos y mide la pequeña diferencia entre la predicción y la posición real. Estos errores de predicción conforman un conjunto compacto y bien comportado de valores que pueden estirarse y desplazarse suavemente para codificar bits de datos. Debido a que los vecinos intactos permanecen fijos, las mismas predicciones se pueden repetir más tarde, lo cual es esencial tanto para recuperar los datos ocultos como para restaurar las coordenadas originales.
Elegir los lugares más lisos para ocultar datos
La tercera idea es ser selectivo sobre dónde empezar a ocultar. Los autores califican cada pequeño vecindario alrededor de un vértice candidato según lo suave y regular que sea. Una medida comprueba cuán cercana está la suma de sus ángulos a la de un polígono plano, mientras que otra evalúa cuán similares son las longitudes de sus aristas. Estas dos puntuaciones se combinan en un único valor de prioridad. Los vecindarios que son más lisos y regulares probablemente producirán errores de predicción más pequeños, por lo que al desplazarlos se altera menos la superficie. Ordenando todas las regiones candidatas según esta medida combinada de suavidad e incrustando datos empezando por las mejores, el método mantiene la distorsión visible baja incluso al ocultar una gran cantidad de información.
Pruebas en modelos 3D comunes
El equipo evaluó su método en mallas 3D bien conocidas como el Stanford Bunny, un caballo, una mano y un dragón, comparándolo con varias técnicas punteras. Midieron tanto cuántos bits se podían almacenar por vértice como cuánto cambiaba la geometría, usando una medida estándar de relación señal-ruido. Su enfoque consiguió una mayor capacidad de datos que los demás mientras mantenía pequeño el cambio en la forma, mejorando a menudo la puntuación de calidad por varios decibelios. Incluso al almacenar más de una vez y media bits por vértice, la mayoría de los modelos permanecieron casi inalterados visualmente, y el método se ejecutó en segundos hasta decenas de segundos incluso para mallas con cientos de miles de vértices.
Qué significa esto para el contenido 3D digital
En términos prácticos, este trabajo demuestra que es posible incrustar cantidades considerables de información en modelos 3D detallados preservando tanto la apariencia como la capacidad de volver perfectamente al original. Al combinar el uso en capas de los vértices, la predicción basada en vecinos y una cuidadosa elección de dónde incrustar, el método ofrece un mejor equilibrio entre almacenamiento y calidad de forma que los enfoques anteriores. Esto lo convierte en un bloque prometedor para el etiquetado seguro, la comprobación de integridad y la anotación del creciente universo de contenido 3D.
Cita: Wang, Q., Zhang, Q., Song, X. et al. Reversible data hiding for 3D mesh models based on spatial polygon prediction and dual sorting. Sci Rep 16, 16097 (2026). https://doi.org/10.1038/s41598-026-47050-3
Palabras clave: inserción de datos reversible, malla 3D, marcado digital, protección de derechos de autor, distorsión geométrica