Clear Sky Science · es
Predicción de glucemia con conciencia del futuro mediante destilación de conocimiento y modelos secuencia-a-secuencia basados en transformadores
Por qué importa predecir el nivel de azúcar en sangre
Para las personas con diabetes tipo 1, el nivel de azúcar en sangre puede subir y bajar rápidamente tras las comidas, el ejercicio, el estrés o la administración de insulina. Poder ver no solo cuál es su glucemia ahora, sino hacia dónde se dirige en la próxima hora o dos, podría ayudarles a evitar hipoglucemias e hiperglucemias peligrosas, ajustar la insulina a tiempo y planificar las actividades diarias con más seguridad. Este estudio explora una forma nueva de enseñar a los ordenadores a pronosticar la glucemia futura usando, durante el entrenamiento, información sobre comidas e insulina próximas de forma encubierta, mientras que en el uso real el futuro sigue sin estar disponible.
Una mirada más inteligente hacia el futuro para el cuidado de la diabetes
Los monitores continuos de glucosa actuales ofrecen lecturas cada pocos minutos y los algoritmos modernos ya usan esos datos para prever la glucemia a corto plazo. Sin embargo, la mayoría de las herramientas existentes sólo miran hacia atrás: analizan lecturas pasadas de glucosa y, a veces, otras señales como la frecuencia cardiaca o el movimiento. Suelen ignorar el potente impacto de eventos futuros como la próxima comida o un bolo de insulina, porque esos eventos no son fiables a la hora de conocerlos por adelantado. Como resultado, las predicciones a menudo fallan precisamente cuando los niveles de glucosa cambian más rápido, por ejemplo justo después de comer o al corregir una cifra alta. Los autores sostienen que, para apoyar verdaderamente las decisiones diarias en diabetes, los pronósticos deben aprender de alguna forma sobre esas perturbaciones futuras sin esperar disponer de ellas en tiempo de ejecución.
Enseñar con pistas adicionales y luego evaluar sin ellas
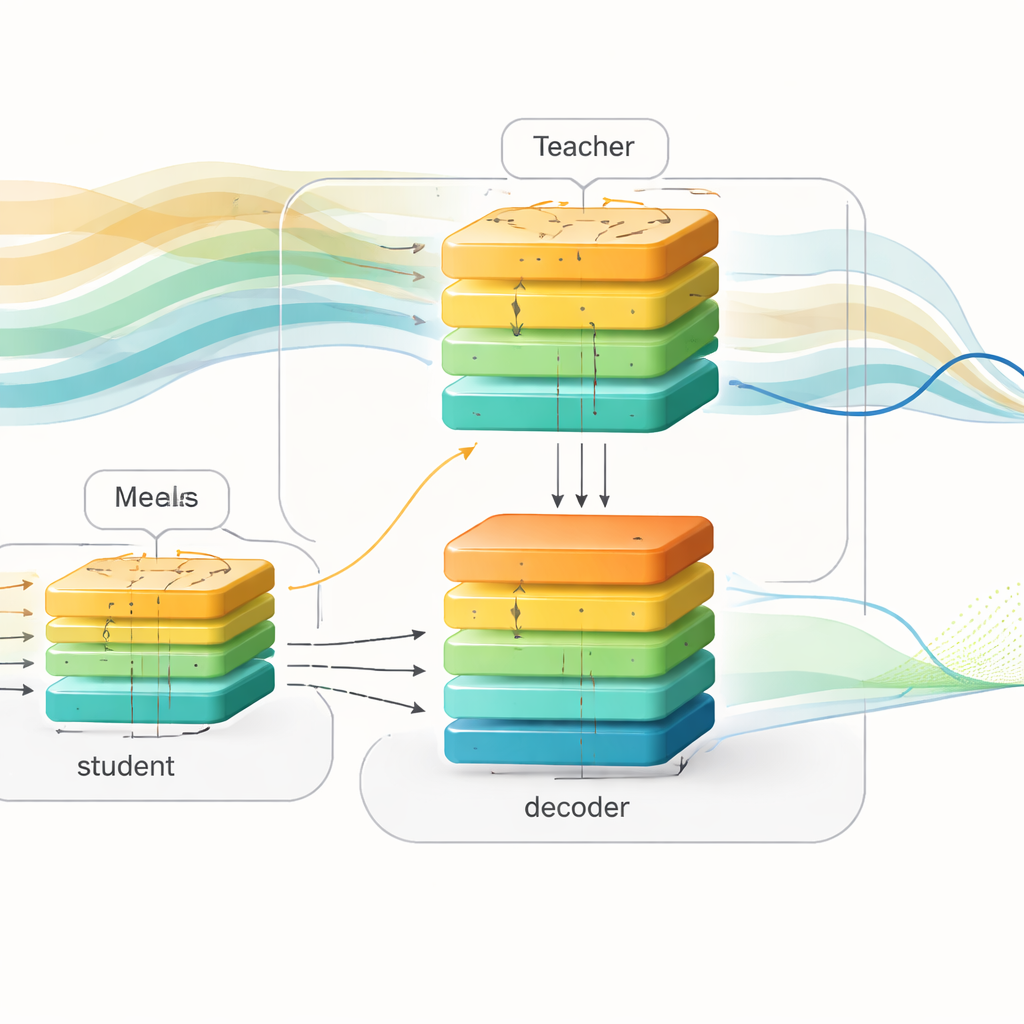
Los investigadores introducen un marco de aprendizaje “con conciencia del futuro” que separa el entrenamiento del despliegue. Durante el entrenamiento usan registros detallados de dos grandes conjuntos de datos de personas con diabetes tipo 1, que incluyen lecturas de glucosa, dosis de insulina e información de las comidas. Construyen un potente modelo “profesor” basado en un transformador, una arquitectura de aprendizaje profundo conocida por manejar secuencias largas. Este profesor ve tanto los datos pasados de glucosa como las comidas e insulina previstas para las próximas dos horas, y aprende cómo esos eventos futuros modelan los patrones de glucosa. En paralelo, diseñan un modelo “estudiante” con una estructura de entrada–salida similar, pero el estudiante sólo ve datos pasados, tal como lo haría un dispositivo en el mundo real.
Transferir conocimiento del profesor al estudiante
Para salvar la brecha entre estas dos visiones del mundo, los autores emplean una técnica llamada destilación de conocimiento. En lugar de limitarse a igualar las predicciones finales del profesor, también piden al estudiante que imite la representación interna del profesor sobre cómo se espera que evolucione la glucosa. Tanto el profesor como el estudiante alimentan sus señales internas a la misma red decodificadora que convierte patrones abstractos en curvas de glucosa futuras. Durante el entrenamiento, el estudiante recibe tres estímulos a la vez: debe predecir la glucemia futura real, debe mantener sus patrones internos cercanos a los del profesor y debe aproximar las propias predicciones del profesor. Con el tiempo, el estudiante aprende a “pensar” en las comidas e insulina próximas de forma indirecta, inferiendo posibles oscilaciones futuras a partir de las formas de la historia reciente únicamente.
Evaluación con datos reales de diabetes
El equipo evalúa su enfoque en dos conjuntos de datos independientes: OhioT1DM, que sigue a 12 adultos durante ocho semanas de vida diaria, y AZT1D, que registra a 25 personas que usan sistemas de administración automática de insulina. Tras un manejo cuidadoso de lecturas faltantes del sensor, comparan su modelo estudiante con varias líneas base neuronales sólidas, incluidas LSTM, LSTM bidireccionales, redes convolucionales–recurrentes y modelos transformer que no usan entrenamiento con conciencia del futuro. En horizontes de predicción de 30 a 120 minutos, el nuevo método reduce de forma consistente medidas de error comunes como el error cuadrático medio y el error absoluto medio. La fiabilidad clínica se examina mediante una cuadrícula de error de Clarke, que clasifica las predicciones según el daño que podrían causar en la toma de decisiones; más del 90 % de los pronósticos de este modelo caen en zonas consideradas seguras o aceptables para guiar la terapia.
Qué podría significar esto para la vida cotidiana
En términos sencillos, el estudio muestra que dejar que un modelo practique con una vista previa del futuro y luego destilar esa experiencia en una versión más ligera que funciona sin conocimiento futuro puede mejorar la precisión de las predicciones de glucemia, especialmente a 60–120 minutos vista. Estos pronósticos de mayor alcance son los que ayudan a las personas a decidir si tomar un tentempié ahora para evitar una hipoglucemia más tarde, o ajustar una dosis de insulina a tiempo para prevenir una hiperglucemia inminente. Aunque el trabajo sigue siendo de investigación y asume rutinas relativamente regulares, apunta hacia herramientas de apoyo a la decisión y sistemas de circuito cerrado de insulina más inteligentes que anticipen mejor las oscilaciones de glucosa venideras, incluso cuando la única información disponible es lo que ya ha sucedido.
Cita: Sun, X., Li, H. & Yu, X. Future-aware blood glucose forecasting using knowledge distillation with transformer-based sequence-to-sequence models. Sci Rep 16, 11404 (2026). https://doi.org/10.1038/s41598-026-41787-7
Palabras clave: predicción de glucosa en sangre, diabetes tipo 1, aprendizaje profundo, modelos transformer, destilación de conocimiento