Clear Sky Science · sv
Dela upp och slå ihop: metoder för att passa logistisk regression på stora hälsoövervakningsdata: tillämpning för att förutsäga diabetesrisk i BRFSS
Varför stora hälsoundersökningar är viktiga för diabetes
Diabetes drabbar fler människor för varje år, men vårdsystemen har svårt att tidigt identifiera vilka som löper risk att drabbas av allvarliga problem. Regeringar samlar in enorma hälsoundersökningar med miljontals vuxna, men dessa gigantiska filer är svåra att analysera på vanliga datorer. Denna studie visar hur en smart metod för att dela upp och slå ihop data kan förvandla sådana otympliga undersökningar till praktiska verktyg för att förutsäga vem som mest sannolikt utvecklar diabetes, utan att behöva en superdator.

Dela stora data i lagom bitar
Författarna fokuserar på en teknik som kallas dela upp och slå ihop, som behandlar en massiv datamängd som ett bröd som kan skivas och sedan sättas ihop igen. Istället för att köra en enda enorm statistisk modell på all data på en gång, delar de upp datan i mindre delar, passar samma prediktionsmodell separat på varje del och kombinerar sedan resultaten på ett principfast sätt. Nyckelidén är att varje skiva av data bär information om hur riskfaktorer relaterar till diabetes, och dessa delar kan slås samman med matematiska vikter som speglar hur mycket information varje skiva innehåller.
Sätta metoden på ett tufft prov
För att avgöra om denna dela upp-och-slå ihop-strategi är pålitlig genomförde teamet först ett stort datorexperiment med simulerade data. De skapade fem miljoner virtuella patienter om och om igen, var och en med flera riskfaktorer och en känd "sann" relation till diabetes. De jämförde sedan traditionell analys av hela datamängden med dela upp-och-slå ihop-metoden för olika antal delar. Resultaten var anmärkningsvärda: delningsmetoden gav nästan identiska svar, med fel som skiljde sig först i fjärde decimalen, samtidigt som beräkningstiden halverades ungefär och minnesbehoven minskade med upp till nästan nittio procent.
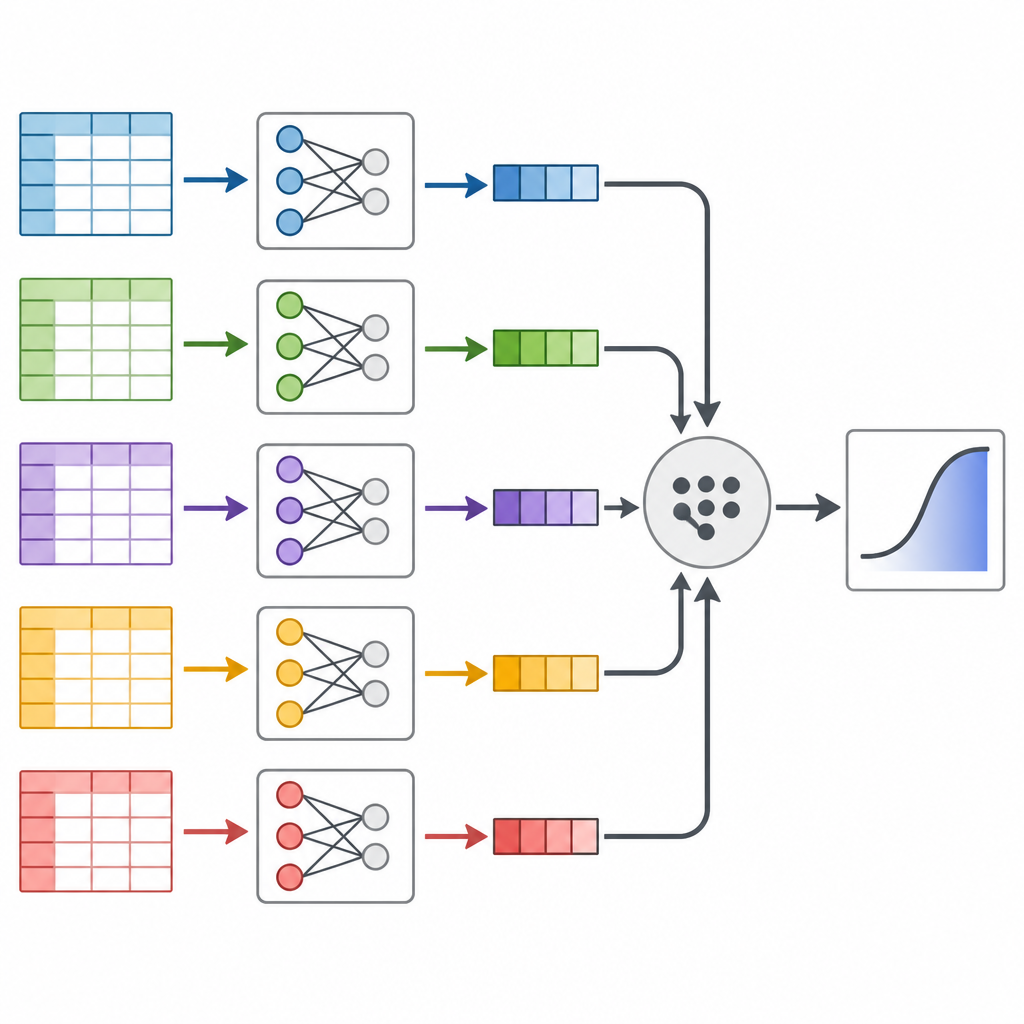
Testa tillvägagångssättet på verkliga amerikaner
Nästa steg för forskarna var att använda Behavioral Risk Factor Surveillance System, en långvarig amerikansk telefonundersökning som följer hälsovanor och tillstånd. De hämtade data från 2014 till 2024 för vuxna i åldern 40 år och uppåt, vilket gav nästan 2,5 miljoner personer och information om 16 faktorer såsom ålder, kroppsvikt, motion, rökning, inkomst och självskattad hälsa. Efter noggrann datarensning och att slumpa ordningen på personerna delade de upp undersökningen i dussintals hanterbara bitar, passade diabetesriskmodellen på varje bit och slog sedan ihop resultaten. De körde också två standardmetoder som använder hela datamängden på en gång för att se om svaren stämde överens.
Vad data säger om diabetesrisk
Resultaten från dela upp-och-slå ihop stämde nästan perfekt överens med de traditionella analyserna, vilket bekräftar att genvägen inte förvränger slutsatserna. Modellen återfann välkända mönster: oddsen för diabetes ökar brant med åldern och är flera gånger högre bland personer med fetma än bland dem med normalvikt. Personer som uppgav måttlig eller dålig allmänhälsa, som inte motionerar eller som för närvarande röker hade också högre odds. I kontrast var högre inkomst och fler skolår kopplade till lägre odds, även efter att vikt och vanor beaktats, vilket pekar på sociala förhållandens roll. Vissa långvariga sjukdomar i undersökningen visade förvånande inversa samband med diabetes, vilket författarna tillskriver överlevnads- och mätproblem i en tvärsnittsstudie snarare än verkligt skydd.
Vad detta betyder för vardagliga hälsobeslut
För icke-specialister är huvudbudskapet att befintliga nationella hälsoundersökningar kan omvandlas till pålitliga kalkylatorer för diabetesrisk med vanliga datorer. Dela upp-och-slå ihop-strategin behåller den statistiska kvaliteten hos traditionella metoder samtidigt som den gör det praktiskt möjligt att arbeta med miljontals poster. Det gör det lättare för folkhälsomyndigheter och forskare med begränsade resurser att följa vilka som är mest utsatta, rikta förebyggande program mot äldre vuxna med fetma och lägre inkomst, och uppdatera dessa insikter när nya undersökningsår läggs till. Metoden botar inte diabetes, men hjälper samhället att använda sina data klokare för att förebygga och hantera sjukdomen.
Citering: Nayem, M.M.H., Biswas, S.C. Divide and recombine approaches for fitting logistic regression to large-scale health surveillance data: application to diabetes risk prediction in BRFSS. Sci Rep 16, 15980 (2026). https://doi.org/10.1038/s41598-026-46927-7
Nyckelord: diabetesrisk, hälsostor data, logistisk regression, BRFSS-undersökning, dela upp och slå ihop