Clear Sky Science · ru
Обратимое сокрытие данных в 3D-мешах на основе пространственного предсказания полигонов и двойной сортировки
Сокрытие сообщений в 3D-объектах
По мере того как 3D-модели становятся обыденностью в кино, играх, инженерии и медицине, возрастает потребность помечать их отметками владения и кодами безопасности без изменения внешнего вида. В этой статье исследуется способ встраивания секретных битов информации в 3D-объект, такой как цифровая статуя или деталь механизма, таким образом, чтобы поверхность оставалась практически визуально неотличимой и при этом исходная модель могла быть затем полностью восстановлена.
Почему важно обратимое сокрытие
Обратимое сокрытие данных похоже на запись невидимыми чернилами, которые можно полностью стереть без следа. Оно позволяет авторам внедрять отметки об авторстве, проверки целостности или заметки внутрь цифровых данных, гарантируя восстановление каждой исходной детали. Это критично в сферах вроде медицинских сканов, обороны и цифровых архивов, где даже небольшие постоянные изменения недопустимы. Хотя такие методы хорошо развиты для 2D-изображений, их применение к 3D-моделям сложнее из‑за неравномерности форм и сложных связей между элементами, что затрудняет скрытие данных без видимого искажения геометрии.
Использование слоёв точек на 3D-поверхности
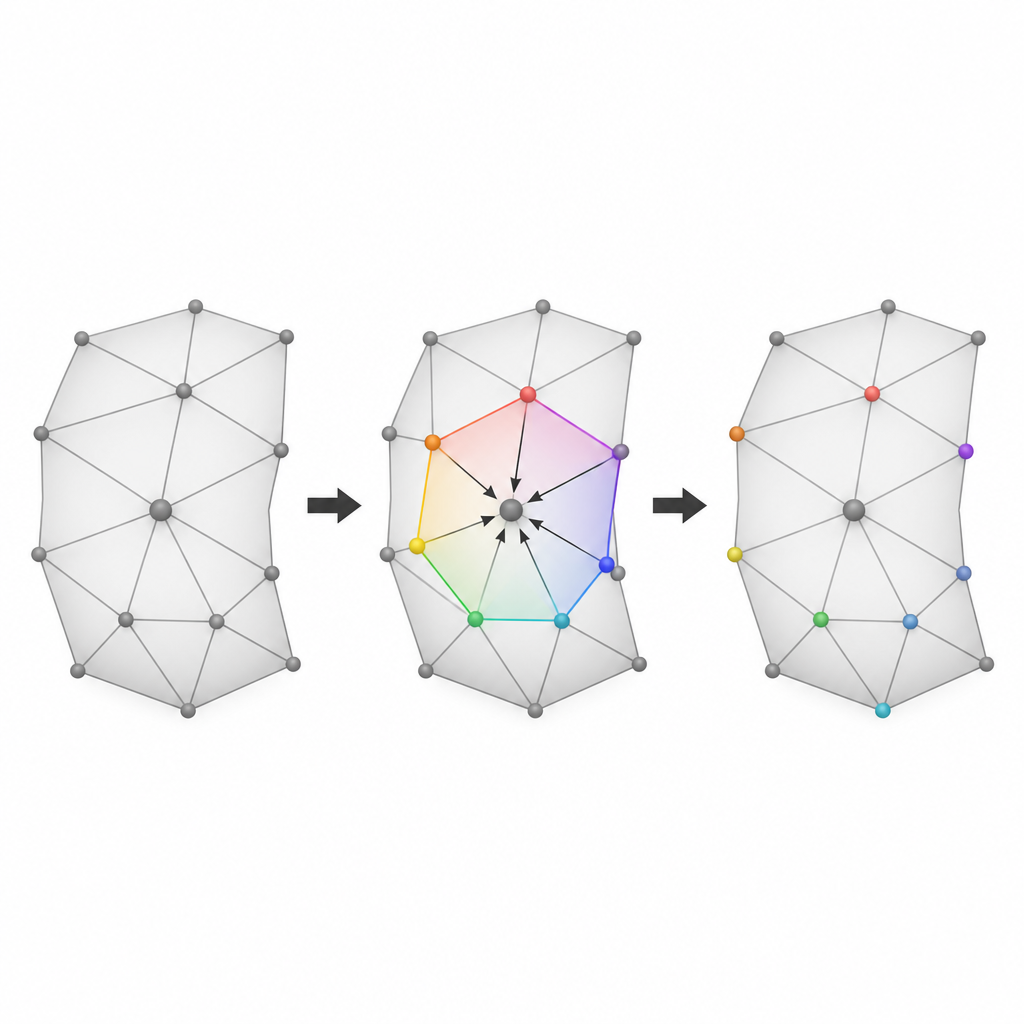
Авторы сосредотачиваются на 3D-мешах, которые описывают объект как сеть точек (вершин), соединённых в мелкие грани. Их первая идея — разделить все вершины на три группы по номерам индексов. Две из этих групп по очереди выступают кандидатами для сокрытия данных, тогда как оставшаяся группа служит опорными точками, которые должны оставаться нетронутыми в каждом проходе. Выполняя два раунда сокрытия и меняя роли групп кандидатов и опорных точек, метод может использовать значительно больше вершин для несения данных, чем предыдущие одноэтапные схемы, сохраняя при этом возможность восстановить исходную модель.
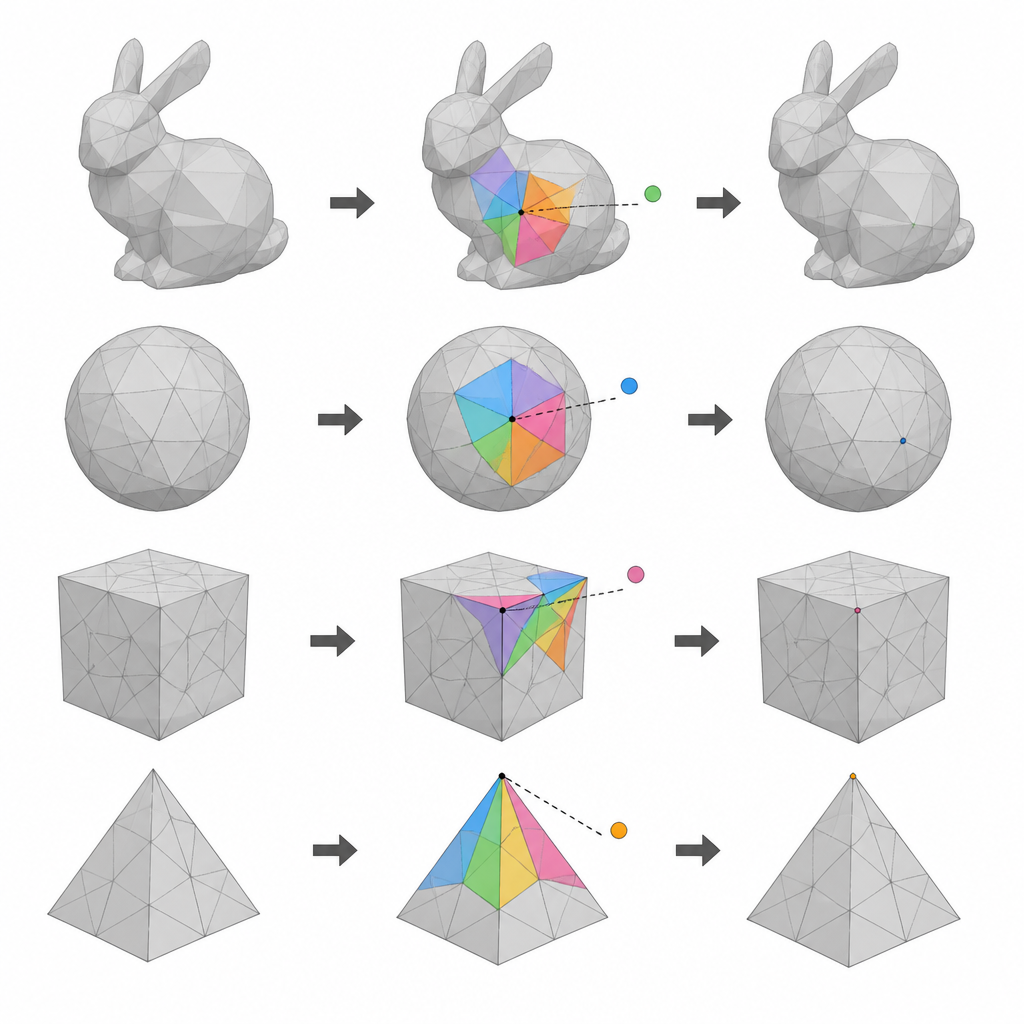
Позволяя соседним точкам предсказывать друг друга
Вторая ключевая идея опирается на то, что соседние точки на гладкой 3D-поверхности обычно находятся близко к простому среднему положению. Для каждой кандидатной вершины метод формирует небольшой многоугольник из большинства её соседей, принадлежащих в данный момент опорной группе. Затем он предсказывает, где должна располагаться вершина, исходя из этих соседей, и измеряет малую разницу между предсказанием и реальной позицией. Эти ошибки предсказания образуют компактный, хорошо управляемый набор значений, который можно аккуратно растянуть и сместить для кодирования битов данных. Поскольку нетронутые соседи остаются фиксированными, те же предсказания можно повторить позже, что важно и для восстановления скрытых данных, и для возвращения исходных координат.
Выбор самых гладких мест для сокрытия данных
Третья идея заключается в том, чтобы выбирать, где начинать сокрытие, более разборчиво. Авторы оценивают каждое небольшое окружение вокруг кандидатной вершины по тому, насколько оно гладкое и регулярно. Одна метрика проверяет, насколько близка сумма углов к сумме углов плоского многоугольника, в то время как другая проверяет схожесть длин его рёбер. Эти два показателя комбинируются в одно приоритетное значение. Окружения, которые более гладкие и регулярные, скорее всего будут давать меньшие ошибки предсказания, поэтому их сдвиг менее заметно искажает поверхность. Сортируя все кандидатные регионы по этому объединённому показателю гладкости и встраивая данные, начиная с лучших, метод сохраняет низкий визуальный уровень искажений даже при большом объёме скрываемой информации.
Тестирование на известных 3D-моделях
Команда оценивала свой метод на широко известных 3D-мешах, таких как Stanford Bunny, лошадь, кисть и дракон, сравнивая его с несколькими передовыми подходами. Они измеряли и количество бит на вершину, и степень изменения геометрии, используя стандартную метрику сигнал/шум. Их подход обеспечил большую ёмкость хранения данных по сравнению с другими, при этом сохранял небольшие изменения формы, часто улучшая показатель качества на несколько децибел. Даже при вместимости более полутора бит на вершину, большинство моделей оставались визуально практически неизменными, а метод работал в пределах нескольких секунд — десятков секунд даже для мешей с сотнями тысяч вершин.
Что это означает для цифрового 3D-контента
В практическом плане эта работа показывает, что возможно встраивать значительные объёмы информации в детализированные 3D-модели, сохраняя и внешний вид, и возможность точно вернуть исходный объект. Комбинируя послойное использование вершин, предсказание на основе соседей и тщательный выбор мест встраивания, метод предлагает лучший компромисс между ёмкостью хранения и качеством формы по сравнению с ранними подходами. Это делает его перспективным компонентом для безопасной маркировки, проверки целостности и аннотирования растущего массива 3D-контента.
Цитирование: Wang, Q., Zhang, Q., Song, X. et al. Reversible data hiding for 3D mesh models based on spatial polygon prediction and dual sorting. Sci Rep 16, 16097 (2026). https://doi.org/10.1038/s41598-026-47050-3
Ключевые слова: обратимое сокрытие данных, 3D-меш, цифровое водяное клеймо, защита авторских прав, геометрическое искажение