Clear Sky Science · de
Zukunftsbewusste Vorhersage des Blutzuckers mithilfe von Knowledge Distillation und transformer‑basierten Sequenz‑zu‑Sequenz‑Modellen
Warum die Vorhersage des Blutzuckers wichtig ist
Für Menschen mit Typ‑1‑Diabetes kann der Blutzucker nach Mahlzeiten, Bewegung, Stress oder Insulingaben schnell steigen und fallen. Nicht nur zu wissen, wie hoch der Blutzucker gerade ist, sondern zu erkennen, wohin er in der nächsten Stunde oder zwei tendiert, kann helfen, gefährliche Unter‑ oder Überzuckerungen zu vermeiden, Insulin rechtzeitig anzupassen und den Alltag besser zu planen. Diese Studie untersucht einen neuen Weg, Computern beizubringen, den zukünftigen Blutzucker vorherzusagen, indem sie beim Training heimlich Informationen über anstehende Mahlzeiten und Insulin nutzt, während das Modell bei der Anwendung in der realen Welt weiterhin ohne Kenntnis der Zukunft auskommen muss.
Ein klügerer Blick nach vorn für die Diabetesversorgung
Moderne kontinuierliche Glukosemessgeräte liefern Messwerte alle paar Minuten, und aktuelle Algorithmen nutzen diese Daten bereits zur Vorhersage des nahen Blutzuckerverlaufs. Die meisten bestehenden Werkzeuge blicken jedoch nur rückwärts: Sie analysieren vergangene Glukosewerte und manchmal weitere Signale wie Herzfrequenz oder Bewegung. Häufig ignorieren sie den starken Einfluss zukünftiger Ereignisse wie der nächsten Mahlzeit oder einer Insulinbolusgabe, weil diese Ereignisse im Vorhinein nicht verlässlich bekannt sind. Dadurch versagen Vorhersagen oft gerade dann, wenn sich die Werte am schnellsten ändern, etwa unmittelbar nach dem Essen oder beim Korrigieren hoher Werte. Die Autorinnen und Autoren argumentieren, dass Vorhersagen, um den Alltag wirklich zu unterstützen, irgendwie über diese zukünftigen Störgrößen lernen müssen, ohne vorauszusetzen, dass sie zur Laufzeit verfügbar sind.
Mit zusätzlichen Hinweisen trainieren, dann ohne testen
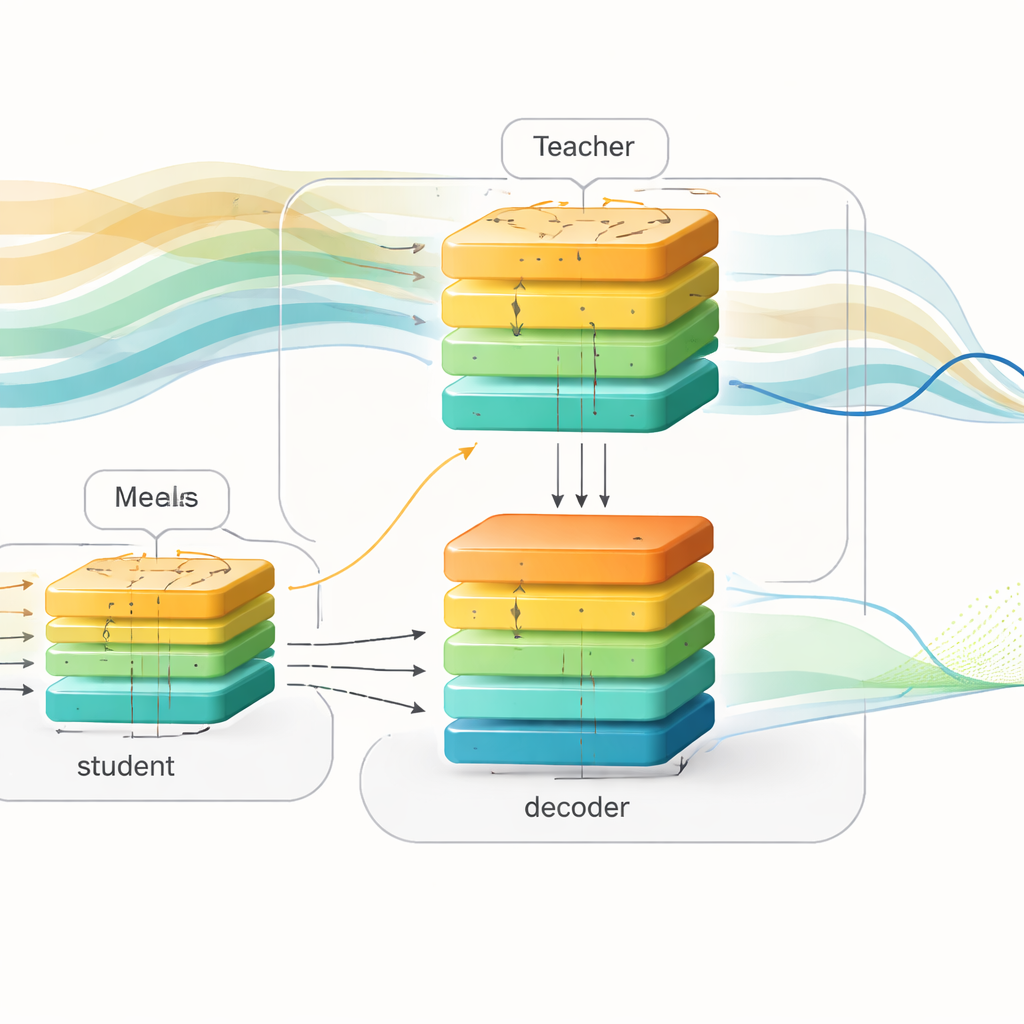
Die Forschenden stellen einen „zukunftsbewussten“ Lernrahmen vor, der Training und Einsatz trennt. Beim Training verwenden sie umfangreiche Aufzeichnungen aus zwei großen Datensätzen von Menschen mit Typ‑1‑Diabetes, die Glukosewerte, Insulindosen und Mahlzeiteninformationen enthalten. Sie bauen ein leistungsfähiges „Lehrer“-Modell auf Basis eines Transformers, einer Deep‑Learning‑Architektur, die für das Verarbeiten langer Sequenzen bekannt ist. Dieser Lehrer sieht sowohl vergangene Glukosedaten als auch anstehende Mahlzeiten und Insulin der nächsten zwei Stunden und lernt, wie diese zukünftigen Ereignisse die Blutzuckermuster formen. Parallel dazu entwerfen sie ein „Schüler“-Modell mit ähnlicher Ein‑Ausgabe‑Struktur, das jedoch nur vergangene Daten sieht — genau wie ein Gerät in der realen Welt.
Wissen vom Lehrer an den Schüler weitergeben
Um die Lücke zwischen diesen beiden Sichtweisen zu überbrücken, nutzen die Autorinnen und Autoren eine Technik namens Knowledge Distillation. Anstatt sich nur an den finalen Vorhersagen des Lehrers zu orientieren, fordern sie den Schüler zusätzlich auf, die interne Repräsentation des Lehrers nachzuahmen, also wie erwartet wird, dass sich der Glukoseverlauf entwickelt. Sowohl Lehrer als auch Schüler speisen ihre internen Signale in dasselbe Decoder‑Netzwerk, das abstrakte Muster in künftige Blutzuckerkurven übersetzt. Beim Training wird der Schüler auf drei Arten gleichzeitig gelenkt: Er muss den tatsächlichen zukünftigen Blutzucker vorhersagen, seine internen Muster nahe beim Lehrer halten und die eigenen Prognosen des Lehrers annähern. Mit der Zeit lernt der Schüler, indirekt über anstehende Mahlzeiten und Insulin „nachzudenken“ und wahrscheinliche zukünftige Schwankungen allein aus der Form der jüngsten Historie abzuleiten.
Test auf realen Diabetes‑Daten
Das Team bewertet seinen Ansatz anhand zweier unabhängiger Datensätze: OhioT1DM, das 12 Erwachsene über acht Wochen Alltagsleben verfolgt, und AZT1D, das 25 Personen mit automatisierten Insulinabgabesystemen beobachtet. Nach sorgfältiger Behandlung fehlender Sensormesswerte vergleichen sie ihr Schüler‑Modell mit mehreren starken neuronalen Basislinien, darunter LSTM, bidirektionales LSTM, konvolutional‑rekurrente Netze und Transformer‑Modelle, die kein zukunftsbewusstes Training verwenden. Über Vorhersagehorizonte von 30 bis 120 Minuten reduziert die neue Methode konstant gebräuchliche Fehlermaße wie Root Mean Squared Error und Mean Absolute Error. Die klinische Zuverlässigkeit wird mit einem Clarke‑Fehlerdiagramm geprüft, das Vorhersagen danach bewertet, wie schädlich sie für Entscheidungen sein könnten; mehr als 90 % der Vorhersagen dieses Modells liegen in den Bereichen, die als sicher oder akzeptabel für die Therapieanleitung gelten.
Was das für den Alltag bedeuten könnte
Einfach gesagt zeigt die Studie, dass es die Vorhersagegenauigkeit des Blutzuckers verbessern kann, wenn ein Modell zunächst mit einer Vorschau auf die Zukunft übt und diese Erfahrung dann in eine schlankere Version überträgt, die ohne Zukunftsinformationen funktioniert — insbesondere für Horizonte von 60 bis 120 Minuten. Solche längerfristigen Vorhersagen helfen Menschen zu entscheiden, ob sie jetzt einen Snack essen sollten, um späterem Unterzucker vorzubeugen, oder eine Insulindosis rechtzeitig anpassen müssen, um einen drohenden Hochwert zu verhindern. Obwohl die Arbeit noch Forschungscharakter hat und relativ regelmäßige Routinen voraussetzt, weist sie auf intelligentere Entscheidungsunterstützungs‑Tools und geschlossene Regelkreissysteme hin, die bevorstehende Glukoseschwankungen besser antizipieren, selbst wenn nur Informationen über Vergangenes verfügbar sind.
Zitation: Sun, X., Li, H. & Yu, X. Future-aware blood glucose forecasting using knowledge distillation with transformer-based sequence-to-sequence models. Sci Rep 16, 11404 (2026). https://doi.org/10.1038/s41598-026-41787-7
Schlüsselwörter: Blutzuckervorhersage, Typ‑1‑Diabetes, Deep Learning, Transformer‑Modelle, Knowledge Distillation