Clear Sky Science · pl
Metody dzielenia i scalania danych do dopasowywania regresji logistycznej w dużych zbiorach nadzorczych zdrowia: zastosowanie do prognozowania ryzyka cukrzycy w BRFSS
Dlaczego duże badania zdrowotne są ważne dla cukrzycy
Cukrzyca dotyka coraz więcej osób każdego roku, tymczasem systemy opieki zdrowotnej mają trudności ze wczesnym wykrywaniem osób zagrożonych, by zapobiec poważnym powikłaniom. Rządy gromadzą ogromne ankiety zdrowotne obejmujące miliony dorosłych, ale te olbrzymie zbiory są trudne do analizy na zwykłych komputerach. W badaniu pokazano, jak sprytna metoda dzielenia i scalania danych może przekształcić te nieporęczne ankiety w praktyczne narzędzia do przewidywania, kto ma największe prawdopodobieństwo rozwoju cukrzycy, bez potrzeby korzystania z superkomputera.

Dzielenie wielkich danych na porcje
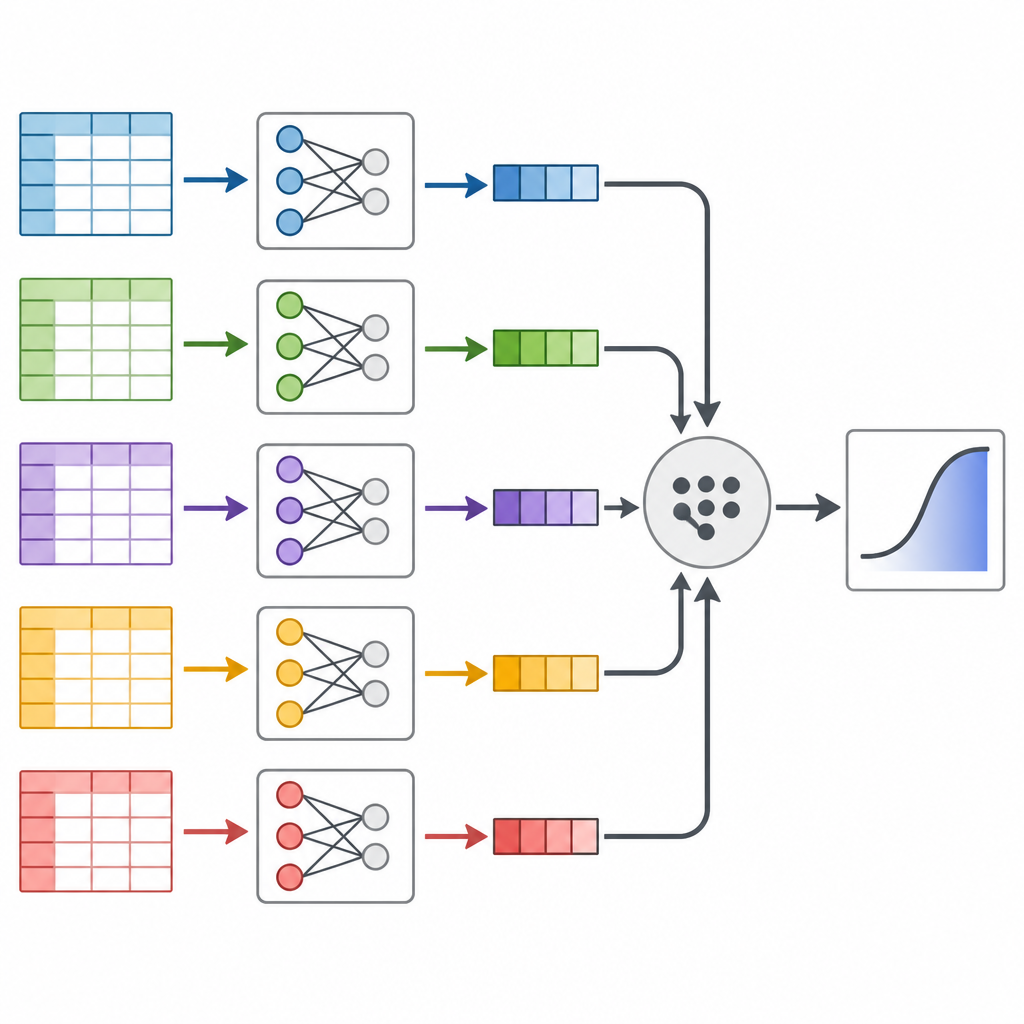
Autorzy skupiają się na technice zwanej dziel i scal, która traktuje masywny zbiór danych jak bochenek chleba, który można pokroić i potem złożyć z powrotem. Zamiast uruchamiać jeden olbrzymi model statystyczny na całych danych jednocześnie, dzielą dane na mniejsze kawałki, dopasowują ten sam model predykcyjny oddzielnie dla każdego kawałka, a następnie łączą wyniki w sposób zasadny metodycznie. Kluczowa idea jest taka, że każda porcja danych niesie informację o tym, jak czynniki ryzyka wiążą się z cukrzycą, a te kawałki można połączyć za pomocą matematycznych wag odzwierciedlających, ile informacji zawiera każda część.
Wystawienie metody na trudną próbę
Aby sprawdzić, czy ta strategia dzielenia i scalania jest wiarygodna, zespół najpierw przeprowadził duży eksperyment komputerowy na danych syntetycznych. Stworzyli po pięć milionów wirtualnych pacjentów wielokrotnie, z kilkoma czynnikami ryzyka i znaną „prawdziwą” zależnością od cukrzycy. Następnie porównali tradycyjną analizę całego zbioru z podejściem dziel i scal przy różnej liczbie fragmentów. Wyniki były uderzające: metoda dzielenia dała niemal identyczne odpowiedzi, z błędami różniącymi się jedynie w czwartej cyfrze po przecinku, przy jednoczesnym skróceniu czasu obliczeń o około połowę i zmniejszeniu zapotrzebowania na pamięć nawet do prawie dziewięćdziesięciu procent.
Test metody na prawdziwych Amerykanach
Następnie badacze sięgnęli do Behavioral Risk Factor Surveillance System, długotrwałej amerykańskiej ankiety telefonicznej śledzącej nawyki zdrowotne i choroby. Wyciągnęli dane z lat 2014–2024 dla dorosłych w wieku 40 lat i więcej, uzyskując prawie 2,5 miliona osób oraz informacje o 16 czynnikach, takich jak wiek, masa ciała, aktywność fizyczna, palenie, dochód i samoocena stanu zdrowia. Po starannym oczyszczeniu danych i przetasowaniu kolejności osób podzielili ankietę na kilkadziesiąt poręcznych kawałków, dopasowali model ryzyka cukrzycy do każdego kawałka i scalili wyniki. Przeprowadzili też dwie standardowe metody wykorzystujące cały zbiór na raz, by sprawdzić zgodność wyników.
Co dane mówią o ryzyku cukrzycy
Wyniki metody dziel i scal pokrywały się niemal idealnie z analizami tradycyjnymi, potwierdzając, że skrót nie zniekształca wniosków naukowych. Model odtworzył dobrze znane wzorce: szanse wystąpienia cukrzycy rosną gwałtownie z wiekiem i są wielokrotnie wyższe u osób z otyłością niż u osób o prawidłowej masie ciała. Wyższe ryzyko stwierdzono też u osób deklarujących słaby lub przeciętny stan zdrowia, u osób niećwiczących oraz aktualnych palaczy. W przeciwieństwie do tego wyższy dochód i więcej lat edukacji wiązały się z niższym ryzykiem, nawet po uwzględnieniu masy ciała i nawyków, co wskazuje na rolę warunków społecznych. Niektóre choroby przewlekłe wykazywały w ankiecie zaskakujące odwrotne powiązania z cukrzycą, które autorzy tłumaczą efektami przeżywalności i artefaktami pomiarowymi w jednorazowym badaniu przekrojowym, a nie rzeczywistą ochroną.
Co to oznacza dla codziennych decyzji zdrowotnych
Dla osób niebędących specjalistami główny przekaz jest taki, że istniejące krajowe ankiety zdrowotne można przekształcić w wiarygodne kalkulatory ryzyka cukrzycy przy użyciu zwykłych komputerów. Strategia dziel i scal zachowuje jakość statystyczną metod tradycyjnych, a jednocześnie umożliwia pracę z milionami rekordów. Ułatwia to agencjom zdrowia publicznego i badaczom o ograniczonych zasobach śledzenie osób najbardziej zagrożonych, kierowanie programów zapobiegania do starszych dorosłych z otyłością i niższymi dochodami oraz aktualizowanie tych wniosków wraz z kolejnymi latami ankiet. Metoda nie leczy cukrzycy, ale pomaga społeczeństwu mądrzej wykorzystywać dane do jej zapobiegania i zarządzania chorobą.
Cytowanie: Nayem, M.M.H., Biswas, S.C. Divide and recombine approaches for fitting logistic regression to large-scale health surveillance data: application to diabetes risk prediction in BRFSS. Sci Rep 16, 15980 (2026). https://doi.org/10.1038/s41598-026-46927-7
Słowa kluczowe: ryzyko cukrzycy, duże dane zdrowotne, regresja logistyczna, ankieta BRFSS, dzielenie i scalanie