Clear Sky Science · ru
Подходы «разделяй и объединяй» для подгонки логистической регрессии к масштабным данным эпиднадзора: применение для прогнозирования риска диабета в BRFSS
Почему крупные опросы здоровья важны для понимания диабета
С каждым годом диабет затрагивает всё больше людей, однако системы здравоохранения часто не успевают вовремя выявлять тех, кто находится в зоне риска, чтобы предотвратить серьёзные осложнения. Госорганы собирают огромные обследования здоровья с участием миллионов взрослых, но такие гигантские файлы тяжело анализировать на обычных компьютерах. В этом исследовании показано, как хитрый приём разбиения и последующего объединения данных может превратить эти громоздкие опросы в практичные инструменты для прогнозирования того, кто с наибольшей вероятностью разовьёт диабет, без необходимости в суперкомпьютере.

Разделение больших данных на куски по размеру укуса
Авторы сосредоточились на методе, называемом «разделяй и объединяй», который рассматривает массивный набор данных как хлебный батон, который можно нарезать и затем снова собрать. Вместо того чтобы запускать одну огромную статистическую модель на всех данных сразу, они разбивают данные на более мелкие части, по отдельности подгоняют одну и ту же модель предсказания к каждой части, а затем объединяют результаты принципиальным образом. Ключевая идея в том, что каждая «долька» данных несёт информацию о том, как факторы риска связаны с диабетом, и эти части можно слить, используя математические веса, отражающие, сколько информации содержит каждая часть.
Проверка метода в жёстком испытании
Чтобы проверить надёжность стратегии разбиения и слияния, команда сначала провела большой компьютерный эксперимент с искусственными данными. Они многократно создавали по пять миллионов виртуальных пациентов, у каждого были несколько факторов риска и известная «истинная» связь с диабетом. Затем они сравнили традиционный анализ полного набора данных с подходом «разделяй и объединяй» при различном числе фрагментов. Результаты оказались впечатляющими: метод разбиения дал почти идентичные ответы, ошибки отличались лишь в четвёртом знаке после запятой, при этом время вычислений сократилось примерно вдвое, а потребление памяти уменьшилось до почти девяноста процентов.
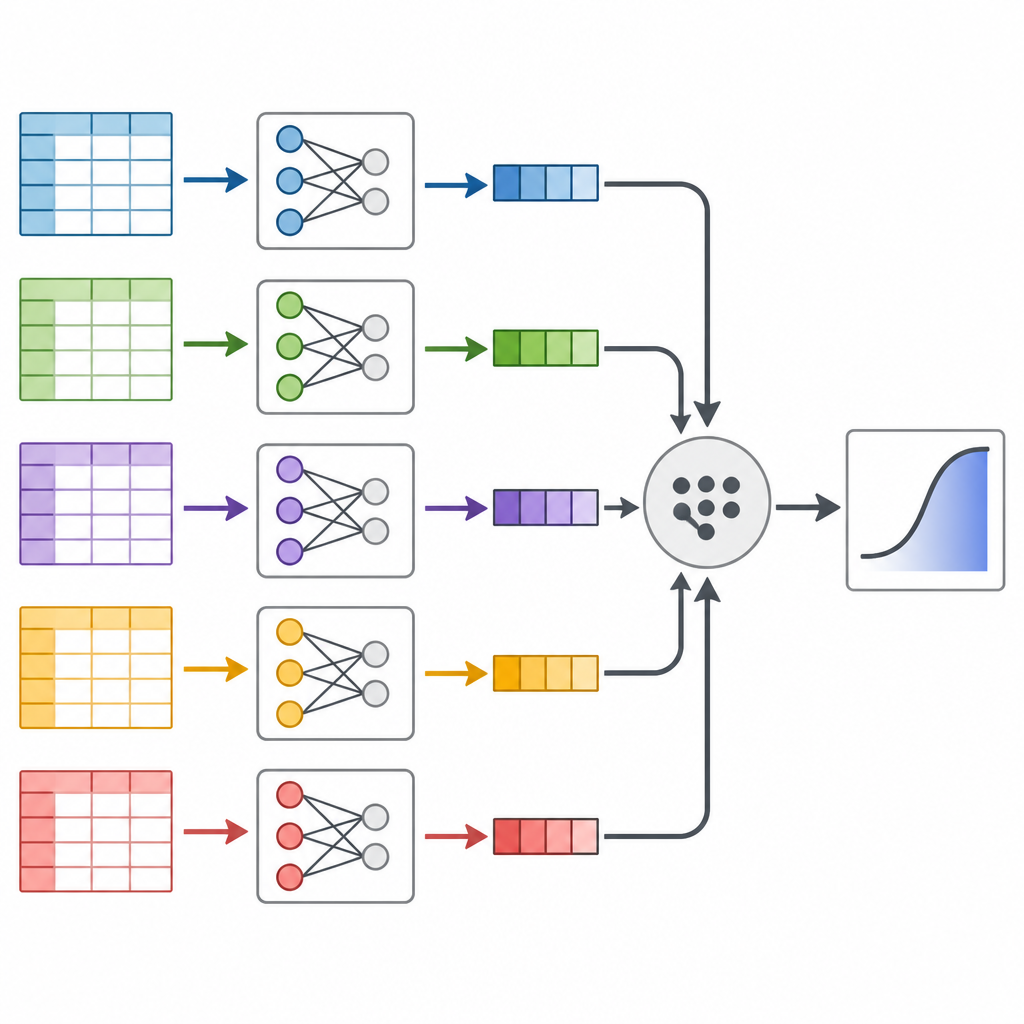
Тестирование подхода на реальных данных американцев
Далее исследователи обратились к Behavioral Risk Factor Surveillance System — долгосрочному телефонному опросу в США, отслеживающему привычки и состояния здоровья. Они взяли данные за 2014–2024 годы для взрослых в возрасте 40 лет и старше, в результате получив почти 2,5 миллиона человек и информацию по 16 факторам, таким как возраст, масса тела, физическая активность, курение, доход и самооценка здоровья. После тщательной очистки данных и перемешивания порядка записей они разделили опрос на десятки управляемых фрагментов, подогнали модель риска диабета к каждому фрагменту и объединили результаты. Они также выполнили два стандартных метода, использующих все данные сразу, чтобы сравнить совпадение ответов.
Что данные говорят о риске диабета
Результаты «разделяй и объединяй» почти полностью совпали с традиционными анализами, подтвердив, что этот приём не искажает научные выводы. Модель восстановила известные закономерности: вероятность диабета резко растёт с возрастом и в несколько раз выше у людей с ожирением по сравнению с людьми нормальной массы тела. У лиц, которые оценивают своё здоровье как «удовлетворительное» или «плохое», которые не занимаются физической активностью или которые курят в настоящее время, также были повышенные шансы. Напротив, более высокий доход и больше лет обучения были связаны с более низким риском даже после учёта веса и привычек, что указывает на роль социальных факторов. Некоторые хронические заболевания в опросе показали загадочные обратные связи с диабетом — авторы объясняют это эффектами выживания и погрешностями измерений в срезе данных, а не истинной защитой.
Что это означает для повседневных решений в здравоохранении
Для неспециалистов главный вывод в том, что существующие национальные обследования здоровья можно превратить в надёжные калькуляторы риска диабета, используя обычные компьютеры. Стратегия «разделяй и объединяй» сохраняет статистическое качество традиционных методов, делая возможной работу с миллионами записей. Это упрощает задачу для органов общественного здравоохранения и исследователей с ограниченными ресурсами — отслеживать наиболее уязвимые группы, нацеливать программы профилактики на пожилых людей с ожирением и низким доходом и обновлять эти выводы по мере поступления новых лет опросов. Метод не лечит диабет, но помогает обществу разумнее использовать имеющиеся данные для профилактики и управления заболеванием.
Цитирование: Nayem, M.M.H., Biswas, S.C. Divide and recombine approaches for fitting logistic regression to large-scale health surveillance data: application to diabetes risk prediction in BRFSS. Sci Rep 16, 15980 (2026). https://doi.org/10.1038/s41598-026-46927-7
Ключевые слова: риск диабета, большие данные в здравоохранении, логистическая регрессия, опрос BRFSS, разделяй и объединяй