Clear Sky Science · fr
Approches de division et de recombinaison pour l’ajustement d’une régression logistique aux données de surveillance sanitaire à grande échelle : application à la prédiction du risque de diabète dans le BRFSS
Pourquoi les grandes enquêtes de santé comptent pour le diabète
Le diabète touche chaque année un nombre croissant de personnes, mais les systèmes de santé peinent à repérer suffisamment tôt ceux qui sont à risque pour prévenir les complications graves. Les gouvernements collectent d’immenses enquêtes de santé couvrant des millions d’adultes, mais ces fichiers gigantesques sont difficiles à analyser sur des ordinateurs ordinaires. Cette étude montre comment une méthode astucieuse de découpage et de recomposition des données peut transformer ces enquêtes ingérables en outils pratiques pour prédire qui est le plus susceptible de développer un diabète, sans nécessiter de superordinateur.

Découper les mégadonnées en portions faciles à traiter
Les auteurs s’intéressent à une technique appelée division et recombinaison, qui traite un jeu de données massif comme une miche de pain qu’on peut trancher puis reconstituer. Plutôt que d’exécuter un gigantesque modèle statistique sur l’ensemble des données d’un coup, ils coupent les données en morceaux plus petits, ajustent séparément le même modèle prédictif sur chaque morceau, puis combinent les résultats de manière rigoureuse. L’idée clé est que chaque tranche de données contient de l’information sur la façon dont les facteurs de risque se rapportent au diabète, et ces morceaux peuvent être fusionnés en appliquant des poids mathématiques qui reflètent la quantité d’information de chaque tranche.
Soumettre la méthode à un test exigeant
Pour vérifier si cette stratégie de division et fusion est fiable, l’équipe a d’abord réalisé une vaste expérience informatique avec des données simulées. Ils ont recréé à plusieurs reprises cinq millions de patients virtuels, chacun avec plusieurs facteurs de risque et une relation « vraie » connue au diabète. Ils ont ensuite comparé l’analyse traditionnelle sur l’ensemble des données avec l’approche de division et recombinaison selon différents nombres de tranches. Les résultats furent frappants : la méthode de découpage produisait des réponses quasiment identiques, avec des erreurs ne différant que au quatrième chiffre décimal, tout en réduisant le temps de calcul d’environ moitié et en diminuant les besoins mémoire jusqu’à presque quatre-vingt-dix pour cent.
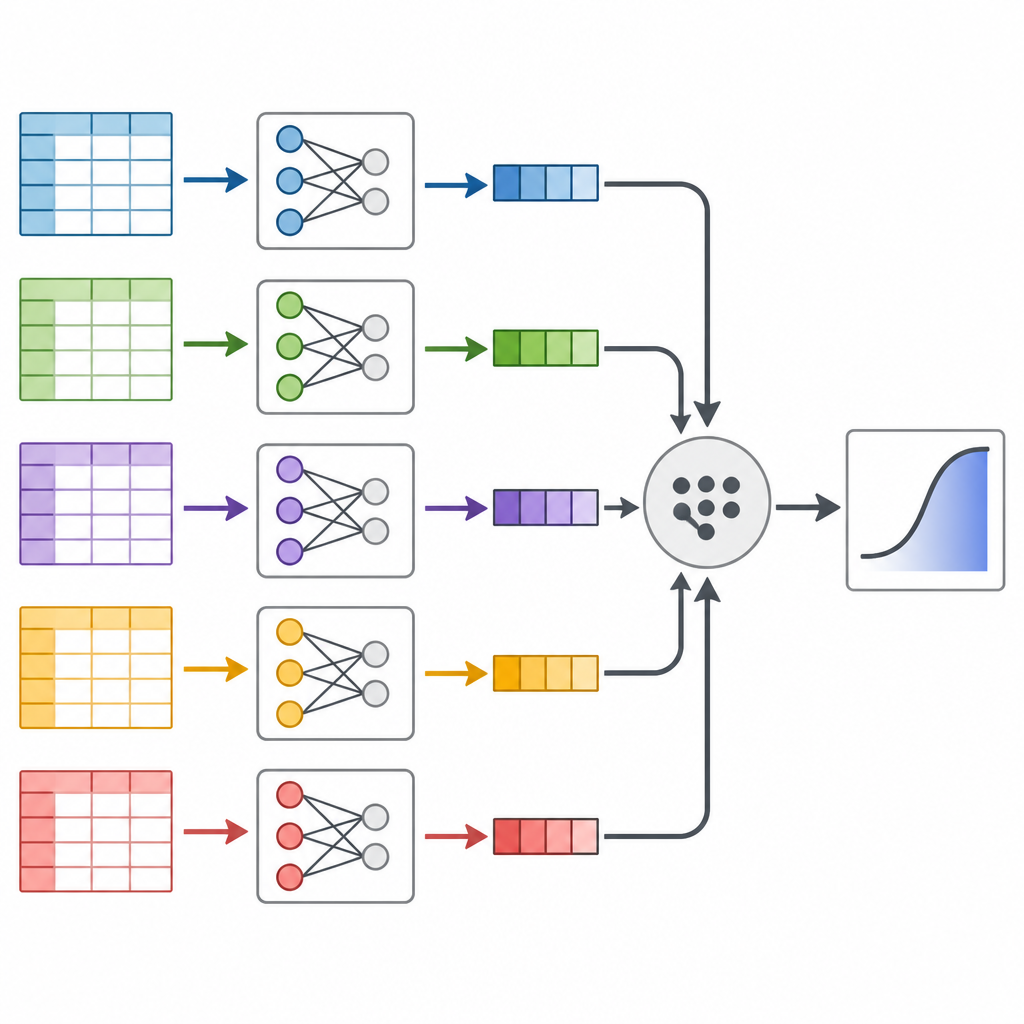
Tester l’approche sur des Américains réels
Puis, les chercheurs se sont tournés vers le Behavioral Risk Factor Surveillance System, une enquête téléphonique américaine de longue date qui suit les habitudes et les états de santé. Ils ont extrait les données de 2014 à 2024 pour les adultes de 40 ans et plus, obtenant près de 2,5 millions de personnes et des informations sur 16 facteurs comme l’âge, le poids corporel, l’exercice, le tabagisme, le revenu et l’auto-évaluation de la santé. Après un nettoyage attentif des données et un mélange de l’ordre des enregistrements, ils ont divisé l’enquête en dizaines de segments gérables, ajusté le modèle de risque de diabète sur chaque segment, puis recombiné les résultats. Ils ont aussi exécuté deux méthodes standard qui utilisent l’ensemble des données en une fois, pour vérifier si les résultats concordaient.
Ce que disent les données sur le risque de diabète
Les résultats obtenus par division et recombinaison se sont alignés presque parfaitement sur les analyses traditionnelles, confirmant que cette astuce ne déforme pas les conclusions scientifiques. Le modèle a retrouvé des profils bien connus : les probabilités de diabète augmentent fortement avec l’âge, et sont plusieurs fois supérieures chez les personnes obèses comparées à celles de poids normal. Les personnes se déclarant en santé générale moyenne ou mauvaise, ne pratiquant pas d’exercice, ou fumeuses actuelles présentaient également des probabilités plus élevées. En revanche, des revenus plus élevés et davantage d’années de scolarité étaient associés à des probabilités plus faibles, même après avoir pris en compte le poids et les comportements, soulignant le rôle des conditions sociales. Certaines maladies chroniques présentes dans l’enquête montraient des liens inverses paradoxaux avec le diabète, que les auteurs attribuent à des biais de survie et de mesure inhérents à une étude transversale plutôt qu’à une véritable protection.
Ce que cela signifie pour les décisions de santé courantes
Pour un public non spécialiste, le message principal est que les enquêtes nationales existantes peuvent être transformées en calculateurs de risque de diabète fiables en utilisant des ordinateurs ordinaires. La stratégie de division et recombinaison préserve la qualité statistique des méthodes traditionnelles tout en rendant possible le traitement de millions d’enregistrements. Cela facilite la tâche des agences de santé publique et des chercheurs aux ressources limitées pour repérer les personnes les plus à risque, cibler les programmes de prévention vers les adultes âgés souffrant d’obésité et à plus faible revenu, et mettre à jour ces connaissances au fur et à mesure de l’arrivée de nouvelles années d’enquête. La méthode ne guérit pas le diabète, mais elle aide la société à mieux exploiter ses données pour prévenir et gérer la maladie.
Citation: Nayem, M.M.H., Biswas, S.C. Divide and recombine approaches for fitting logistic regression to large-scale health surveillance data: application to diabetes risk prediction in BRFSS. Sci Rep 16, 15980 (2026). https://doi.org/10.1038/s41598-026-46927-7
Mots-clés: risque de diabète, big data en santé, régression logistique, enquête BRFSS, division et recombinaison