Clear Sky Science · fr
Insertion de données réversible pour modèles maillés 3D basée sur la prédiction spatiale des polygones et le tri double
Cacher des messages dans des objets 3D
À mesure que les modèles 3D se généralisent dans le cinéma, les jeux, l'ingénierie et la médecine, le besoin d'y apposer des marques de propriété et des codes de sécurité sans modifier leur apparence augmente. Cet article explore une manière d'insérer des bits d'information secrets dans un objet 3D, comme une statue numérique ou une pièce mécanique, de façon à conserver une surface visuellement presque identique et à permettre la récupération parfaite du modèle original ultérieurement.
Pourquoi l'insertion réversible est importante
L'insertion de données réversible est comparable à l'écriture à l'encre invisible qui peut être entièrement effacée sans laisser de trace. Elle permet aux créateurs d'intégrer des droits d'auteur, des contrôles d'intégrité ou des annotations dans des médias numériques tout en garantissant que chaque détail original peut être restauré. Ceci est essentiel dans des domaines comme l'imagerie médicale, la défense et les archives numériques, où même de minuscules modifications permanentes peuvent être inacceptables. Bien que ces techniques soient bien développées pour les images 2D, leur application aux modèles 3D est plus difficile car les formes sont irrégulières et connectées de manière complexe, ce qui complique la dissimulation de données sans perturber visiblement la géométrie.
Utiliser des couches de points sur une surface 3D
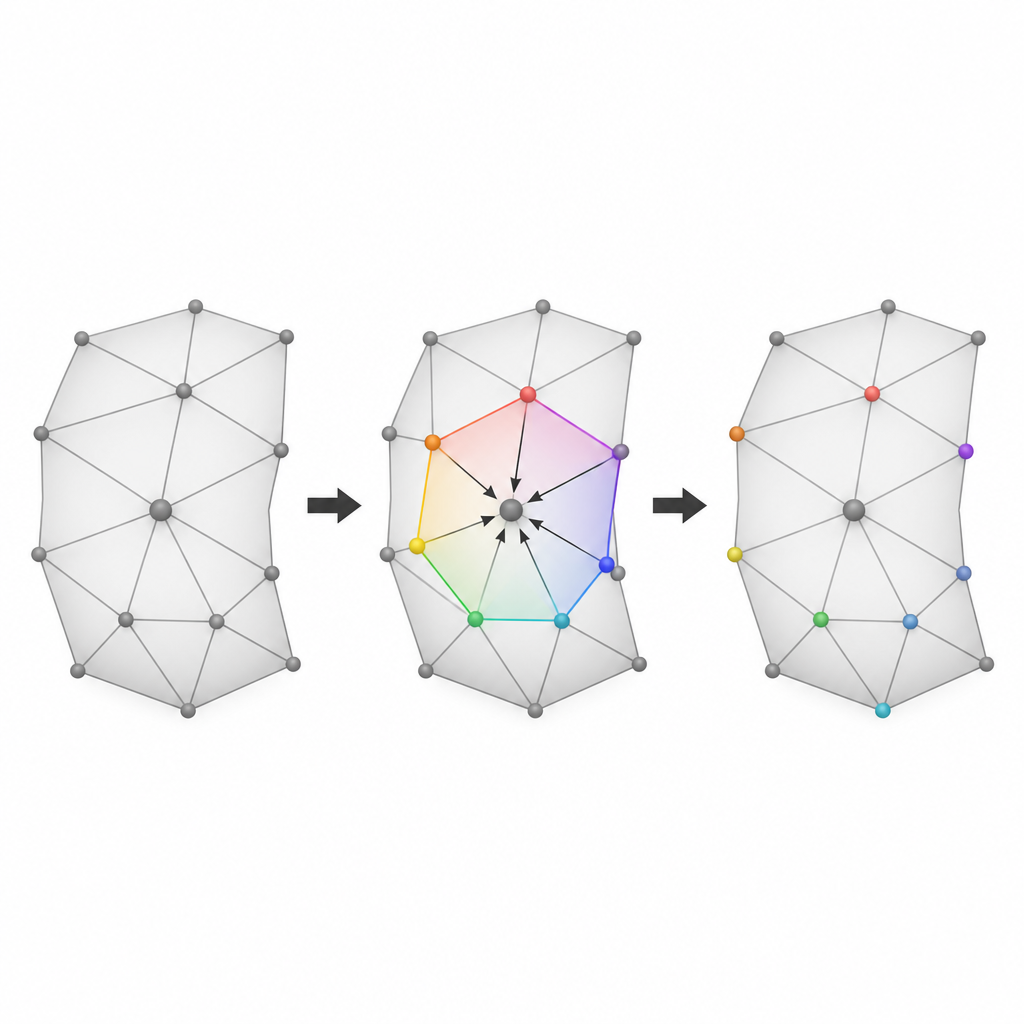
Les auteurs se concentrent sur les modèles maillés 3D, qui décrivent un objet comme un réseau de points (sommets) reliés en petites faces. Leur première idée est de diviser tous les sommets en trois groupes selon leurs indices. Deux de ces groupes servent tour à tour de candidats pour l'insertion de données, tandis que le groupe restant fournit des points de référence qui doivent rester intacts à chaque passage. En réalisant deux tours d'insertion et en alternant quel groupe est utilisé comme candidats et lequel sert de référence, la méthode peut utiliser beaucoup plus de sommets pour porter des données que les schémas antérieurs à passage unique, sans perdre la capacité de restaurer le modèle original.
Laisser les points voisins se prédire mutuellement
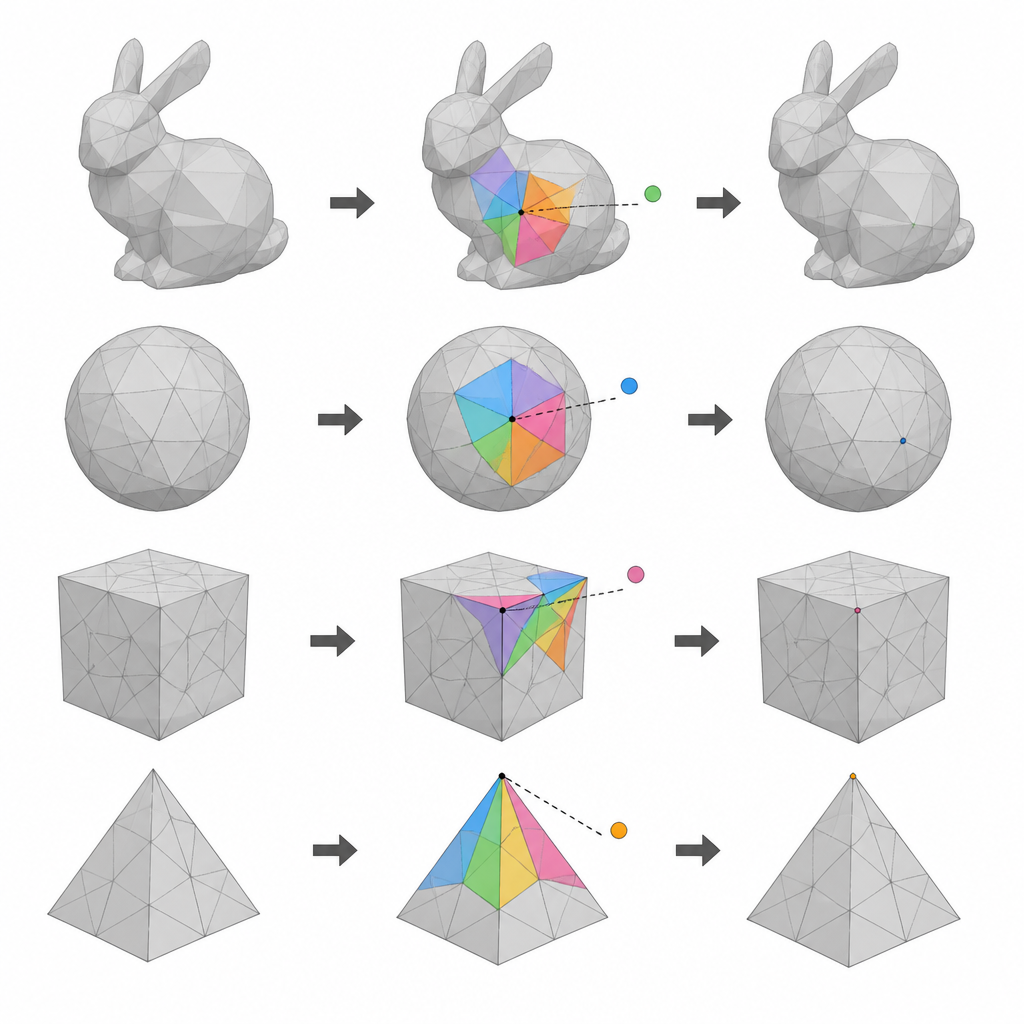
La seconde idée clé repose sur le fait que les points voisins sur une surface 3D lisse se situent généralement près d'une position moyenne simple. Pour chaque sommet candidat, la méthode forme un petit polygone à partir de la plupart de ses voisins qui appartiennent actuellement au groupe de référence. Elle prédit alors où le sommet devrait se trouver à partir de ces voisins et mesure la petite différence entre la prédiction et la position réelle. Ces erreurs de prédiction forment un ensemble compact et bien comporté de valeurs qui peuvent être légèrement étirées et décalées pour encoder des bits. Parce que les voisins intacts restent fixes, les mêmes prédictions peuvent être répétées plus tard, ce qui est essentiel à la fois pour récupérer les données cachées et pour restaurer les coordonnées originales.
Choisir les endroits les plus lisses pour cacher les données
La troisième idée est de sélectionner avec soin les zones où commencer l'insertion. Les auteurs évaluent chaque petit voisinage autour d'un sommet candidat selon sa régularité et sa douceur. Une mesure vérifie à quel point la somme de ses angles se rapproche de celle d'un polygone plat, tandis qu'une autre examine la similarité des longueurs de ses arêtes. Ces deux scores sont combinés en une valeur de priorité unique. Les voisinages plus lisses et plus réguliers sont susceptibles de produire des erreurs de prédiction plus petites, donc les modifications les perturbent moins. En triant toutes les régions candidates selon cette mesure combinée de lissage et en intégrant les données en commençant par les meilleures, la méthode maintient la distorsion visible faible même lors de l'insertion d'une grande quantité d'information.
Tests sur des modèles 3D courants
L'équipe a évalué sa méthode sur des maillages 3D bien connus tels que le Stanford Bunny, un cheval, une main et un dragon, en la comparant à plusieurs techniques de pointe. Ils ont mesuré à la fois le nombre de bits pouvant être stockés par sommet et l'ampleur du changement géométrique, en utilisant une mesure standard de rapport signal sur bruit. Leur approche a atteint une capacité de données supérieure à celle des autres tout en conservant un changement de forme faible, améliorant souvent le score de qualité de plusieurs décibels. Même en stockant plus d'un bit et demi par sommet, la plupart des modèles restaient visuellement quasiment inchangés, et la méthode s'exécutait en quelques secondes à quelques dizaines de secondes même pour des maillages comptant des centaines de milliers de sommets.
Ce que cela implique pour le contenu 3D numérique
Concrètement, ce travail montre qu'il est possible d'insérer des quantités significatives d'information dans des modèles 3D détaillés tout en préservant à la fois l'apparence et la possibilité de revenir parfaitement à l'original. En combinant l'utilisation en couches des sommets, la prédiction basée sur les voisins et un choix attentif des emplacements d'insertion, la méthode offre un meilleur compromis entre capacité de stockage et qualité de la forme que les approches précédentes. Cela en fait un bloc de construction prometteur pour l'étiquetage sécurisé, la vérification d'intégrité et l'annotation de l'univers croissant du contenu 3D.
Citation: Wang, Q., Zhang, Q., Song, X. et al. Reversible data hiding for 3D mesh models based on spatial polygon prediction and dual sorting. Sci Rep 16, 16097 (2026). https://doi.org/10.1038/s41598-026-47050-3
Mots-clés: insertion de données réversible, maillage 3D, marquage numérique, protection du droit d'auteur, distorsion géométrique