Clear Sky Science · nl
Omkeerbare gegevensverberging voor 3D-meshmodellen gebaseerd op ruimtelijke polygoonvoorspelling en dubbele sortering
Berichten verbergen in 3D-objecten
Nu 3D-modellen gangbaar worden in films, games, engineering en geneeskunde, groeit de behoefte om ze te markeren met eigendomskenmerken en beveiligingscodes zonder hun uiterlijk te veranderen. Dit artikel onderzoekt een manier om geheime bits informatie in een 3D-object, zoals een digitaal beeldhouwwerk of een mechanisch onderdeel, te verbergen op een manier die het oppervlak vrijwel visueel identiek houdt en tevens toestaat dat het oorspronkelijke model later perfect kan worden hersteld.
Waarom omkeerbare verberging belangrijk is
Omkeerbare gegevensverberging is als schrijven met onzichtbare inkt die volledig kan worden gewist zonder een spoor achter te laten. Het stelt makers in staat auteursrechten, integriteitscontroles of notities in digitale media in te bedden, met de garantie dat elk origineel detail kan worden hersteld. Dit is cruciaal in domeinen zoals medische scans, defensie en digitale archieven, waar zelfs kleine permanente wijzigingen onaanvaardbaar kunnen zijn. Hoewel zulke technieken goed ontwikkeld zijn voor 2D-beelden, is toepassing op 3D-modellen moeilijker omdat de vormen onregelmatig zijn en op complexe manieren verbonden, wat het lastig maakt gegevens te verbergen zonder de geometrie zichtbaar te verstoren.
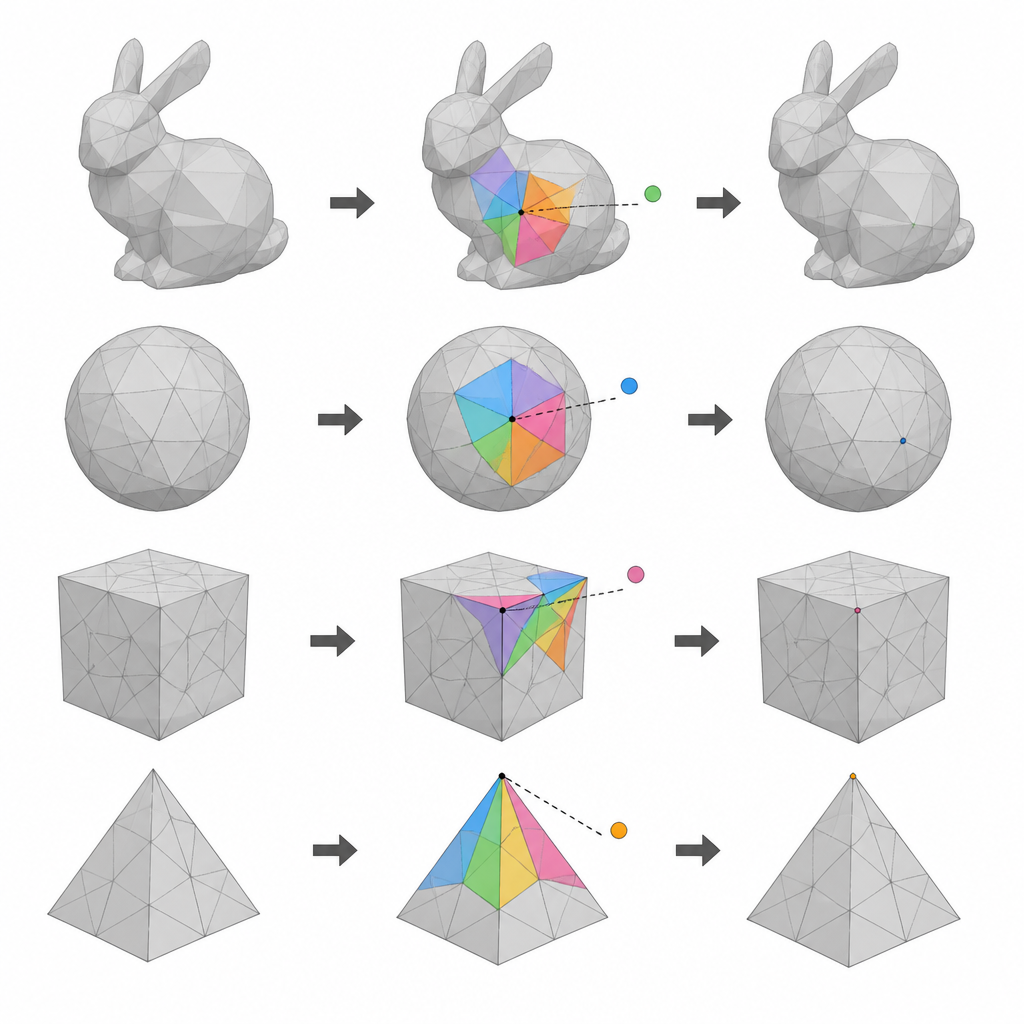
Gebruik van lagen van punten op een 3D-oppervlak
De auteurs richten zich op 3D-meshmodellen, die een object beschrijven als een netwerk van punten (verticies) verbonden in kleine vlakken. Hun eerste idee is om alle vertices in drie groepen te verdelen op basis van hun indexnummers. Twee van deze groepen dienen beurtelings als kandidaten voor gegevensverberging, terwijl de overgebleven groep referentiepunten levert die tijdens elke ronde onaangeroerd moeten blijven. Door twee rondes van verbergen uit te voeren en te wisselen welke groep als kandidaat en welke als referentie fungeert, kan de methode veel meer vertices gebruiken om gegevens te dragen dan eerdere single-pass schema’s, zonder het vermogen te verliezen het originele model te herstellen.
De nabijgelegen punten elkaar laten voorspellen
Het tweede kernidee berust op het feit dat naburige punten op een glad 3D-oppervlak meestal dicht bij een eenvoudige gemiddelde positie liggen. Voor elk kandidaat-vertex vormt de methode een klein polygoon van de meeste van zijn buren die momenteel in de referentiegroep zitten. Vervolgens voorspelt zij waar het vertex zou moeten liggen op basis van deze buren en meet het kleine verschil tussen de voorspelling en de werkelijke positie. Deze voorspellingsfouten vormen een compacte, goed gedragende reeks waarden die zachtjes kunnen worden uitgerekt en verschoven om databits te coderen. Omdat de onaangeroerde buren vast blijven, kunnen dezelfde voorspellingen later opnieuw worden uitgevoerd, wat essentieel is om zowel de verborgen gegevens terug te halen als de originele coördinaten te herstellen.
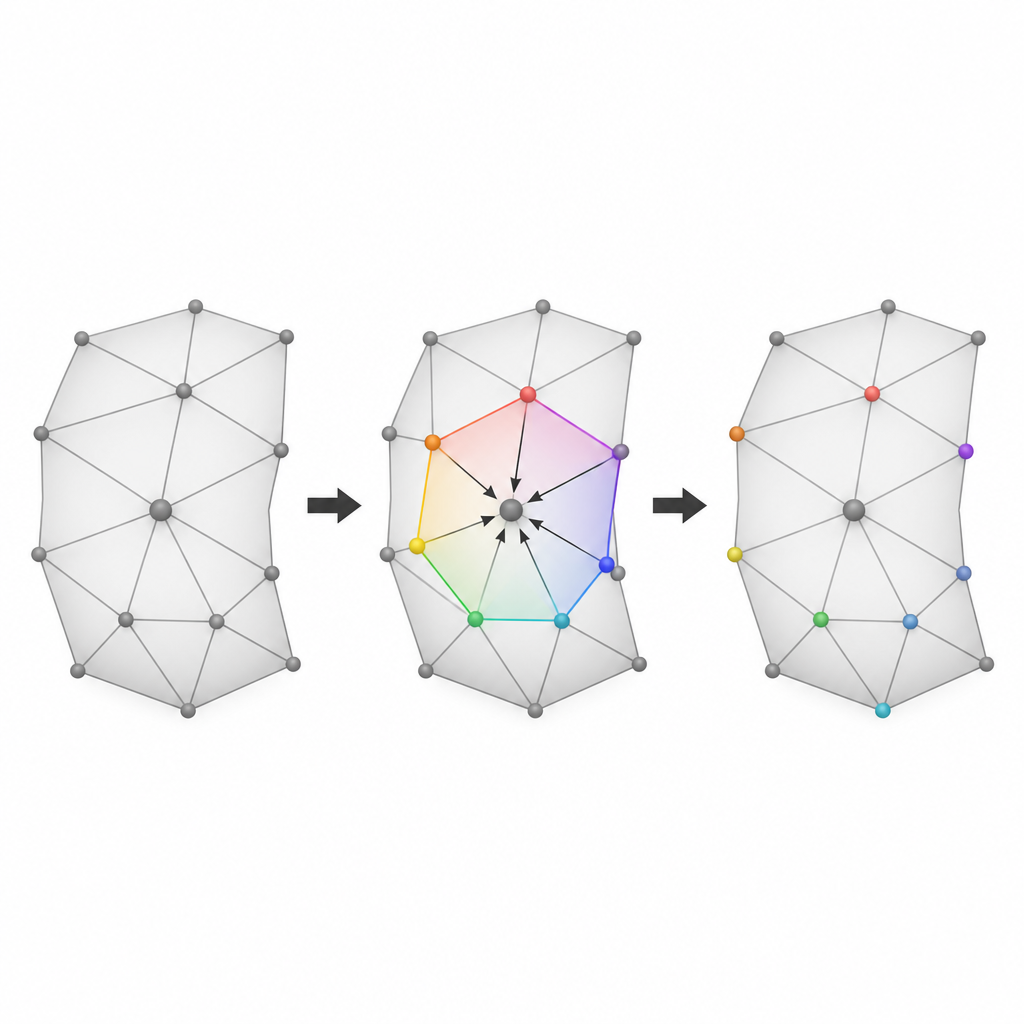
De gladste plaatsen kiezen om data te verbergen
Het derde idee is kieskeurig te zijn over waar te beginnen met verbergen. De auteurs beoordelen elke kleine buurt rond een kandidaat-vertex op hoe glad en regelmatig deze is. Eén maatstaf controleert hoe dicht de som van zijn hoeken bij die van een vlak polygoon ligt, terwijl een andere controleert hoe vergelijkbaar de lengtes van zijn randen zijn. Deze twee scores worden gecombineerd tot een enkele prioriteitswaarde. Buurten die gladder en regelmatiger zijn zullen waarschijnlijk kleinere voorspellingsfouten opleveren, zodat hun verschuiving het oppervlak minder verstoort. Door alle kandidaatregio’s te sorteren op deze gecombineerde gladheidsmaat en gegevens te embedden beginnend bij de beste, houdt de methode zichtbare vervorming laag, zelfs wanneer grote hoeveelheden informatie worden verborgen.
Testen op veelgebruikte 3D-modellen
Het team evalueerde hun methode op bekende 3D-meshes zoals de Stanford Bunny, een paard, een hand en een draak, en vergeleek deze met verschillende toonaangevende technieken. Ze maten zowel hoeveel bits per vertex konden worden opgeslagen als hoezeer de geometrie veranderde, gebruikmakend van een standaard signaal-naar-ruis maat. Hun benadering behaalde een hogere datacapaciteit dan de andere methoden terwijl de verandering in vorm klein bleef, vaak met een verbetering van de kwaliteitscore met meerdere decibellen. Zelfs bij het opslaan van meer dan anderhalf bit per vertex bleven de meeste modellen visueel vrijwel onveranderd, en de methode draaide in enkele seconden tot tientallen seconden, zelfs voor meshes met honderden duizenden vertices.
Wat dit betekent voor digitale 3D-inhoud
In praktische zin laat dit onderzoek zien dat het mogelijk is aanzienlijke hoeveelheden informatie in gedetailleerde 3D-modellen te embedden terwijl zowel het uiterlijk als het vermogen om perfect terug te keren naar het origineel behouden blijven. Door gelaagd gebruik van vertices, buurvoorspelling en een zorgvuldige keuze van waar te embedden te combineren, biedt de methode een betere balans tussen opslagcapaciteit en vormkwaliteit dan eerdere benaderingen. Dit maakt het een veelbelovende bouwsteen voor beveiligde labeling, integriteitscontrole en annotatie van het groeiende universum van 3D-inhoud.
Bronvermelding: Wang, Q., Zhang, Q., Song, X. et al. Reversible data hiding for 3D mesh models based on spatial polygon prediction and dual sorting. Sci Rep 16, 16097 (2026). https://doi.org/10.1038/s41598-026-47050-3
Trefwoorden: omkeerbare gegevensverberging, 3D-mesh, digitale watermarking, auteursrechtbescherming, geometrische vervorming