Clear Sky Science · pt
Inserção reversível de dados em modelos de malha 3D baseada em predição espacial de polígonos e dupla ordenação
Ocultando mensagens em objetos 3D
À medida que modelos 3D se tornam comuns em filmes, jogos, engenharia e medicina, há uma necessidade crescente de marcá‑los com sinais de propriedade e códigos de segurança sem alterar sua aparência. Este artigo explora uma forma de inserir bits secretos de informação em um objeto 3D, como uma estátua digital ou uma peça mecânica, de modo que a superfície permaneça quase idêntica visualmente e que o modelo original possa ser perfeitamente recuperado posteriormente.
Por que a inserção reversível importa
A inserção reversível de dados é como escrever com tinta invisível que pode ser totalmente apagada sem deixar vestígio. Ela permite que criadores incorporem informações de direitos autorais, verificações de integridade ou anotações dentro de mídia digital garantindo que cada detalhe original possa ser restaurado. Isso é vital em áreas como exames médicos, defesa e arquivos digitais, onde mesmo pequenas alterações permanentes podem ser inaceitáveis. Embora tais técnicas estejam bem desenvolvidas para imagens 2D, aplicá‑las a modelos 3D é mais difícil porque as formas são irregulares e conectadas de maneiras complexas, o que torna complicado ocultar dados sem perturbar visivelmente a geometria.
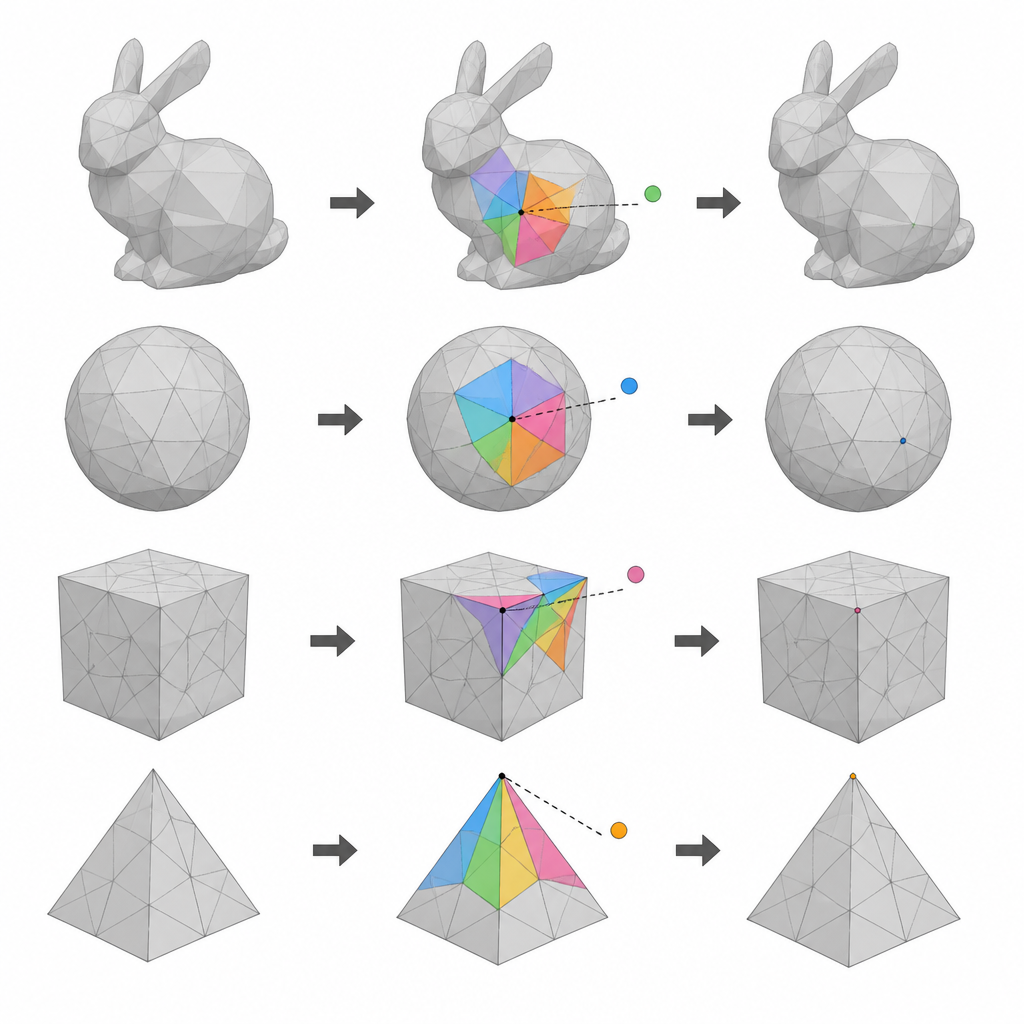
Usando camadas de pontos em uma superfície 3D
Os autores concentram‑se em modelos de malha 3D, que descrevem um objeto como uma rede de pontos (vértices) conectados em pequenas faces. A primeira ideia é dividir todos os vértices em três grupos usando seus números de índice. Dois desses grupos se revezam como candidatos para ocultação de dados, enquanto o grupo restante fornece pontos de referência que devem permanecer intocados durante cada passagem. Ao realizar duas rodadas de inserção, alternando quais grupos são usados como candidatos e quais como referências, o método pode usar muito mais vértices para transportar dados do que esquemas anteriores de passagem única, sem perder a capacidade de restaurar o modelo original.
Deixando pontos vizinhos preverem uns aos outros
A segunda ideia-chave baseia‑se no fato de que pontos vizinhos em uma superfície 3D suave costumam ficar próximos de uma posição média simples. Para qualquer vértice candidato, o método forma um pequeno polígono a partir da maioria de seus vizinhos que estejam atualmente no grupo de referência. Em seguida prediz onde o vértice deveria estar com base nesses vizinhos e mede a pequena diferença entre a predição e a posição real. Esses erros de predição formam um conjunto compacto e bem comportado de valores que podem ser suavemente esticados e deslocados para codificar bits de dados. Como os vizinhos intocados permanecem fixos, as mesmas predições podem ser repetidas depois, o que é essencial tanto para recuperar os dados ocultos quanto para restaurar as coordenadas originais.
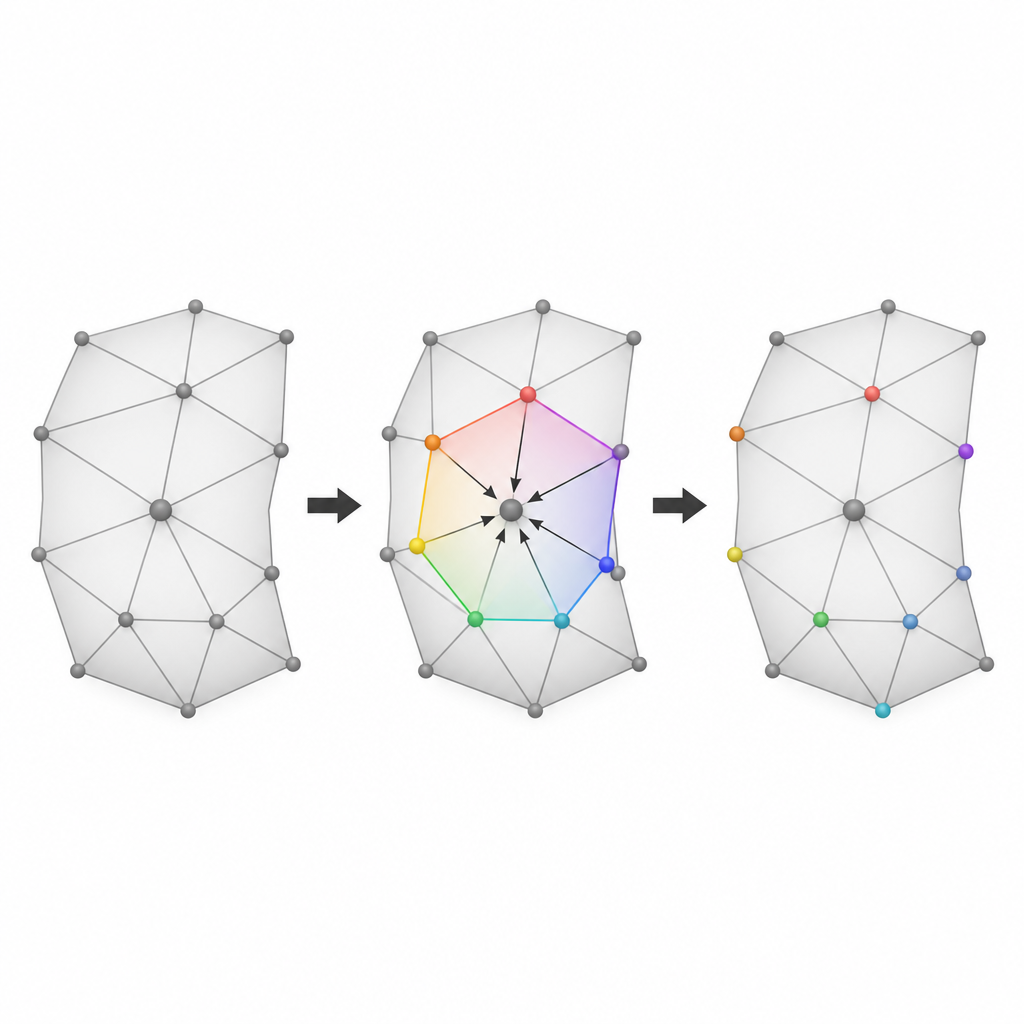
Escolhendo os lugares mais suaves para ocultar dados
A terceira ideia é ser seletivo sobre onde começar a ocultação. Os autores avaliam cada pequena vizinhança ao redor de um vértice candidato pelo quão suave e regular ela é. Uma medida verifica quão próxima a soma de seus ângulos está da de um polígono plano, enquanto outra verifica quão semelhantes são os comprimentos de suas arestas. Essas duas pontuações são combinadas em um único valor de prioridade. Vizinhanças que são mais suaves e regulares tendem a produzir erros de predição menores, de modo que deslocá‑las perturba menos a superfície. Ao ordenar todas as regiões candidatas de acordo com essa medida combinada de suavidade e inserir dados começando pelas melhores, o método mantém a distorção visível baixa mesmo ao ocultar uma grande quantidade de informação.
Testes em modelos 3D comuns
A equipe avaliou seu método em malhas 3D bem conhecidas, como o Stanford Bunny, um cavalo, uma mão e um dragão, comparando‑o com várias técnicas líderes. Eles mediram tanto quantos bits podiam ser armazenados por vértice quanto quanto a geometria mudou, usando uma medida padrão de relação sinal‑ruído. Sua abordagem alcançou maior capacidade de dados do que as demais enquanto mantinha a alteração de forma pequena, frequentemente melhorando a pontuação de qualidade em vários decibéis. Mesmo ao armazenar mais de uma vez e meia bits por vértice, a maioria dos modelos permaneceu visualmente quase inalterada, e o método executou em segundos a dezenas de segundos mesmo para malhas com centenas de milhares de vértices.
O que isso significa para o conteúdo 3D digital
Em termos práticos, este trabalho mostra que é possível incorporar quantidades significativas de informação em modelos 3D detalhados preservando tanto a aparência quanto a capacidade de reverter perfeitamente ao original. Ao combinar uso em camadas dos vértices, predição baseada em vizinhança e uma escolha cuidadosa de onde inserir, o método oferece uma melhor relação entre capacidade de armazenamento e qualidade da forma do que abordagens anteriores. Isso o torna um bloco de construção promissor para rotulagem segura, verificação de integridade e anotação do universo crescente de conteúdo 3D.
Citação: Wang, Q., Zhang, Q., Song, X. et al. Reversible data hiding for 3D mesh models based on spatial polygon prediction and dual sorting. Sci Rep 16, 16097 (2026). https://doi.org/10.1038/s41598-026-47050-3
Palavras-chave: inserção reversível de dados, malha 3D, marcação digital, proteção de direitos autorais, distorção geométrica