Clear Sky Science · fr
Prévision consciente du futur de la glycémie par distillation de connaissances avec des modèles séquence-à-séquence basés sur des transformers
Pourquoi prédire la glycémie est important
Pour les personnes vivant avec un diabète de type 1, la glycémie peut monter et descendre rapidement après un repas, un exercice, du stress ou une injection d’insuline. Pouvoir voir non seulement leur glycémie actuelle, mais aussi sa trajectoire dans l’heure ou les deux heures à venir, peut les aider à éviter des hypoglycémies ou hyperglycémies dangereuses, ajuster l’insuline à temps et planifier leurs activités quotidiennes avec davantage de confiance. Cette étude explore une nouvelle manière d’apprendre aux ordinateurs à prévoir la glycémie future en utilisant, de façon cachée pendant l’entraînement, des informations sur les repas et l’insuline à venir, tout en restant applicable dans le monde réel où le futur est inconnu.
Une anticipation plus intelligente pour la prise en charge du diabète
Les moniteurs continus de glucose actuels fournissent des mesures toutes les quelques minutes, et des algorithmes modernes exploitent déjà ces données pour prévoir la glycémie à court terme. Cependant, la plupart des outils existants ne regardent que vers l’arrière : ils analysent les lectures passées de glucose et parfois d’autres signaux comme la fréquence cardiaque ou le mouvement. Ils ignorent en général l’impact puissant des événements futurs tels que le prochain repas ou la prochaine dose d’insuline, car ces événements ne sont pas connus de manière fiable à l’avance. En conséquence, les prédictions échouent souvent précisément lorsque la glycémie varie le plus, par exemple juste après avoir mangé ou après une correction d’hyperglycémie. Les auteurs soutiennent que, pour vraiment aider les décisions quotidiennes liées au diabète, les prévisions doivent apprendre d’une manière ou d’une autre ces perturbations futures sans s’attendre à les avoir en temps réel.
Apprendre avec des indices supplémentaires, puis être testé sans eux
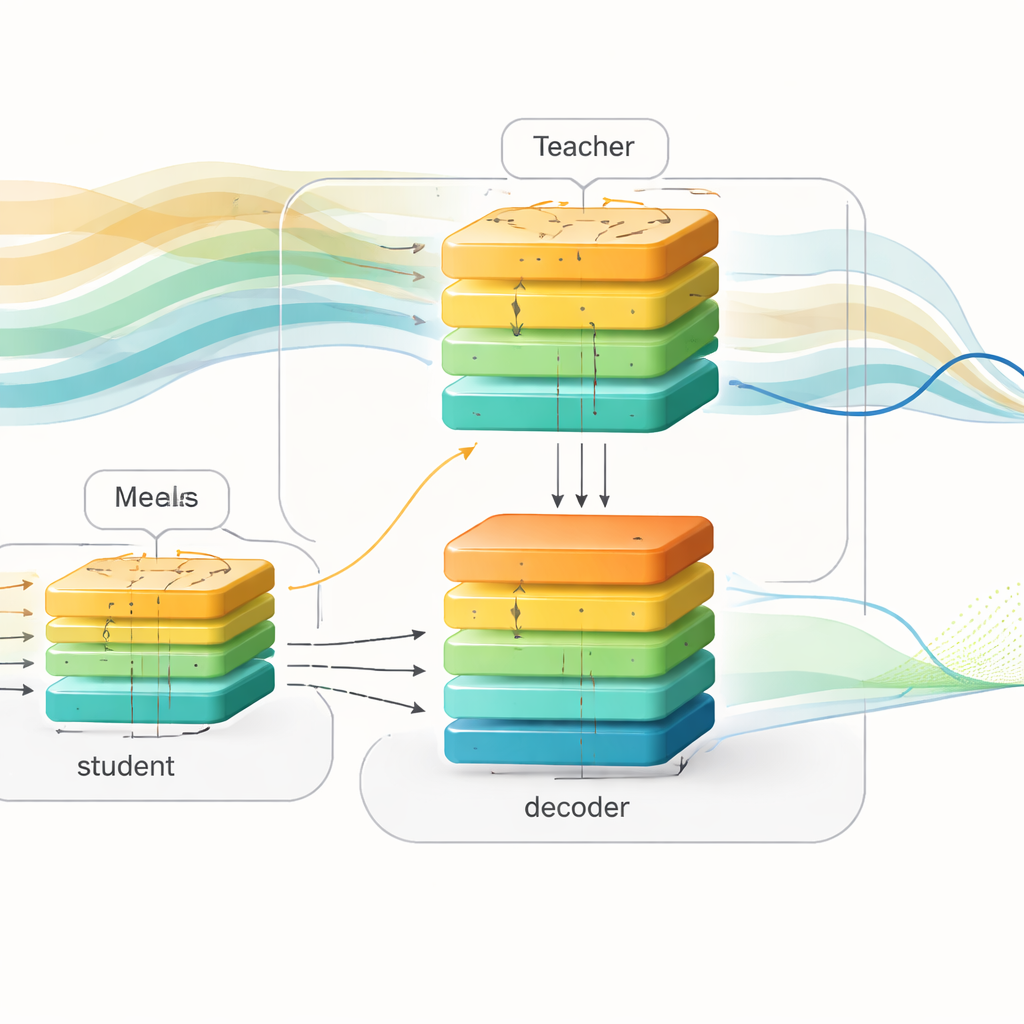
Les chercheurs présentent un cadre d’apprentissage « conscient du futur » qui sépare l’entraînement du déploiement. Pendant l’entraînement, ils utilisent des enregistrements riches provenant de deux grands jeux de données de personnes atteintes de diabète de type 1, qui incluent les lectures de glucose, les doses d’insuline et les informations sur les repas. Ils construisent un modèle puissant « enseignant » basé sur un transformer, une architecture d’apprentissage profond réputée pour gérer de longues séquences. Cet enseignant voit à la fois les données de glucose passées et les repas et insulines à venir sur les deux heures suivantes, et il apprend comment ces événements futurs façonnent les variations de glycémie. En parallèle, ils conçoivent un modèle « étudiant » avec une structure entrée–sortie similaire, mais l’étudiant ne voit que les données passées, exactement comme le ferait un dispositif en conditions réelles.
Transmettre le savoir de l’enseignant à l’étudiant
Pour combler le fossé entre ces deux visions du monde, les auteurs utilisent une technique appelée distillation de connaissances. Plutôt que de seulement reproduire les prédictions finales de l’enseignant, ils demandent aussi à l’étudiant d’imiter la représentation interne de l’enseignant sur l’évolution attendue de la glycémie. L’enseignant et l’étudiant alimentent leurs signaux internes dans le même réseau décodeur qui transforme des motifs abstraits en courbes de glycémie futures. Pendant l’entraînement, l’étudiant est orienté de trois manières simultanément : il doit prédire la glycémie future réelle, maintenir ses motifs internes proches de ceux de l’enseignant et approximer les prévisions de l’enseignant. Avec le temps, l’étudiant apprend à « penser » indirectement aux repas et à l’insuline à venir, en déduisant les variations futures probables à partir des formes de l’historique récent seulement.
Test sur des données réelles de diabète
L’équipe évalue leur approche sur deux jeux de données indépendants : OhioT1DM, qui suit 12 adultes sur huit semaines de vie quotidienne, et AZT1D, qui suit 25 personnes utilisant des systèmes de délivrance d’insuline automatisés. Après un traitement soigné des lectures capteurs manquantes, ils comparent leur modèle étudiant à plusieurs solides modèles neuronaux de référence, incluant LSTM, LSTM bidirectionnel, réseaux convolution–récurrents et des transformers qui n’utilisent pas l’entraînement conscient du futur. Sur des horizons de prédiction allant de 30 à 120 minutes, la nouvelle méthode réduit systématiquement des mesures d’erreur courantes telles que l’erreur quadratique moyenne et l’erreur absolue moyenne. La fiabilité clinique est examinée via une grille d’erreur de Clarke, qui classe les prédictions selon le risque qu’elles peuvent causer dans la prise de décision ; plus de 90 % des prévisions de ce modèle se situent dans les zones considérées comme sûres ou acceptables pour guider la thérapie.
Ce que cela pourrait signifier pour la vie quotidienne
En termes simples, l’étude montre que laisser un modèle s’entraîner avec un aperçu du futur, puis distiller cette expérience dans une version plus légère qui fonctionne sans connaissance du futur, peut rendre les prévisions de glycémie plus précises — en particulier à 60 et 120 minutes d’avance. Ce sont ces prévisions à plus long terme qui aident les personnes à décider si elles doivent prendre une collation maintenant pour éviter une hypoglycémie plus tard, ou ajuster une dose d’insuline à temps pour prévenir une hyperglycémie imminente. Bien que le travail reste de la recherche et suppose des routines relativement régulières, il ouvre la voie à des outils d’aide à la décision et à des systèmes d’injection d’insuline en boucle fermée plus intelligents, mieux à même d’anticiper les variations de glycémie à venir, même lorsque la seule information disponible est ce qui s’est déjà passé.
Citation: Sun, X., Li, H. & Yu, X. Future-aware blood glucose forecasting using knowledge distillation with transformer-based sequence-to-sequence models. Sci Rep 16, 11404 (2026). https://doi.org/10.1038/s41598-026-41787-7
Mots-clés: prévision de la glycémie, diabète de type 1, apprentissage profond, modèles transformer, distillation de connaissances