Clear Sky Science · it
Approcci di dividere e ricombinare per adattare la regressione logistica a dati di sorveglianza sanitaria su larga scala: applicazione alla previsione del rischio di diabete nel BRFSS
Perché i grandi sondaggi sanitari sono importanti per il diabete
Il diabete colpisce ogni anno sempre più persone, ma i sistemi sanitari faticano a individuare in tempo chi è a rischio per prevenire problemi gravi. I governi raccolgono enormi sondaggi sanitari con milioni di adulti, ma questi file giganteschi sono difficili da analizzare su computer ordinari. Questo studio mostra come un metodo intelligente di suddivisione e ricombinazione dei dati possa trasformare quei sondaggi ingombranti in strumenti pratici per prevedere chi è più probabile che sviluppi il diabete, senza bisogno di un supercomputer.

Spezzare i big data in pezzi gestibili
Gli autori si concentrano su una tecnica chiamata divide and recombine, che tratta un dataset massiccio come una pagnotta di pane che può essere affettata e poi riassemblata. Invece di eseguire un unico modello statistico enorme su tutti i dati insieme, dividono i dati in pezzi più piccoli, adattano lo stesso modello di previsione separatamente a ciascun pezzo e poi combinano i risultati in modo rigoroso. L'idea chiave è che ogni fetta di dati contiene informazioni su come i fattori di rischio si collegano al diabete, e quei pezzi possono essere uniti usando pesi matematici che riflettono quanta informazione contiene ciascuna fetta.
Mettere il metodo alla prova
Per verificare se questa strategia di dividere e unire è affidabile, il team ha prima condotto un ampio esperimento al computer con dati simulati. Hanno creato ripetutamente cinque milioni di pazienti virtuali, ciascuno con diversi fattori di rischio e una relazione “vera” nota con il diabete. Hanno quindi confrontato l'analisi tradizionale sull'intero dataset con l'approccio divide and recombine usando diversi numeri di suddivisioni. I risultati sono stati impressionanti: il metodo diviso ha prodotto risposte praticamente identiche, con errori che differivano solo alla quarta cifra decimale, riducendo al contempo il tempo di calcolo di circa la metà e abbattendo le esigenze di memoria fino a quasi il novanta percento.
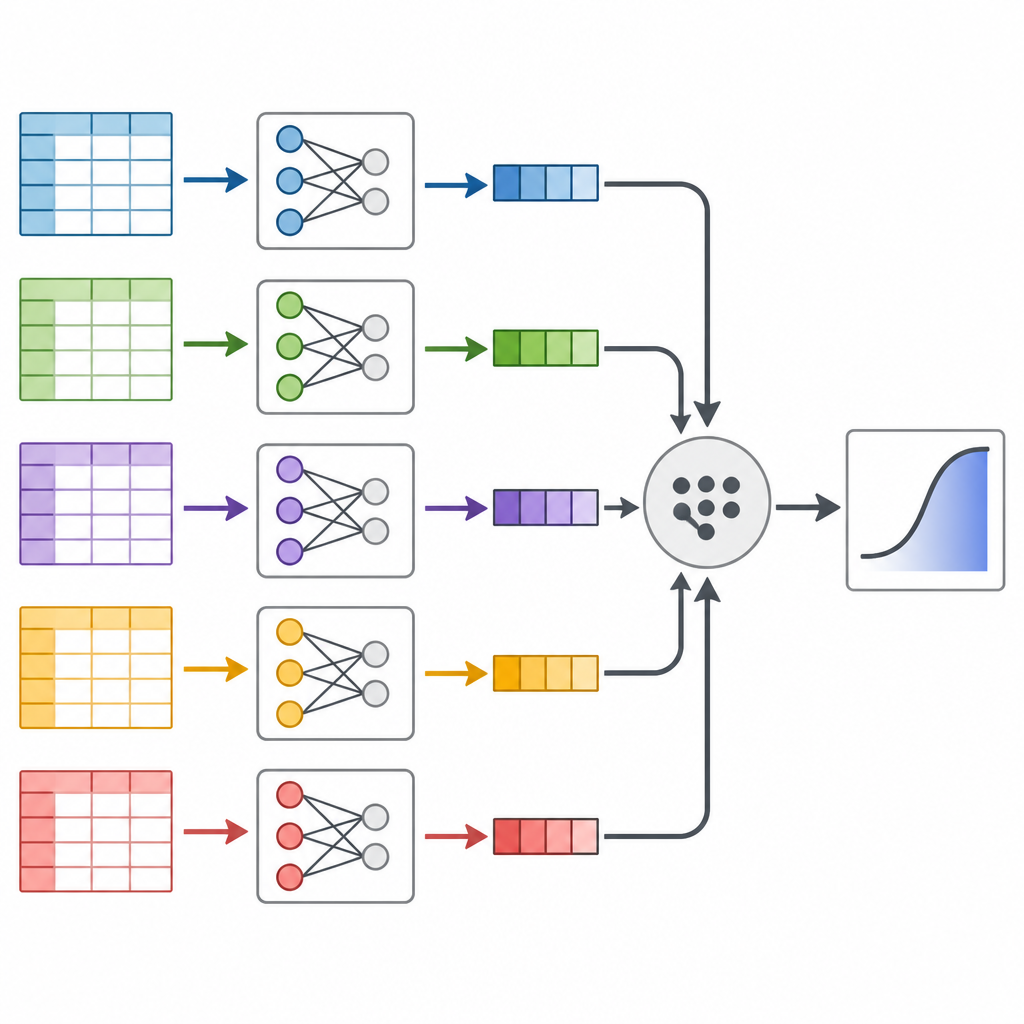
Testare l'approccio sugli americani reali
Successivamente, i ricercatori si sono rivolti al Behavioral Risk Factor Surveillance System, un sondaggio telefonico statunitense di lunga durata che monitora abitudini e condizioni di salute. Hanno estratto i dati dal 2014 al 2024 per adulti di età pari o superiore a 40 anni, ottenendo quasi 2,5 milioni di persone e informazioni su 16 fattori come età, peso corporeo, esercizio fisico, fumo, reddito e autovalutazione della salute. Dopo aver pulito con cura i dati e mescolato l'ordine dei partecipanti, hanno diviso il sondaggio in decine di blocchi gestibili, adattato il modello di rischio di diabete su ciascun blocco e ricombinato i risultati. Hanno inoltre eseguito due metodi standard che utilizzano l'intero dataset contemporaneamente, per verificare se le risposte coincidevano.
Cosa dicono i dati sul rischio di diabete
I risultati ottenuti con divide and recombine si sono allineati quasi perfettamente con le analisi tradizionali, confermando che la scorciatoia non distorce i risultati scientifici. Il modello ha recuperato pattern ben noti: le probabilità di diabete aumentano rapidamente con l'età e sono diverse volte più alte nelle persone con obesità rispetto a chi ha peso normale. Anche chi dichiara uno stato di salute generale mediocre o scarso, chi non fa esercizio o chi fuma attualmente aveva probabilità più elevate. Al contrario, un reddito più alto e più anni di istruzione sono risultati associati a probabilità inferiori, anche dopo aver considerato peso e abitudini, indicando il ruolo delle condizioni sociali. Alcune malattie croniche nel sondaggio hanno mostrato legami inversi e sorprendenti con il diabete, che gli autori attribuiscono a effetti di sopravvivenza e a peculiarità di misurazione in uno studio basato su un singolo istante anziché a una protezione reale.
Cosa significa per le decisioni sanitarie quotidiane
Per i non specialisti, il messaggio principale è che i sondaggi sanitari nazionali esistenti possono essere trasformati in calcolatori affidabili del rischio di diabete usando normali computer. La strategia divide and recombine preserva la qualità statistica dei metodi tradizionali rendendo al contempo fattibile lavorare con milioni di record. Ciò facilita per le agenzie di sanità pubblica e i ricercatori con risorse limitate il monitoraggio di chi è maggiormente a rischio, la mirazione di programmi di prevenzione verso adulti anziani con obesità e reddito più basso, e l'aggiornamento di queste informazioni man mano che si aggiungono nuovi anni di sondaggio. Il metodo non cura il diabete, ma aiuta la collettività a usare meglio i propri dati per prevenirlo e gestirlo.
Citazione: Nayem, M.M.H., Biswas, S.C. Divide and recombine approaches for fitting logistic regression to large-scale health surveillance data: application to diabetes risk prediction in BRFSS. Sci Rep 16, 15980 (2026). https://doi.org/10.1038/s41598-026-46927-7
Parole chiave: rischio di diabete, big data sanitari, regressione logistica, sondaggio BRFSS, dividere e ricombinare