Clear Sky Science · pt
Abordagens de dividir e recombinar para ajustar regressão logística a dados de vigilância em saúde em grande escala: aplicação à predição de risco de diabetes no BRFSS
Por que grandes pesquisas de saúde importam para o diabetes
O diabetes atinge mais pessoas a cada ano, mas os sistemas de saúde têm dificuldade em identificar quem está em risco cedo o bastante para evitar problemas graves. Governos coletam enormes pesquisas de saúde com milhões de adultos, mas esses arquivos gigantescos são difíceis de analisar em computadores comuns. Este estudo mostra como uma forma inteligente de dividir e recombinar dados pode transformar essas pesquisas pesadas em ferramentas práticas para prever quem tem maior probabilidade de desenvolver diabetes, sem precisar de um supercomputador.

Transformando grandes dados em pedaços manejáveis
Os autores focam em uma técnica chamada dividir e recombinar, que trata um conjunto de dados massivo como um pão que pode ser fatiado e depois remontado. Em vez de rodar um único modelo estatístico enorme em todos os dados de uma vez, eles cortam os dados em partes menores, ajustam o mesmo modelo de predição separadamente em cada parte e então combinam os resultados de maneira principiada. A ideia-chave é que cada fatia de dados carrega informação sobre como os fatores de risco se relacionam com o diabetes, e essas peças podem ser unidas usando pesos matemáticos que refletem quanta informação cada fatia contém.
Colocando o método à prova
Para verificar se essa estratégia de dividir e juntar é confiável, a equipe primeiro executou um grande experimento computacional com dados simulados. Eles criaram cinco milhões de pacientes virtuais repetidamente, cada um com vários fatores de risco e uma relação “verdadeira” conhecida com o diabetes. Em seguida compararam a análise tradicional do conjunto completo de dados com a abordagem de dividir e recombinar sob diferentes números de fatias. Os resultados foram impressionantes: o método dividido produziu respostas quase idênticas, com erros que diferiam apenas na quarta casa decimal, enquanto reduzia o tempo de computação em cerca de metade e cortava a necessidade de memória em até quase noventa por cento.
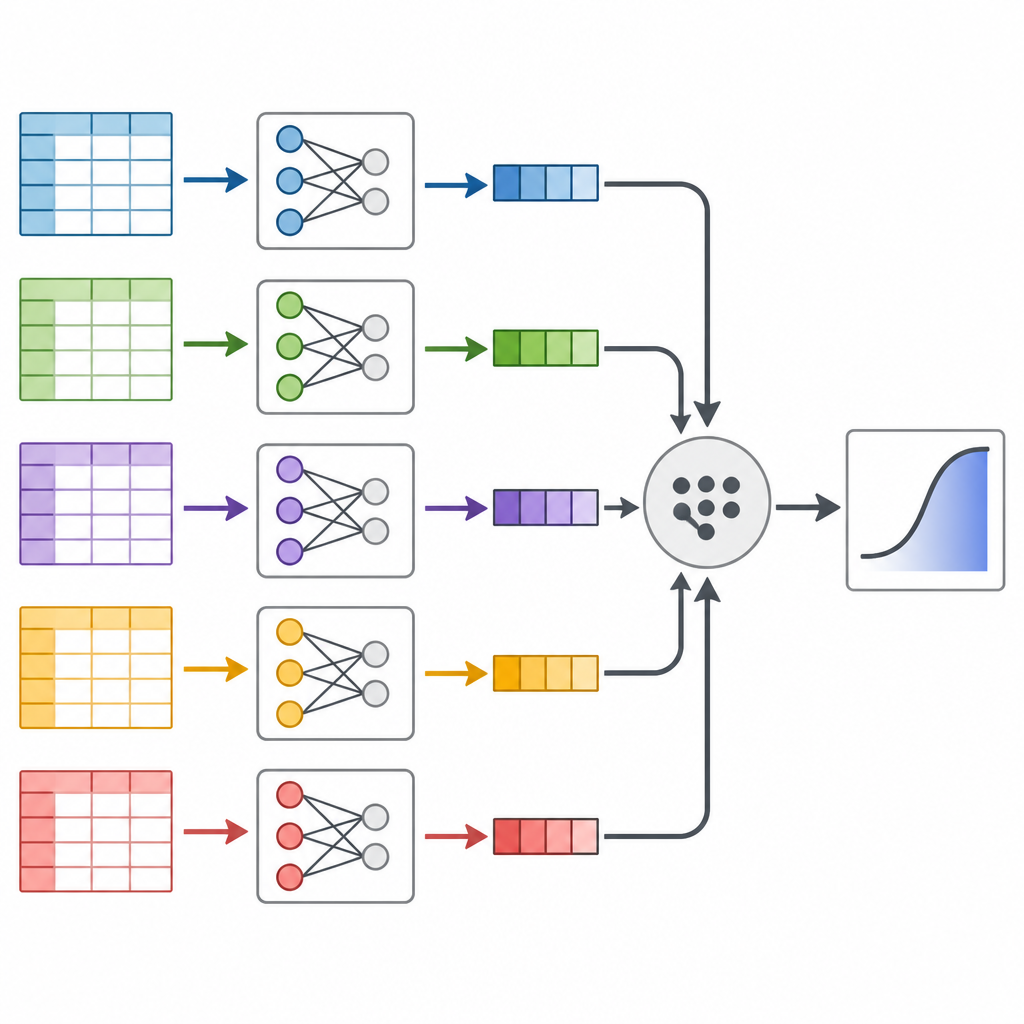
Testando a abordagem em americanos reais
Em seguida, os pesquisadores recorreram ao Behavioral Risk Factor Surveillance System, uma pesquisa telefônica de longa duração nos EUA que acompanha hábitos e condições de saúde. Eles extraíram dados de 2014 a 2024 para adultos com 40 anos ou mais, chegando a quase 2,5 milhões de pessoas e informações sobre 16 fatores, como idade, peso corporal, exercício, tabagismo, renda e autopercepção de saúde. Após limpar cuidadosamente os dados e embaralhar a ordem dos indivíduos, dividiram a pesquisa em dezenas de blocos manejáveis, ajustaram o modelo de risco de diabetes em cada bloco e recombinaram os resultados. Também rodaram dois métodos padrão que usam todos os dados de uma vez, para verificar se as respostas coincidiavam.
O que os dados mostram sobre o risco de diabetes
Os resultados do dividir e recombinar coincidiram quase perfeitamente com as análises tradicionais, confirmando que o atalho não distorce a ciência. O modelo recuperou padrões bem conhecidos: as chances de diabetes aumentam rapidamente com a idade e são várias vezes maiores entre pessoas com obesidade do que entre as de peso normal. Pessoas que relatam saúde geral regular ou ruim, que não se exercitam ou que fumam atualmente também apresentaram maiores chances. Em contraste, maior renda e mais anos de escolaridade foram associados a menores chances, mesmo depois de controlar por peso e hábitos, apontando para o papel das condições sociais. Algumas doenças de longa duração na pesquisa mostraram ligações inversas e surpreendentes com o diabetes, que os autores atribuem a efeitos de sobrevivência e a peculiaridades de medição em um estudo baseado em um retrato único, e não a proteção real.
O que isso significa para decisões de saúde do dia a dia
Para não especialistas, a mensagem principal é que pesquisas de saúde nacionais existentes podem ser transformadas em calculadoras confiáveis de risco de diabetes usando computadores comuns. A estratégia de dividir e recombinar mantém a qualidade estatística dos métodos tradicionais enquanto torna viável trabalhar com milhões de registros. Isso facilita para agências de saúde pública e pesquisadores com recursos limitados rastrear quem está mais em risco, direcionar programas de prevenção a adultos mais velhos com obesidade e renda mais baixa, e atualizar essas percepções à medida que novos anos da pesquisa são acrescentados. O método não cura o diabetes, mas ajuda a sociedade a usar seus dados de forma mais inteligente para prevenir e manejar a doença.
Citação: Nayem, M.M.H., Biswas, S.C. Divide and recombine approaches for fitting logistic regression to large-scale health surveillance data: application to diabetes risk prediction in BRFSS. Sci Rep 16, 15980 (2026). https://doi.org/10.1038/s41598-026-46927-7
Palavras-chave: risco de diabetes, big data em saúde, regressão logística, pesquisa BRFSS, dividir e recombinar