Clear Sky Science · en
Reversible data hiding for 3D mesh models based on spatial polygon prediction and dual sorting
Hiding messages in 3D objects
As 3D models become common in movies, games, engineering and medicine, there is a growing need to tag them with ownership marks and security codes without changing how they look. This paper explores a way to tuck secret bits of information into a 3D object, such as a digital statue or mechanical part, in a manner that keeps the surface almost visually identical and also allows the original model to be perfectly recovered later.
Why reversible hiding matters
Reversible data hiding is like writing in invisible ink that can be fully erased without leaving a trace. It lets creators embed copyrights, integrity checks or notes inside digital media while guaranteeing that every original detail can be restored. This is vital in areas like medical scans, defense and digital archives, where even tiny permanent changes may be unacceptable. While such techniques are well developed for 2D images, applying them to 3D models is harder because the shapes are irregular and connected in complex ways, which makes it tricky to hide data without visibly disturbing the geometry.
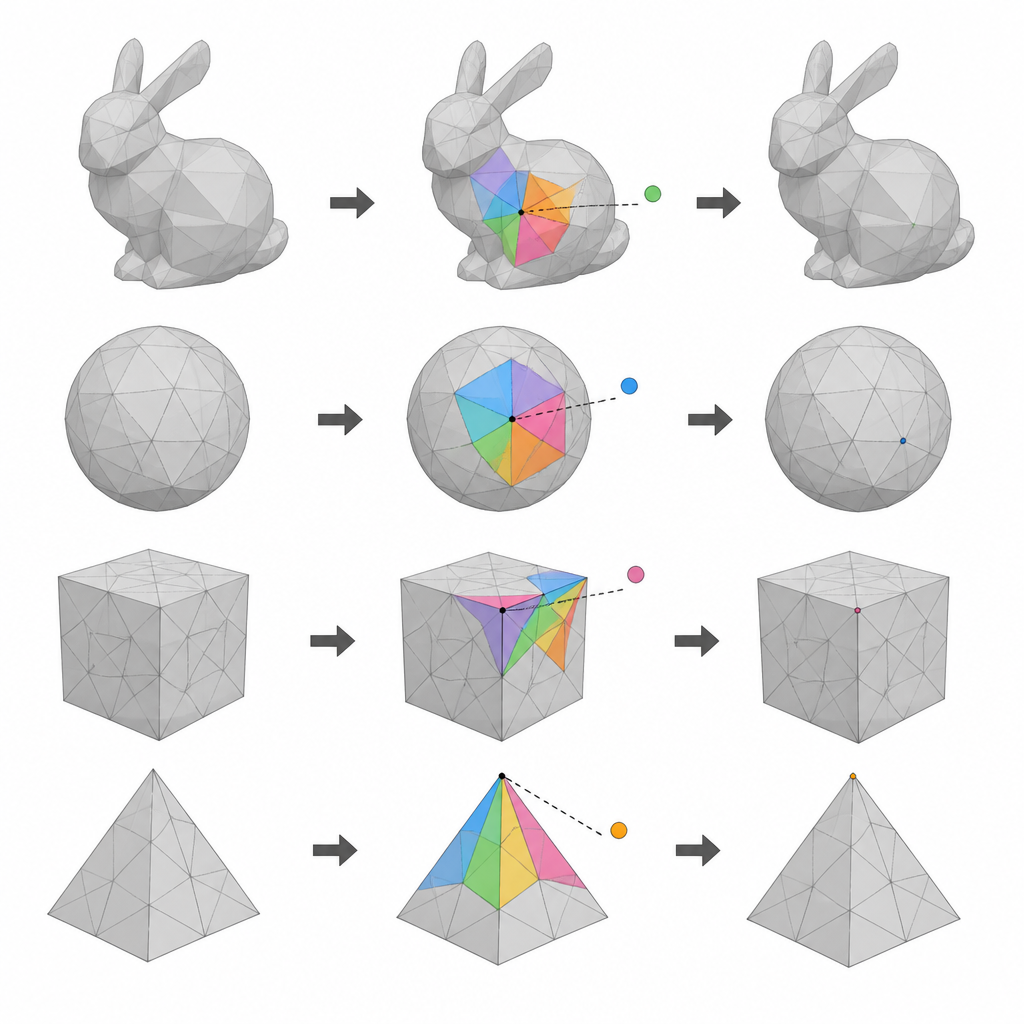
Using layers of points on a 3D surface
The authors focus on 3D mesh models, which describe an object as a network of points (vertices) connected into small faces. Their first idea is to divide all vertices into three groups using their index numbers. Two of these groups take turns serving as candidates for data hiding, while the remaining group supplies reference points that must stay untouched during each pass. By performing two rounds of hiding, and switching which group is used as candidates and which as references, the method can use many more vertices to carry data than earlier, single-pass schemes, without losing the ability to restore the original model.
Letting nearby points predict each other
The second key idea relies on the fact that neighboring points on a smooth 3D surface usually lie close to a simple average position. For any candidate vertex, the method forms a small polygon from most of its neighbors that are currently in the reference group. It then predicts where the vertex should lie based on these neighbors and measures the small difference between the prediction and the actual position. These prediction errors form a compact, well behaved set of values that can be gently stretched and shifted to encode data bits. Because the untouched neighbors remain fixed, the same predictions can be repeated later, which is essential for both recovering the hidden data and restoring the original coordinates.
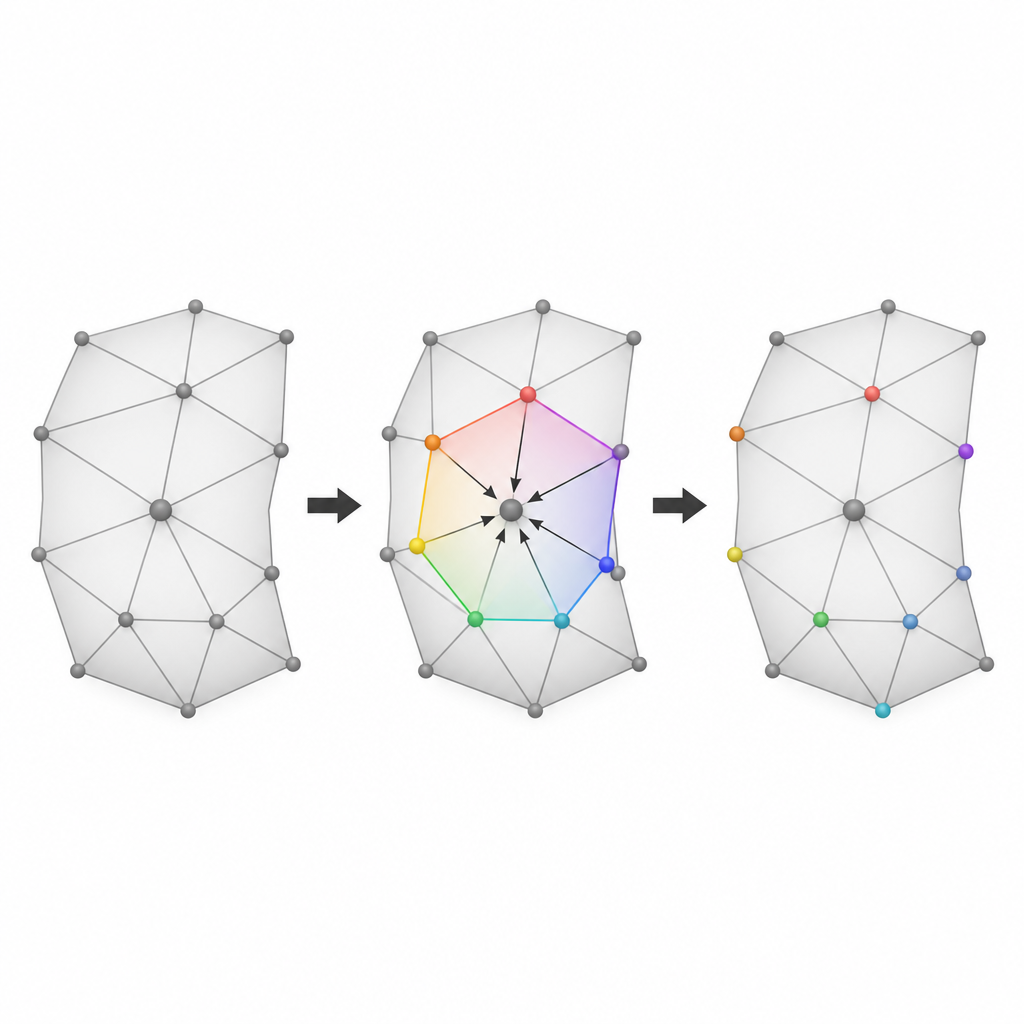
Picking the smoothest places to hide data
The third idea is to be choosy about where to start hiding. The authors rate each small neighborhood around a candidate vertex by how smooth and regular it is. One measure checks how close the sum of its angles is to that of a flat polygon, while another checks how similar the lengths of its edges are. These two scores are combined into a single priority value. Neighborhoods that are smoother and more regular are likely to produce smaller prediction errors, so shifting them disturbs the surface less. By sorting all candidate regions according to this combined smoothness measure and embedding data starting with the best ones, the method keeps visible distortion low even when hiding a large amount of information.
Testing on common 3D models
The team evaluated their method on well known 3D meshes such as the Stanford Bunny, a horse, a hand and a dragon, comparing it with several leading techniques. They measured both how many bits could be stored per vertex and how much the geometry changed, using a standard signal-to-noise measure. Their approach achieved higher data capacity than the others while keeping the change in shape small, often improving the quality score by several decibels. Even when storing more than one and a half bits per vertex, most models remained visually almost unchanged, and the method ran in seconds to tens of seconds even for meshes with hundreds of thousands of vertices.
What this means for digital 3D content
In practical terms, this work shows that it is possible to embed sizable amounts of information into detailed 3D models while preserving both appearance and the ability to revert perfectly to the original. By combining layered use of vertices, neighbor based prediction and a careful choice of where to embed, the method offers a better trade off between storage and shape quality than earlier approaches. This makes it a promising building block for secure labeling, integrity checking and annotation of the growing universe of 3D content.
Citation: Wang, Q., Zhang, Q., Song, X. et al. Reversible data hiding for 3D mesh models based on spatial polygon prediction and dual sorting. Sci Rep 16, 16097 (2026). https://doi.org/10.1038/s41598-026-47050-3
Keywords: reversible data hiding, 3D mesh, digital watermarking, copyright protection, geometric distortion