Clear Sky Science · en
Divide and recombine approaches for fitting logistic regression to large-scale health surveillance data: application to diabetes risk prediction in BRFSS
Why big health surveys matter for diabetes
Diabetes is affecting more people every year, yet health systems struggle to spot who is at risk early enough to prevent serious problems. Governments collect huge health surveys with millions of adults, but these gigantic files are difficult to analyze on ordinary computers. This study shows how a clever way of splitting and recombining data can turn those unwieldy surveys into practical tools for predicting who is most likely to develop diabetes, without needing a supercomputer.

Breaking big data into bite-sized chunks
The authors focus on a technique called divide and recombine, which treats a massive dataset like a loaf of bread that can be sliced and then reassembled. Instead of running one enormous statistical model on all the data at once, they cut the data into smaller pieces, fit the same prediction model separately to each piece, and then combine the results in a principled way. The key idea is that each slice of data carries information about how risk factors relate to diabetes, and those pieces can be merged using mathematical weights that reflect how much information each slice contains.
Putting the method to a tough test
To see whether this split-and-merge strategy is trustworthy, the team first ran a large computer experiment with made-up data. They created five million virtual patients again and again, each with several risk factors and a known "true" relationship to diabetes. They then compared traditional analysis of the full dataset with the divide and recombine approach under different numbers of slices. The results were striking: the split method produced nearly identical answers, with errors differing only in the fourth decimal place, while cutting computing time by about half and slashing memory needs by up to almost ninety percent.
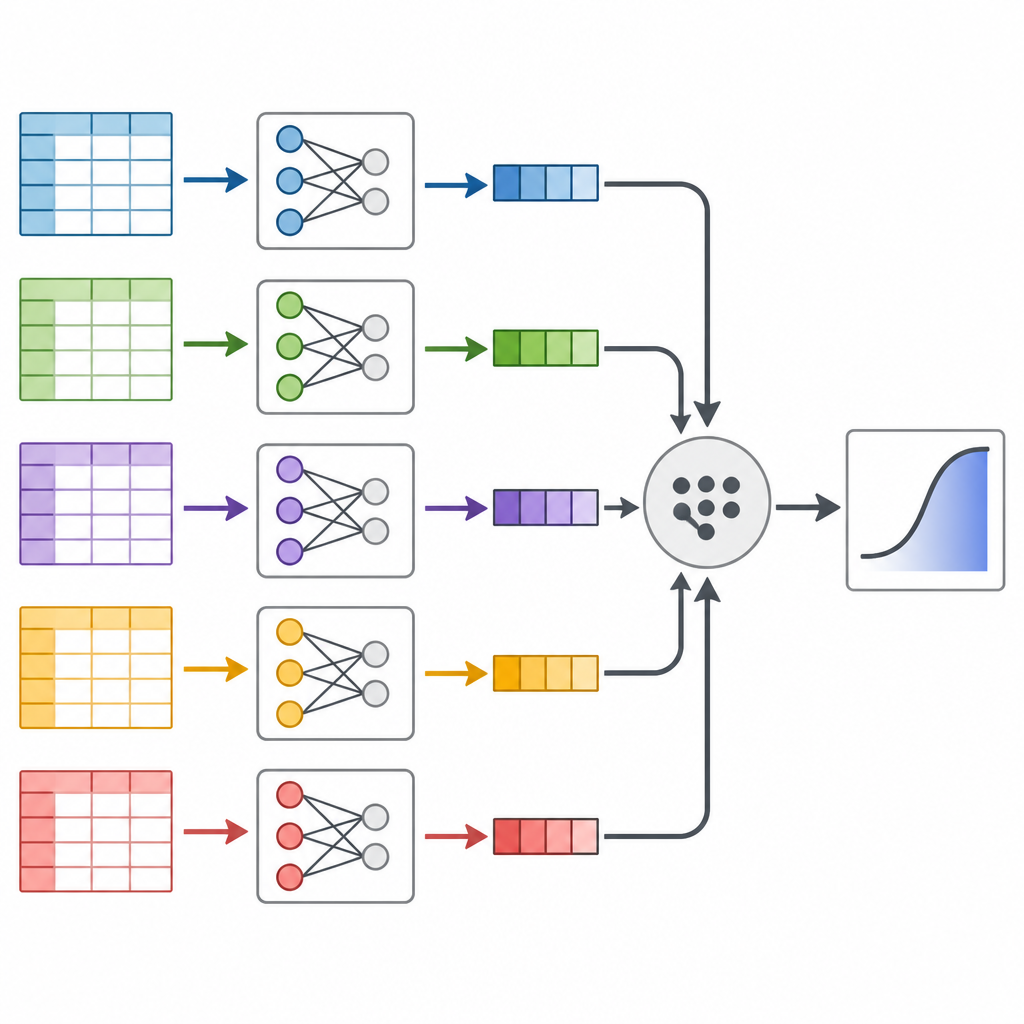
Testing the approach on real Americans
Next, the researchers turned to the Behavioral Risk Factor Surveillance System, a long-running U.S. telephone survey that tracks health habits and conditions. They pulled data from 2014 to 2024 for adults aged 40 and over, ending up with almost 2.5 million people and information on 16 factors such as age, body weight, exercise, smoking, income, and self-rated health. After carefully cleaning the data and shuffling the order of people, they split the survey into dozens of manageable chunks, fit the diabetes risk model on each chunk, and recombined the results. They also ran two standard methods that use the full data at once, to see whether the answers matched.
What the data say about diabetes risk
The divide and recombine results lined up almost perfectly with the traditional analyses, confirming that the shortcut does not distort the science. The model recovered well-known patterns: the odds of diabetes rise steeply with age, and are several times higher among people with obesity than those of normal weight. People who report fair or poor general health, who do not exercise, or who smoke currently also had higher odds. In contrast, higher income and more years of schooling were linked to lower odds, even after taking weight and habits into account, pointing to the role of social conditions. Some long-term diseases in the survey showed puzzling inverse links with diabetes, which the authors attribute to survival and measurement quirks in a one-time snapshot study rather than true protection.
What this means for everyday health decisions
For non-specialists, the main message is that existing national health surveys can be turned into reliable diabetes risk calculators using regular computers. The divide and recombine strategy keeps the statistical quality of traditional methods while making it feasible to work with millions of records. That makes it easier for public health agencies and researchers with limited resources to track who is most at risk, target prevention programs to older adults with obesity and lower income, and update these insights as new survey years are added. The method does not cure diabetes, but it helps society use its data more wisely to prevent and manage the disease.
Citation: Nayem, M.M.H., Biswas, S.C. Divide and recombine approaches for fitting logistic regression to large-scale health surveillance data: application to diabetes risk prediction in BRFSS. Sci Rep 16, 15980 (2026). https://doi.org/10.1038/s41598-026-46927-7
Keywords: diabetes risk, health big data, logistic regression, BRFSS survey, divide and recombine