Clear Sky Science · de
Divide-and-Recombine-Ansätze zur Anpassung logistischer Regressionen an groß angelegte Gesundheitsüberwachungsdaten: Anwendung auf die Diabetes-Risikovorhersage in BRFSS
Warum große Gesundheitsumfragen für Diabetes wichtig sind
Diabetes betrifft jedes Jahr immer mehr Menschen, doch Gesundheitssysteme tun sich schwer, rechtzeitig diejenigen zu erkennen, die ein erhöhtes Risiko haben, um schwere Folgen zu verhindern. Staaten erheben riesige Gesundheitsbefragungen mit Millionen erwachsenen Teilnehmern, aber diese gigantischen Dateien sind auf normalen Computern schwer zu analysieren. Diese Studie zeigt, wie eine clevere Methode des Teilens und Wiederzusammenfügens Daten handhabbar macht und sie zu praktischen Werkzeugen zur Vorhersage des Diabetesrisikos macht — ohne Supercomputer.

Große Daten in mundgerechte Stücke zerteilen
Die Autoren konzentrieren sich auf eine Technik namens Divide and Recombine, die einen massiven Datensatz wie ein Brotlaib behandelt, den man in Scheiben schneiden und anschließend wieder zusammensetzen kann. Statt ein einziges riesiges statistisches Modell über alle Daten laufen zu lassen, teilen sie die Daten in kleinere Stücke, passen dasselbe Vorhersagemodell separat an jedes Stück an und kombinieren dann die Ergebnisse auf eine prinzipientreue Weise. Die Kernidee ist, dass jede Datenscheibe Informationen darüber trägt, wie Risikofaktoren mit Diabetes zusammenhängen, und diese Teilinformationen mit mathematischen Gewichten zusammengeführt werden können, die widerspiegeln, wie viel Information jede Scheibe enthält.
Die Methode einem harten Test unterziehen
Um zu prüfen, ob diese Teile-und-Zusammenfügen-Strategie verlässlich ist, führte das Team zunächst ein großes Computerexperiment mit simulierten Daten durch. Sie erzeugten wiederholt fünf Millionen virtuelle Patienten, jeweils mit mehreren Risikofaktoren und einer bekannten „wahren“ Beziehung zu Diabetes. Anschließend verglichen sie die traditionelle Analyse des vollen Datensatzes mit dem Divide-and-Recombine-Ansatz bei verschiedenen Anzahlen von Scheiben. Die Ergebnisse waren beeindruckend: Die geteilte Methode lieferte nahezu identische Antworten, mit Abweichungen nur in der vierten Dezimalstelle, während die Rechenzeit etwa halbiert und der Speicherbedarf um bis zu fast neunzig Prozent reduziert wurde.
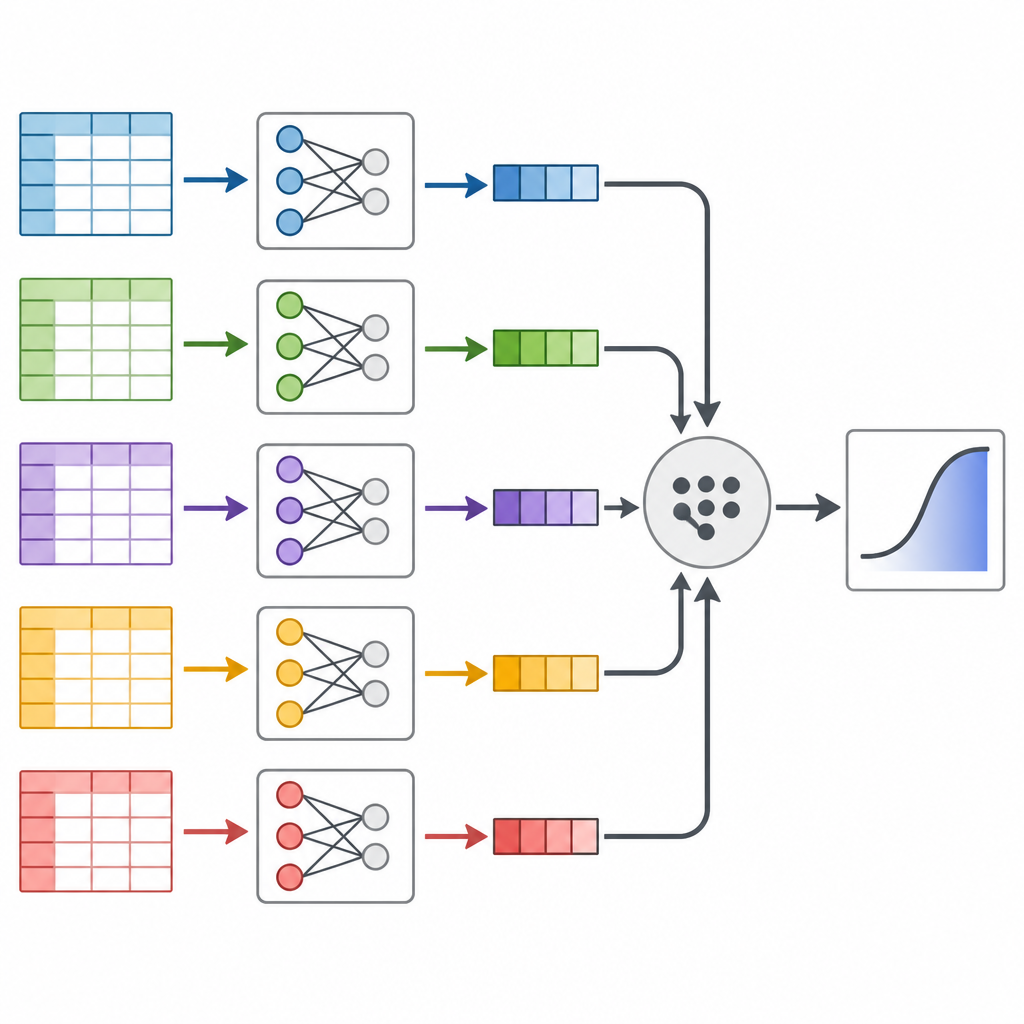
Die Methode an realen US-Daten testen
Anschließend wandten die Forschenden die Methode auf das Behavioral Risk Factor Surveillance System an, eine langjährige US-Telefonumfrage, die Gesundheitsgewohnheiten und -zustände erfasst. Sie nutzten Daten von 2014 bis 2024 für Erwachsene ab 40 Jahren und kamen so auf fast 2,5 Millionen Personen mit Informationen zu 16 Faktoren wie Alter, Körpergewicht, Bewegung, Rauchen, Einkommen und selbstberichteter Gesundheit. Nach sorgfältiger Bereinigung der Daten und dem Durchmischen der Reihenfolge der Personen teilten sie die Umfrage in Dutzende handhabbare Blöcke, passten das Diabetesrisikomodell in jedem Block an und setzten die Ergebnisse wieder zusammen. Zur Validierung führten sie außerdem zwei Standardverfahren durch, die die vollständigen Daten auf einmal verwenden, um die Übereinstimmung zu prüfen.
Was die Daten zum Diabetesrisiko aussagen
Die Ergebnisse des Divide-and-Recombine-Verfahrens stimmten nahezu perfekt mit den traditionellen Analysen überein und bestätigten, dass die Abkürzung die wissenschaftlichen Aussagen nicht verzerrt. Das Modell stellte bekannte Muster heraus: Die Odds für Diabetes steigen stark mit dem Alter und sind bei Menschen mit Adipositas mehrere Male höher als bei Normalgewichtigen. Personen, die ihre allgemeine Gesundheit als mäßig oder schlecht einstufen, die sich nicht bewegen oder aktuell rauchen, hatten ebenfalls höhere Odds. Dagegen waren höheres Einkommen und mehr Schuljahre mit geringeren Odds verbunden, selbst nachdem Gewicht und Lebensstil berücksichtigt wurden — ein Hinweis auf die Rolle sozialer Bedingungen. Einige langfristige Erkrankungen in der Umfrage zeigten rätselhafte inverse Zusammenhänge mit Diabetes, die die Autorinnen und Autoren eher Überlebens- und Messartefakten in einer einmaligen Querschnittsstudie als echten Schutz zuschreiben.
Was das für alltägliche Gesundheitsentscheidungen bedeutet
Für Nicht-Fachleute ist die zentrale Botschaft: Bestehende nationale Gesundheitsumfragen lassen sich mit normalen Computern in verlässliche Diabetes-Risikorechner verwandeln. Die Divide-and-Recombine-Strategie bewahrt die statistische Qualität traditioneller Methoden und macht es zugleich möglich, mit Millionen von Datensätzen zu arbeiten. Das erleichtert es Gesundheitsbehörden und Forschenden mit begrenzten Ressourcen, diejenigen zu verfolgen, die am stärksten gefährdet sind, Präventionsprogramme gezielt auf ältere Menschen mit Adipositas und geringerem Einkommen auszurichten und diese Erkenntnisse mit neuen Umfragejahren zu aktualisieren. Die Methode heilt Diabetes nicht, hilft der Gesellschaft aber, ihre Daten klüger zu nutzen, um die Krankheit zu verhindern und zu managen.
Zitation: Nayem, M.M.H., Biswas, S.C. Divide and recombine approaches for fitting logistic regression to large-scale health surveillance data: application to diabetes risk prediction in BRFSS. Sci Rep 16, 15980 (2026). https://doi.org/10.1038/s41598-026-46927-7
Schlüsselwörter: Diabetesrisiko, Gesundheits-Big-Data, logistische Regression, BRFSS-Umfrage, Divide and Recombine