Clear Sky Science · es
Enfoques de dividir y recombinar para ajustar regresión logística a datos de vigilancia de salud a gran escala: aplicación a la predicción del riesgo de diabetes en BRFSS
Por qué importan las grandes encuestas de salud para la diabetes
La diabetes afecta a más personas cada año, pero los sistemas de salud tienen dificultades para identificar a quienes están en riesgo con suficiente antelación para prevenir complicaciones graves. Los gobiernos recogen enormes encuestas de salud con millones de adultos, pero esos archivos gigantes son difíciles de analizar en ordenadores corrientes. Este estudio muestra cómo una forma ingeniosa de dividir y recombinar los datos puede convertir esas encuestas inmanejables en herramientas prácticas para predecir quién tiene más probabilidad de desarrollar diabetes, sin necesidad de un superordenador.

Partir los grandes datos en porciones manejables
Los autores se centran en una técnica llamada dividir y recombinar, que trata un conjunto de datos masivo como un pan que puede cortarse en rebanadas y luego volver a ensamblarse. En lugar de ejecutar un único modelo estadístico enorme sobre todos los datos a la vez, cortan los datos en piezas más pequeñas, ajustan el mismo modelo de predicción por separado a cada pieza y luego combinan los resultados de forma rigurosa. La idea clave es que cada porción de datos contiene información sobre cómo los factores de riesgo se relacionan con la diabetes, y esas partes pueden fusionarse usando pesos matemáticos que reflejan cuánta información aporta cada porción.
Poner el método a una prueba exigente
Para comprobar si esta estrategia de dividir y unir es fiable, el equipo primero realizó un gran experimento por computadora con datos simulados. Crearon cinco millones de pacientes virtuales una y otra vez, cada uno con varios factores de riesgo y una relación "verdadera" conocida con la diabetes. Luego compararon el análisis tradicional del conjunto completo con el enfoque de dividir y recombinar bajo distintos números de particiones. Los resultados fueron contundentes: el método dividido produjo respuestas casi idénticas, con errores que diferían solo en la cuarta cifra decimal, mientras reducía el tiempo de cálculo en alrededor de la mitad y recortaba las necesidades de memoria hasta casi un noventa por ciento.
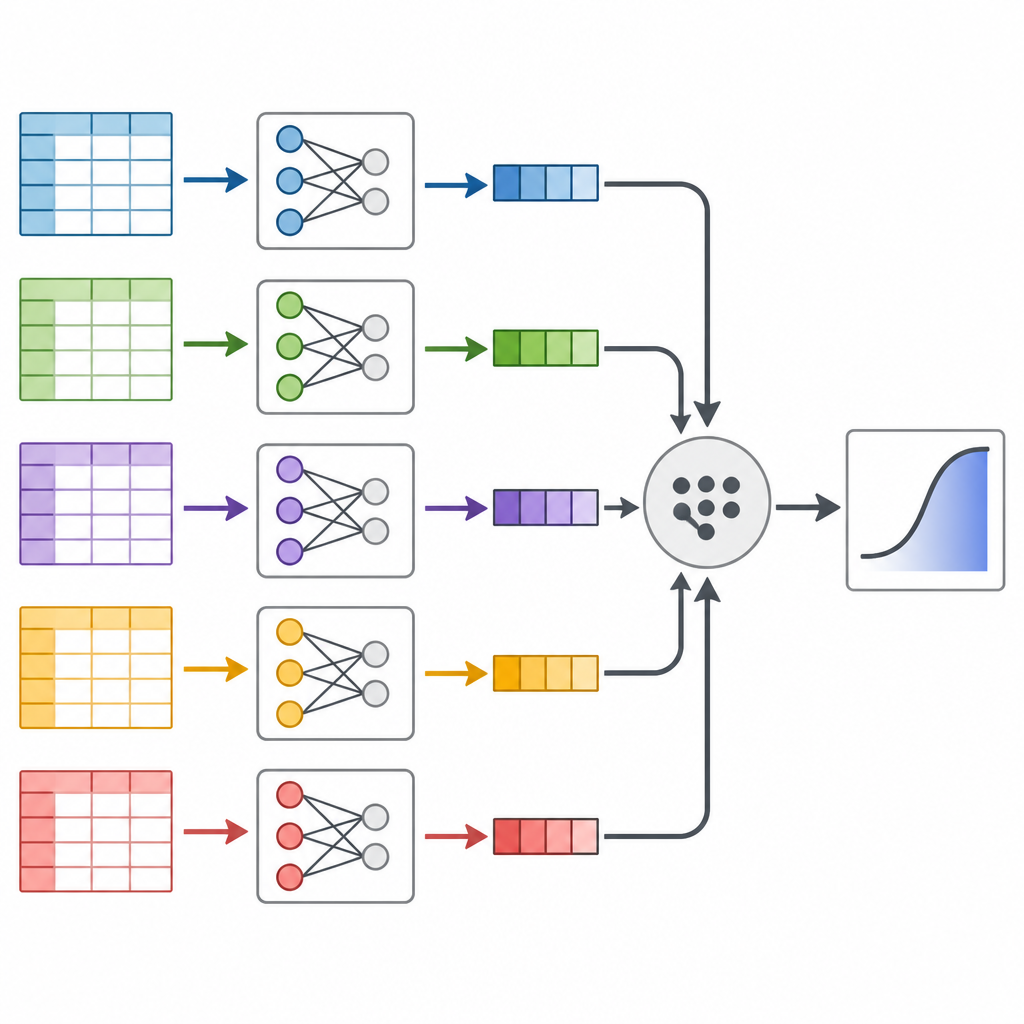
Probar el enfoque con datos reales de estadounidenses
A continuación, los investigadores recurrieron al Behavioral Risk Factor Surveillance System, una encuesta telefónica estadounidense de larga duración que sigue hábitos y condiciones de salud. Extrajeron datos de 2014 a 2024 para adultos de 40 años o más, obteniendo casi 2,5 millones de personas e información sobre 16 factores como edad, peso corporal, ejercicio, tabaquismo, ingresos y autopercepción de la salud. Tras limpiar cuidadosamente los datos y mezclar el orden de las personas, dividieron la encuesta en docenas de fragmentos manejables, ajustaron el modelo de riesgo de diabetes en cada fragmento y recombinaron los resultados. También ejecutaron dos métodos estándar que usan todos los datos a la vez, para comprobar si las respuestas coincidían.
Qué dicen los datos sobre el riesgo de diabetes
Los resultados del dividir y recombinar coincidieron casi perfectamente con los análisis tradicionales, confirmando que el atajo no distorsiona la ciencia. El modelo recuperó patrones bien conocidos: las probabilidades de diabetes aumentan bruscamente con la edad y son varias veces mayores entre las personas con obesidad que entre las de peso normal. Las personas que reportan salud general regular o mala, que no hacen ejercicio o que fuman actualmente también mostraron mayores probabilidades. En contraste, mayores ingresos y más años de escolaridad se asociaron con menores probabilidades, incluso después de controlar por peso y hábitos, lo que subraya el papel de las condiciones sociales. Algunas enfermedades de larga duración en la encuesta mostraron vínculos inversos aparentemente paradójicos con la diabetes, que los autores atribuyen a efectos de supervivencia y a peculiaridades de medición en un estudio transversal en lugar de protección real.
Qué significa esto para las decisiones sanitarias cotidianas
Para el público general, el mensaje principal es que las encuestas nacionales de salud existentes pueden convertirse en calculadoras fiables de riesgo de diabetes usando ordenadores convencionales. La estrategia de dividir y recombinar mantiene la calidad estadística de los métodos tradicionales y, al mismo tiempo, hace factible trabajar con millones de registros. Esto facilita que agencias de salud pública e investigadores con recursos limitados identifiquen a quienes tienen mayor riesgo, orienten programas de prevención hacia adultos mayores con obesidad y menores ingresos, y actualicen estos conocimientos a medida que se añaden nuevos años de encuestas. El método no cura la diabetes, pero ayuda a la sociedad a usar mejor sus datos para prevenir y manejar la enfermedad.
Cita: Nayem, M.M.H., Biswas, S.C. Divide and recombine approaches for fitting logistic regression to large-scale health surveillance data: application to diabetes risk prediction in BRFSS. Sci Rep 16, 15980 (2026). https://doi.org/10.1038/s41598-026-46927-7
Palabras clave: riesgo de diabetes, big data en salud, regresión logística, encuesta BRFSS, dividir y recombinar