Clear Sky Science · pl
Odwrotne ukrywanie danych w modelach siatkowych 3D oparte na przewidywaniu przestrzennym i podwójnym sortowaniu
Ukrywanie wiadomości w obiektach 3D
W miarę jak modele 3D stają się powszechne w filmach, grach, inżynierii i medycynie, rośnie potrzeba oznaczania ich znakami własności i kodami zabezpieczającymi bez zmiany wyglądu. Artykuł ten bada sposób wtapiania poufnych bitów informacji w obiekt 3D, taki jak cyfrowy posąg czy część mechaniczna, w sposób zachowujący powierzchnię niemal identyczną wizualnie i jednocześnie umożliwiający późniejsze całkowite odtworzenie oryginalnego modelu.
Dlaczego odwracalne ukrywanie ma znaczenie
Odwracalne ukrywanie danych przypomina pisanie niewidzialnym atramentem, który można całkowicie zetrzeć bez śladu. Pozwala twórcom osadzać prawa autorskie, sumy kontrolne lub notatki w mediach cyfrowych, gwarantując jednocześnie, że każdy oryginalny szczegół da się przywrócić. Jest to kluczowe w obszarach takich jak badania medyczne, obrona czy archiwa cyfrowe, gdzie nawet drobne, trwałe zmiany mogą być nie do zaakceptowania. Chociaż takie techniki są dobrze rozwinięte dla obrazów 2D, zastosowanie ich do modeli 3D jest trudniejsze, ponieważ kształty są nieregularne i połączone w złożony sposób, co utrudnia ukrycie danych bez widocznego zaburzenia geometrii.
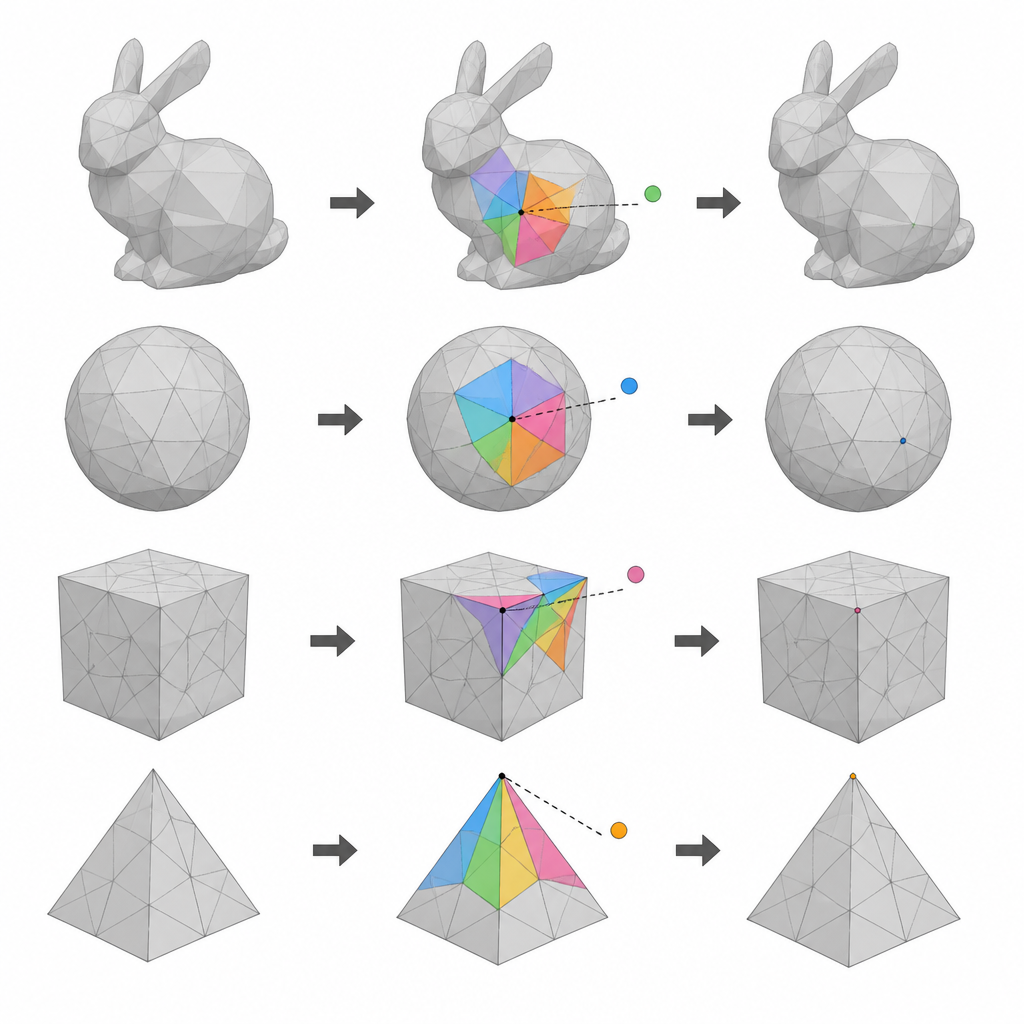
Wykorzystanie warstw punktów na powierzchni 3D
Autorzy koncentrują się na modelach siatkowych 3D, które opisują obiekt jako sieć punktów (wierzchołków) połączonych w małe ściany. Ich pierwszym pomysłem jest podzielenie wszystkich wierzchołków na trzy grupy według numerów indeksów. Dwie z tych grup na przemian pełnią rolę kandydatów do ukrywania danych, podczas gdy pozostała grupa dostarcza punktów odniesienia, które muszą pozostać nietknięte w każdej rundzie. Poprzez wykonanie dwóch rund ukrywania i zamianę ról grup kandydatów i referencji, metoda może wykorzystać znacznie więcej wierzchołków do przenoszenia danych niż wcześniejsze schematy jednoprzejściowe, bez utraty możliwości przywrócenia oryginalnego modelu.
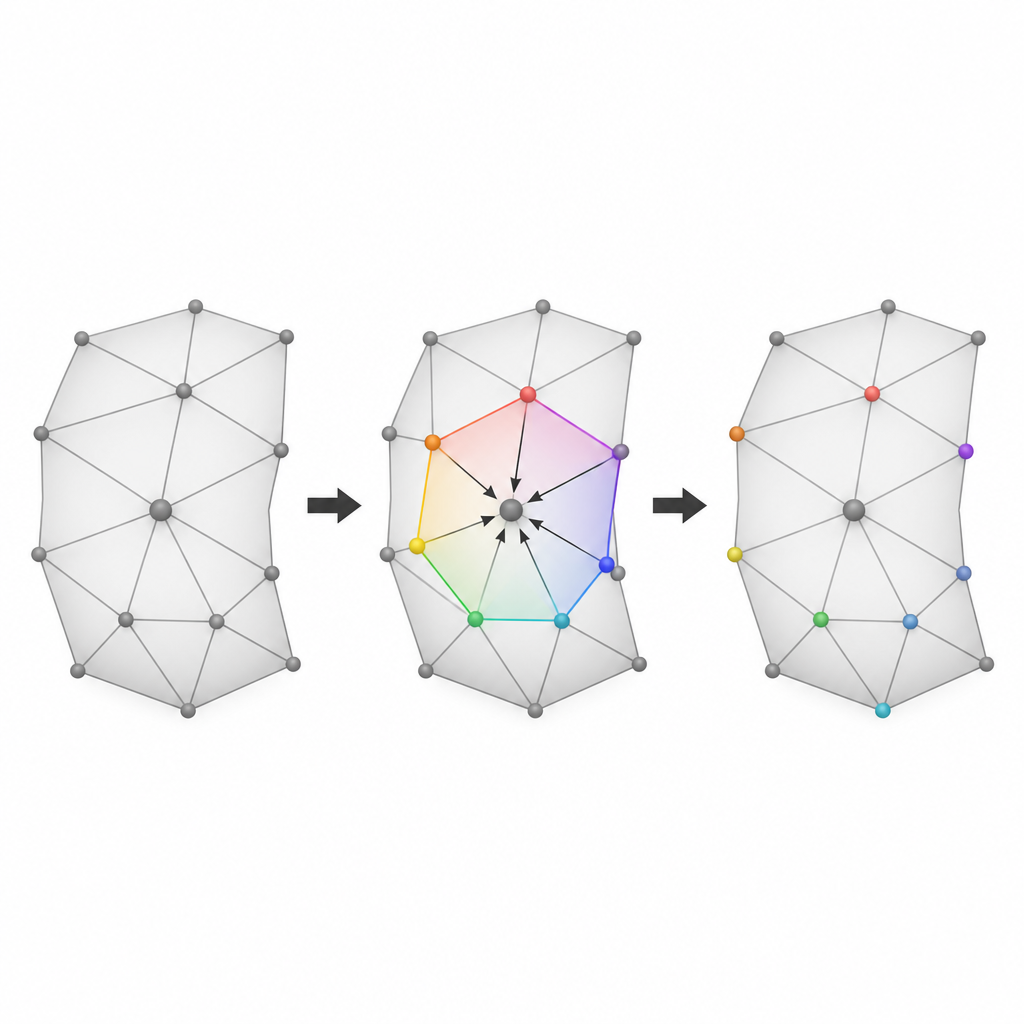
Pozwalanie pobliskim punktom wzajemnie się przewidywać
Drugi kluczowy pomysł opiera się na fakcie, że sąsiednie punkty na gładkiej powierzchni 3D zwykle leżą blisko prostej pozycji średniej. Dla każdego wierzchołka-kandydata metoda tworzy mały wielokąt z większości jego sąsiadów, które obecnie należą do grupy referencyjnej. Następnie przewiduje, gdzie powinien leżeć wierzchołek na podstawie tych sąsiadów i mierzy niewielką różnicę między przewidywaną a rzeczywistą pozycją. Te błędy przewidywania tworzą zwarte, dobrze ułożone zestawy wartości, które można delikatnie rozciągać i przesuwać, aby zakodować bity danych. Ponieważ nietknięci sąsiedzi pozostają stałymi punktami odniesienia, te same przewidywania można powtórzyć później, co jest niezbędne zarówno do odzyskania ukrytych danych, jak i do przywrócenia oryginalnych współrzędnych.
Wybieranie najgładszych miejsc do ukrywania danych
Trzeci pomysł polega na selektywnym wyborze miejsc, gdzie zaczynać ukrywanie. Autorzy oceniają każde małe sąsiedztwo wokół wierzchołka-kandydata pod kątem gładkości i regularności. Jedna miara sprawdza, jak bliska jest suma kątów tej struktury kątom płaskiego wielokąta, podczas gdy inna ocenia, jak podobne są długości jego krawędzi. Te dwie oceny łączone są w jedną wartość priorytetu. Sąsiedztwa bardziej gładkie i regularne prawdopodobnie wygenerują mniejsze błędy przewidywania, więc ich przesunięcie mniej zaburza powierzchnię. Poprzez posortowanie wszystkich regionów kandydatów według tej łączonej miary gładkości i osadzanie danych zaczynając od najlepszych, metoda utrzymuje widoczne zniekształcenia na niskim poziomie nawet przy ukrywaniu dużej ilości informacji.
Testowanie na popularnych modelach 3D
Zespół ocenił swoją metodę na dobrze znanych siatkach 3D, takich jak Stanford Bunny, koń, dłoń i smok, porównując ją z kilkoma wiodącymi technikami. Mierzono zarówno liczbę bitów, które można przechować na wierzchołek, jak i jak bardzo zmieniła się geometria, używając standardowej miary sygnału do hałasu. Ich podejście osiągnęło większą pojemność danych niż inne metody, przy zachowaniu niewielkich zmian kształtu, często poprawiając wynik jakości o kilka decybeli. Nawet przy przechowywaniu ponad półtora bita na wierzchołek, większość modeli pozostała wizualnie niemal niezmieniona, a metoda działała w czasie od kilku do kilkudziesięciu sekund nawet dla siatek z setkami tysięcy wierzchołków.
Co to oznacza dla cyfrowych treści 3D
W praktyce praca ta pokazuje, że możliwe jest osadzenie znaczących ilości informacji w szczegółowych modelach 3D, jednocześnie zachowując wygląd i możliwość pełnego przywrócenia oryginału. Poprzez połączenie warstwowego użycia wierzchołków, przewidywania opartego na sąsiadach oraz starannego wyboru miejsc do osadzania, metoda oferuje lepszy kompromis między pojemnością a jakością kształtu niż wcześniejsze podejścia. To czyni ją obiecującym elementem do bezpiecznego znakowania, sprawdzania integralności i adnotacji rosnącej przestrzeni treści 3D.
Cytowanie: Wang, Q., Zhang, Q., Song, X. et al. Reversible data hiding for 3D mesh models based on spatial polygon prediction and dual sorting. Sci Rep 16, 16097 (2026). https://doi.org/10.1038/s41598-026-47050-3
Słowa kluczowe: odwracalne ukrywanie danych, siatka 3D, znakowanie cyfrowe, ochrona praw autorskich, zniekształcenia geometryczne