Clear Sky Science · en
Future-aware blood glucose forecasting using knowledge distillation with transformer-based sequence-to-sequence models
Why predicting blood sugar matters
For people living with type 1 diabetes, blood sugar can rise and fall quickly after meals, exercise, stress, or insulin dosing. Being able to see not just what their blood sugar is now, but where it is heading in the next hour or two, could help them avoid dangerous lows and highs, adjust insulin in time, and plan daily activities with more confidence. This study explores a new way to teach computers to forecast future blood sugar by secretly using information about upcoming meals and insulin during training, while still working in the real world where the future is unknown.
A smarter look ahead for diabetes care
Today’s continuous glucose monitors stream readings every few minutes, and modern algorithms already use these data to predict near-future blood sugar. Most existing tools, however, only look backward: they analyze past glucose readings and sometimes other signals such as heart rate or movement. They usually ignore the powerful impact of future events like the next meal or insulin bolus, because those events are not reliably known in advance. As a result, predictions often break down exactly when sugar levels swing the fastest, such as right after eating or correcting a high value. The authors argue that to truly support everyday diabetes decisions, forecasts must somehow learn about these future disturbances without expecting them to be available at run time.
Teaching with extra clues, then testing without them
The researchers introduce a “future-aware” learning framework that separates training from deployment. During training, they use rich records from two large datasets of people with type 1 diabetes, which include glucose readings, insulin doses, and meal information. They build a powerful “teacher” model based on a transformer, a deep learning architecture known for handling long sequences. This teacher sees both past glucose data and upcoming meals and insulin over the next two hours, and it learns how those future events shape blood sugar patterns. In parallel, they design a “student” model with a similar input–output structure, but the student only ever sees past data, just like a real-world device would.
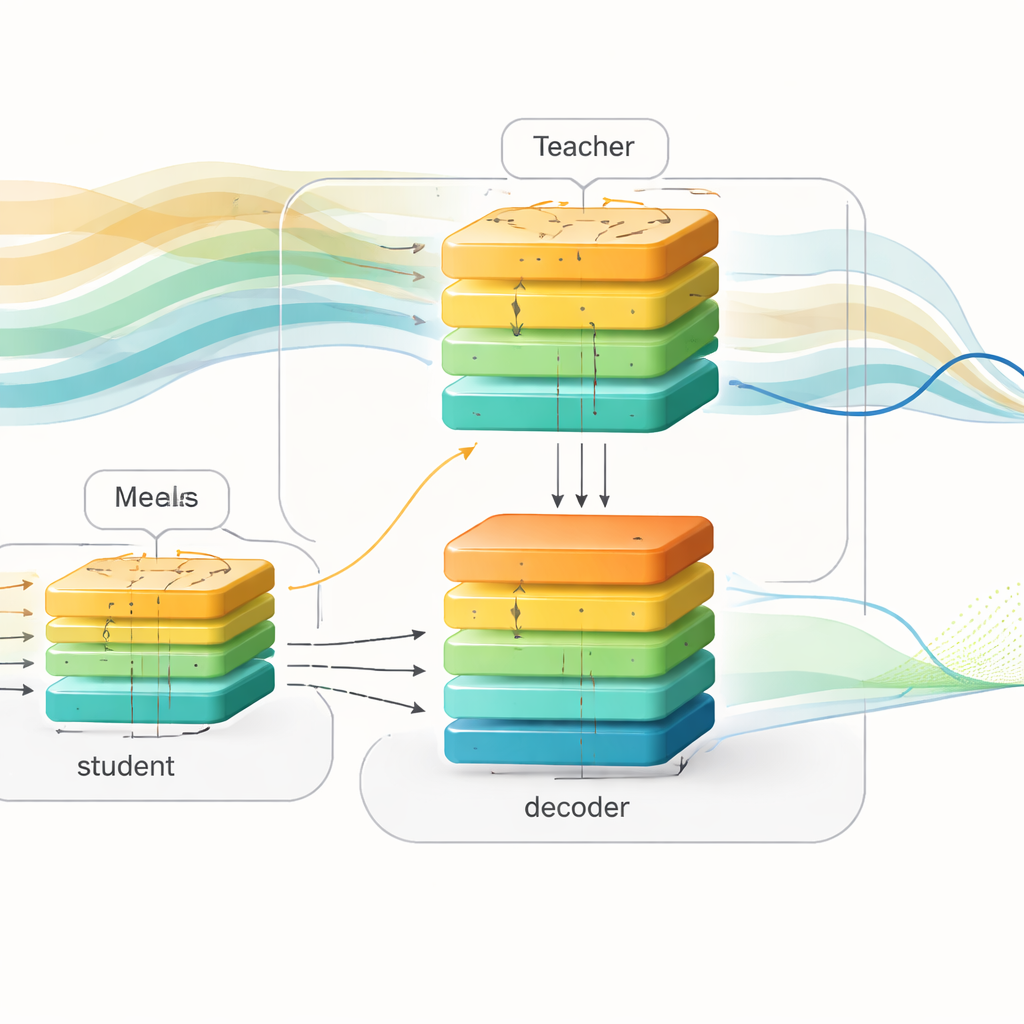
Passing knowledge from teacher to student
To bridge the gap between these two views of the world, the authors use a technique called knowledge distillation. Instead of only matching the teacher’s final predictions, they also ask the student to imitate the teacher’s internal representation of how glucose is expected to evolve. Both teacher and student feed their internal signals into the same decoder network that turns abstract patterns into future glucose curves. During training, the student is nudged in three ways at once: it must predict the true future blood sugar, it must keep its internal patterns close to the teacher’s, and it must approximate the teacher’s own forecasts. Over time, the student learns to “think” about upcoming meals and insulin indirectly, inferring likely future swings from the shapes of recent history alone.
Testing on real-world diabetes data
The team evaluates their approach on two independent datasets: OhioT1DM, which follows 12 adults over eight weeks of daily life, and AZT1D, which tracks 25 people using automated insulin delivery systems. After careful handling of missing sensor readings, they compare their student model with several strong neural network baselines, including LSTM, bidirectional LSTM, convolutional–recurrent networks, and transformer models that do not use future-aware training. Across prediction horizons from 30 to 120 minutes, the new method consistently reduces common error measures such as root mean squared error and mean absolute error. Clinical reliability is examined through a Clarke error grid, which grades predictions by how much harm they might cause in decision-making; more than 90% of this model’s forecasts fall in the zones considered safe or acceptable for guiding therapy.
What this could mean for daily life
In plain terms, the study shows that letting a model practice with a sneak peek at the future, and then distilling that experience into a leaner version that works without future knowledge, can make blood sugar predictions more accurate—especially 60 to 120 minutes ahead. These longer-range forecasts are the ones that help people decide whether to eat a snack now to avoid a low later, or adjust an insulin dose in time to prevent a looming high. While the work is still research and assumes fairly regular routines, it points toward smarter decision-support tools and closed-loop insulin systems that better anticipate upcoming glucose swings, even when the only information available is what has already happened.
Citation: Sun, X., Li, H. & Yu, X. Future-aware blood glucose forecasting using knowledge distillation with transformer-based sequence-to-sequence models. Sci Rep 16, 11404 (2026). https://doi.org/10.1038/s41598-026-41787-7
Keywords: blood glucose prediction, type 1 diabetes, deep learning, transformer models, knowledge distillation