Clear Sky Science · nl
Verdelen en opnieuw samenvoegen: benaderingen voor het fitten van logistische regressie op grootschalige gezondheidsgegevens: toepassing op diabetesrisicovoorspelling in BRFSS
Waarom grote gezondheidsenquêtes van belang zijn voor diabetes
Diabetes treft elk jaar meer mensen, maar zorgsystemen hebben moeite om tijdig te herkennen wie risico loopt om ernstige problemen te voorkomen. Overheden verzamelen enorme gezondheidsenquêtes met miljoenen volwassenen, maar die gigantische bestanden zijn lastig te analyseren op gewone computers. Deze studie laat zien hoe een slimme manier om gegevens te splitsen en opnieuw samen te voegen van die onhandelbare enquêtes praktische instrumenten kan maken om te voorspellen wie waarschijnlijk diabetes ontwikkelt, zonder dat er een supercomputer nodig is.

Grote data opdelen in hapklare brokken
De auteurs richten zich op een techniek genaamd verdeel en opnieuw samenvoegen, die een massa dataset behandelt als een brood dat in plakken kan worden gesneden en vervolgens weer samengevoegd. In plaats van één enorm statistisch model op alle data tegelijk los te laten, knippen ze de data in kleinere stukken, passen hetzelfde voorspellende model afzonderlijk op elk stuk toe en combineren daarna de resultaten op een principiële manier. Het kernidee is dat elk datastuk informatie draagt over hoe risicofactoren samenhangen met diabetes, en die stukken kunnen worden samengevoegd met wiskundige gewichten die aangeven hoeveel informatie elk stuk bevat.
De methode aan een zware test onderwerpen
Om te onderzoeken of deze split-en-merge strategie betrouwbaar is, voerde het team eerst een groot computerexperiment uit met gesimuleerde data. Ze creëerden herhaaldelijk vijf miljoen virtuele patiënten, elk met meerdere risicofactoren en een bekend "waar" verband met diabetes. Vervolgens vergeleken ze de traditionele analyse van de volledige dataset met de verdeel-en-herschik benadering bij verschillende aantallen stukken. De resultaten waren opvallend: de gesplitste methode leverde vrijwel identieke antwoorden op, met fouten die slechts in het vierde decimaal verschilden, terwijl de rekentijd ongeveer gehalveerd werd en het geheugenverbruik met bijna negentig procent kon dalen.
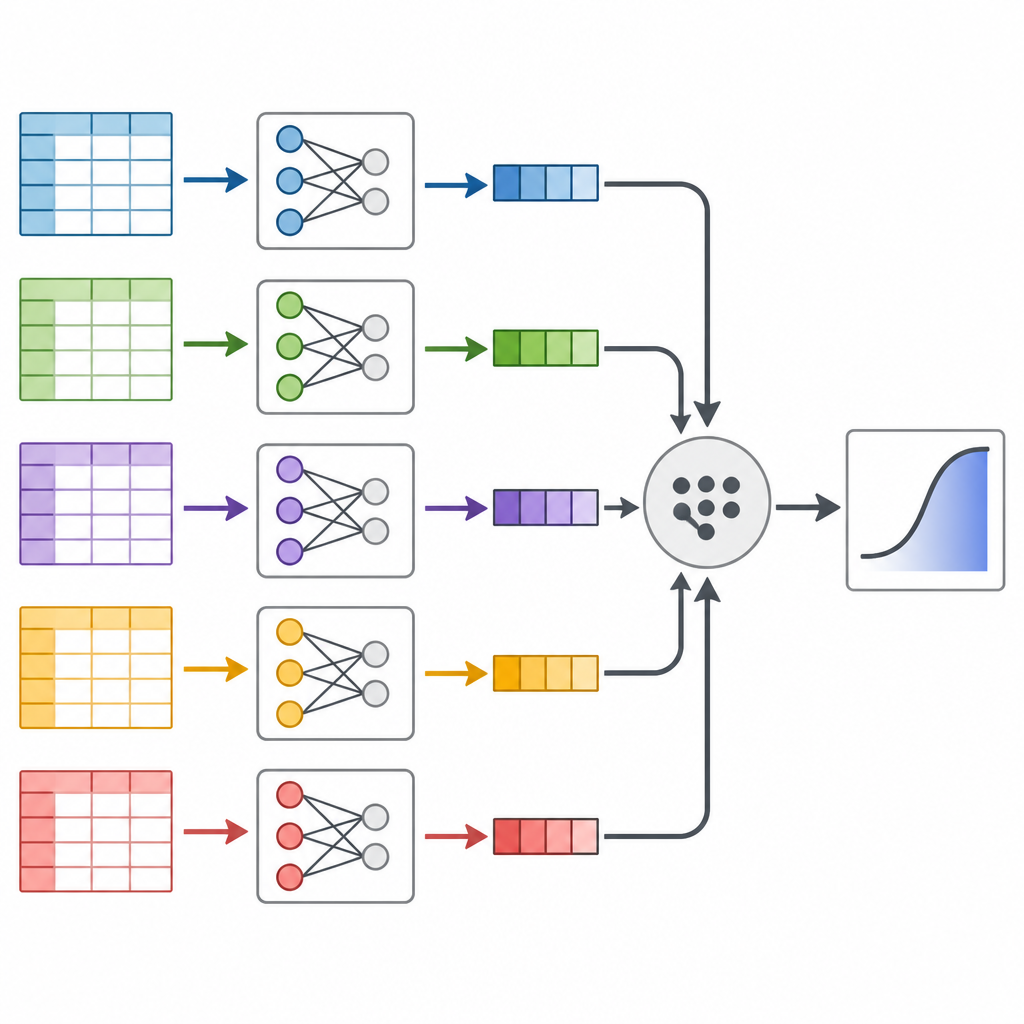
De aanpak testen op echte Amerikanen
Vervolgens richtten de onderzoekers zich op het Behavioral Risk Factor Surveillance System, een langlopende Amerikaanse telefonische enquête die gezondheidsgewoonten en aandoeningen volgt. Ze haalden gegevens uit 2014 tot 2024 voor volwassenen van 40 jaar en ouder, en kwamen uit op bijna 2,5 miljoen mensen met informatie over 16 factoren zoals leeftijd, lichaamsgewicht, beweging, roken, inkomen en zelfgerapporteerde gezondheid. Na zorgvuldige opschoning van de data en het willekeurig herschikken van de volgorde van personen, splitsten ze de enquête in tientallen hanteerbare brokken, pasten het diabetesrisicomodel op elk brok toe en voegden de resultaten weer samen. Ze voerden ook twee standaardmethoden uit die de volledige data in één keer gebruiken, om te zien of de uitkomsten overeenkwamen.
Wat de data zeggen over diabetesrisico
De verdeel-en-herschik resultaten kwamen bijna perfect overeen met de traditionele analyses, wat bevestigt dat de verkorte aanpak de wetenschap niet vervormt. Het model bracht goed bekende patronen naar voren: de kans op diabetes neemt sterk toe met leeftijd en is meerdere keren hoger bij mensen met obesitas dan bij mensen met een normaal gewicht. Mensen die hun algemene gezondheid als matig of slecht rapporteren, die niet bewegen of die momenteel roken, hadden ook hogere kansen. Daartegenover stonden een hoger inkomen en meer jaren onderwijs, die zelfs na correctie voor gewicht en gedrag gekoppeld waren aan lagere kansen, wat wijst op de rol van sociale omstandigheden. Sommige langdurige ziekten in de enquête toonden puzzelende inverse verbanden met diabetes, wat de auteurs toeschrijven aan overlevings- en meetproblemen in een eensprongstudie in plaats van aan echte bescherming.
Wat dit betekent voor alledaagse gezondheidsbeslissingen
Voor niet-specialisten is de belangrijkste boodschap dat bestaande nationale gezondheidsenquêtes kunnen worden omgevormd tot betrouwbare diabetesrisicocalculators met gewone computers. De verdeel-en-herschik strategie behoudt de statistische kwaliteit van traditionele methoden en maakt het tegelijkertijd haalbaar om met miljoenen records te werken. Dat maakt het makkelijker voor volksgezondheidsinstanties en onderzoekers met beperkte middelen om te volgen wie het meest risico loopt, preventieprogramma's te richten op oudere volwassenen met obesitas en lagere inkomens, en deze inzichten bij te werken zodra nieuwe enquêtejaren beschikbaar komen. De methode geneest geen diabetes, maar helpt de maatschappij haar data slimmer te gebruiken om de ziekte te voorkomen en te beheersen.
Bronvermelding: Nayem, M.M.H., Biswas, S.C. Divide and recombine approaches for fitting logistic regression to large-scale health surveillance data: application to diabetes risk prediction in BRFSS. Sci Rep 16, 15980 (2026). https://doi.org/10.1038/s41598-026-46927-7
Trefwoorden: diabetesrisico, gezondheid big data, logistische regressie, BRFSS-enquête, verdelen en opnieuw samenvoegen