Clear Sky Science · sv
Framtidsmedveten blodsockerveckning med kunskapsdestillering och transformer-baserade sekvens-till-sekvens-modeller
Varför blodsockerprognoser spelar roll
För personer med typ 1-diabetes kan blodsockret stiga och sjunka snabbt efter måltider, träning, stress eller insulindoser. Att kunna se inte bara vad blodsockret är nu, utan vart det är på väg under nästa timme eller två, kan hjälpa dem att undvika farliga låga och höga nivåer, justera insulin i tid och planera dagliga aktiviteter med större trygghet. Denna studie undersöker ett nytt sätt att lära datorer att förutsäga framtida blodsocker genom att hemligt använda information om kommande måltider och insulin under träning, samtidigt som modellen fortfarande fungerar i verkliga situationer där framtiden är okänd.
En smartare blick framåt för diabetesvård
Dagens kontinuerliga glukosmätare levererar avläsningar varannan till var femte minut, och moderna algoritmer använder redan dessa data för att förutsäga nära framtida blodsockernivåer. De flesta befintliga verktyg tittar dock bara bakåt: de analyserar tidigare glukosvärden och ibland andra signaler som hjärtfrekvens eller rörelse. De ignorerar vanligtvis den kraftfulla påverkan av framtida händelser som nästa måltid eller insulintillförsel, eftersom sådana händelser inte är pålitligt kända i förväg. Som ett resultat brister prognoser ofta just när sockernivåerna svänger mest, till exempel strax efter att man ätit eller korrigerat ett högt värde. Författarna menar att för att verkligen stödja vardagliga diabetesbeslut måste prognoser på något sätt lära sig om dessa framtida störningar utan att förvänta sig att de finns tillgängliga vid körning.
Träna med extra ledtrådar, testa utan dem
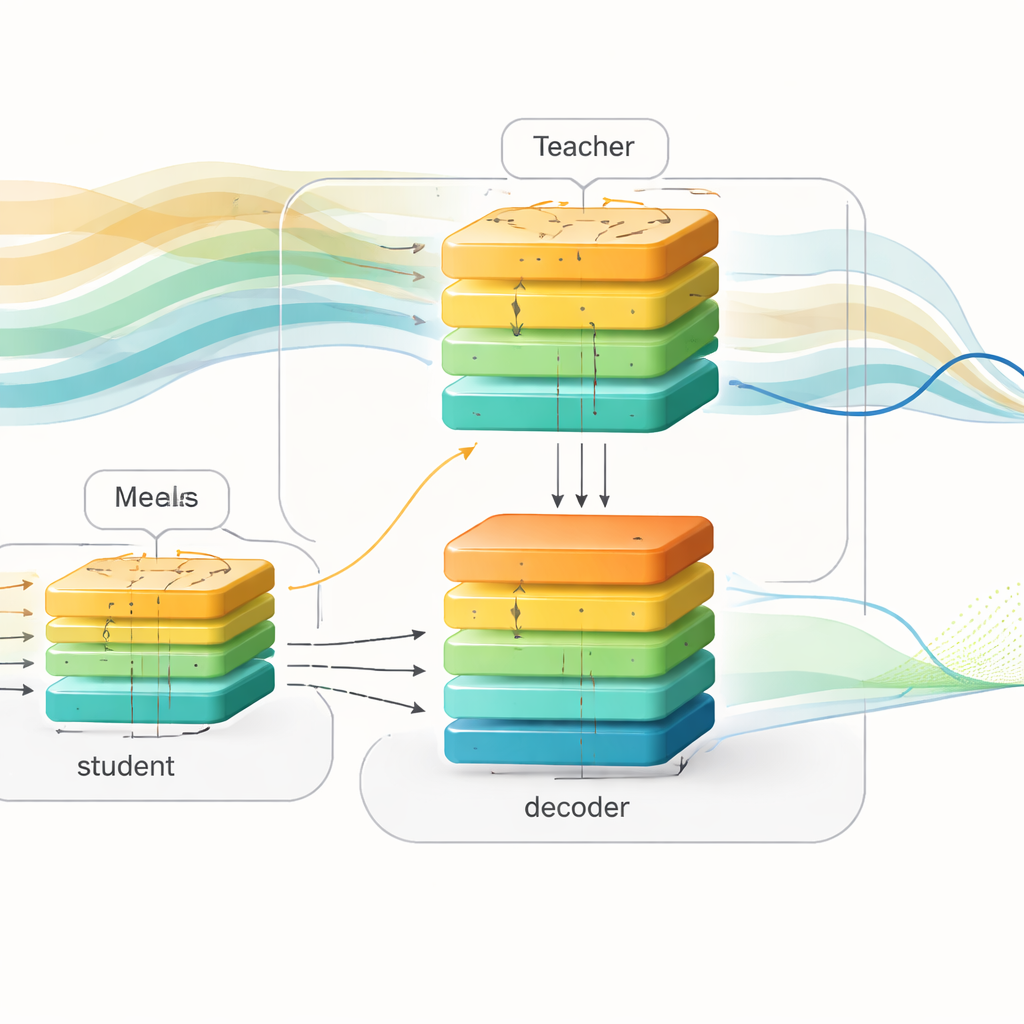
Forskarna introducerar ett "framtidsmedvetet" inlärningsramverk som separerar träning från användning. Under träningen använder de rika register från två stora datamängder med personer som har typ 1-diabetes, vilka innehåller glukosavläsningar, insulindoser och måltidsinformation. De bygger en kraftfull "lärare"-modell baserad på en transformer, en djupinlärningsarkitektur känd för att hantera långa sekvenser. Denna lärare ser både tidigare glukosdata och kommande måltider och insulin under de följande två timmarna, och den lär sig hur dessa framtida händelser formar blodsockermönster. Parallellt designar de en "student"-modell med liknande in-/ut-struktur, men studenten ser bara tidigare data, precis som en verklig enhet skulle göra.
Att överföra kunskap från lärare till student
För att överbrygga klyftan mellan dessa två världsbilder använder författarna en teknik kallad kunskapsdestillering. Istället för att enbart matcha lärarens slutliga prognoser ber de också studenten efterlikna lärarens interna representation av hur glukos förväntas utvecklas. Både lärare och student matar sina interna signaler in i samma avkodningsnätverk som omvandlar abstrakta mönster till framtida glukoskurvor. Under träningen skjuts studenten på tre sätt samtidigt: den måste förutsäga det verkliga framtida blodsockret, hålla sina interna mönster nära lärarens och approximera lärarens egna prognoser. Med tiden lär sig studenten att indirekt "tänka" på kommande måltider och insulin, genom att sluta sig till sannolika framtida svängningar utifrån formen på den senaste historiken ensam.
Testning på verkliga diabetesdata
Teamet utvärderar sitt tillvägagångssätt på två oberoende dataset: OhioT1DM, som följer 12 vuxna under åtta veckor i vardagslivet, och AZT1D, som spårar 25 personer som använder automatiserade insulintillförselssystem. Efter noggrann hantering av saknade sensoraläsningar jämför de sin studentmodell med flera starka neurala nätverksbaser, inklusive LSTM, bidirektionell LSTM, konvolutions–rekurrenta nätverk och transformermodeller som inte använder framtidsmedveten träning. Över prognoshorizonter från 30 till 120 minuter minskar den nya metoden konsekvent vanliga felmått såsom root mean squared error och mean absolute error. Klinisk tillförlitlighet undersöks genom ett Clarke error grid, som graderar prognoser efter hur mycket skada de kan orsaka i beslutsfattande; mer än 90 % av denna modells prognoser hamnar i de zoner som anses säkra eller acceptabla för att vägleda terapi.
Vad detta kan innebära för vardagen
Kort sagt visar studien att låta en modell öva med en förhandstitt på framtiden och sedan destillera den erfarenheten till en smalare version som fungerar utan framtidskunskap, kan göra blodsockerprognoser mer precisa—särskilt 60 till 120 minuter framåt. Dessa långsiktigare prognoser är de som hjälper människor avgöra om de ska äta ett mellanmål nu för att undvika en framtida låg nivå, eller justera en insulindos i tid för att förhindra ett annalkande högt värde. Även om arbetet fortfarande är forskning och antar relativt regelbundna rutiner, pekar det mot smartare beslutsstödsverktyg och slutna loop-system för insulin som bättre förutser kommande glukossvängningar, även när den enda information som finns är vad som redan har hänt.
Citering: Sun, X., Li, H. & Yu, X. Future-aware blood glucose forecasting using knowledge distillation with transformer-based sequence-to-sequence models. Sci Rep 16, 11404 (2026). https://doi.org/10.1038/s41598-026-41787-7
Nyckelord: blodsockerprognos, typ 1-diabetes, deep learning, transformermodeller, kunskapsdestillering