Clear Sky Science · pt
Previsão de glicemia consciente do futuro usando destilação de conhecimento com modelos seqüência-para-seqüência baseados em transformer
Por que prever a glicose é importante
Para pessoas que vivem com diabetes tipo 1, a glicose pode subir e cair rapidamente após refeições, exercícios, estresse ou aplicações de insulina. Ser capaz de ver não apenas qual é a glicose no momento, mas para onde ela tende nas próximas uma ou duas horas, pode ajudá-las a evitar hipoglicemias e hiperglicemias perigosas, ajustar a insulina a tempo e planejar atividades diárias com mais confiança. Este estudo explora uma nova forma de ensinar computadores a prever a glicemia futura ao usar, de forma “secreta”, informações sobre refeições e insulina próximas durante o treinamento, mantendo-se aplicável no mundo real, onde o futuro é desconhecido.
Uma visão mais inteligente para o cuidado do diabetes
Os monitores contínuos de glicose de hoje registram leituras a cada poucos minutos, e algoritmos modernos já usam esses dados para prever a glicemia de curto prazo. No entanto, a maioria das ferramentas existentes olha apenas para trás: analisam leituras passadas de glicose e, às vezes, outros sinais como frequência cardíaca ou movimento. Geralmente ignoram o impacto poderoso de eventos futuros, como a próxima refeição ou um bolus de insulina, porque esses eventos não são conhecidos de forma confiável com antecedência. Como resultado, as previsões muitas vezes falham exatamente quando os níveis de glicose variam mais rápido, por exemplo logo após comer ou ao corrigir um valor alto. Os autores argumentam que, para realmente apoiar decisões cotidianas no diabetes, as previsões precisam, de alguma forma, aprender sobre essas perturbações futuras sem depender de tê-las disponíveis em tempo de execução.
Treinar com pistas extras e testar sem elas
Os pesquisadores introduzem uma estrutura de aprendizado “consciente do futuro” que separa treinamento de implantação. Durante o treinamento, eles usam registros ricos de dois grandes conjuntos de dados de pessoas com diabetes tipo 1, que incluem leituras de glicose, doses de insulina e informações sobre refeições. Constroem um modelo “professor” poderoso baseado em um transformer, uma arquitetura de aprendizado profundo conhecida por lidar com sequências longas. Esse professor vê tanto os dados passados da glicose quanto refeições e insulina previstas para as próximas duas horas, e aprende como esses eventos futuros moldam os padrões de glicemia. Em paralelo, eles projetam um modelo “aluno” com estrutura de entrada–saída semelhante, mas o aluno vê somente dados passados, exatamente como um dispositivo do mundo real faria.
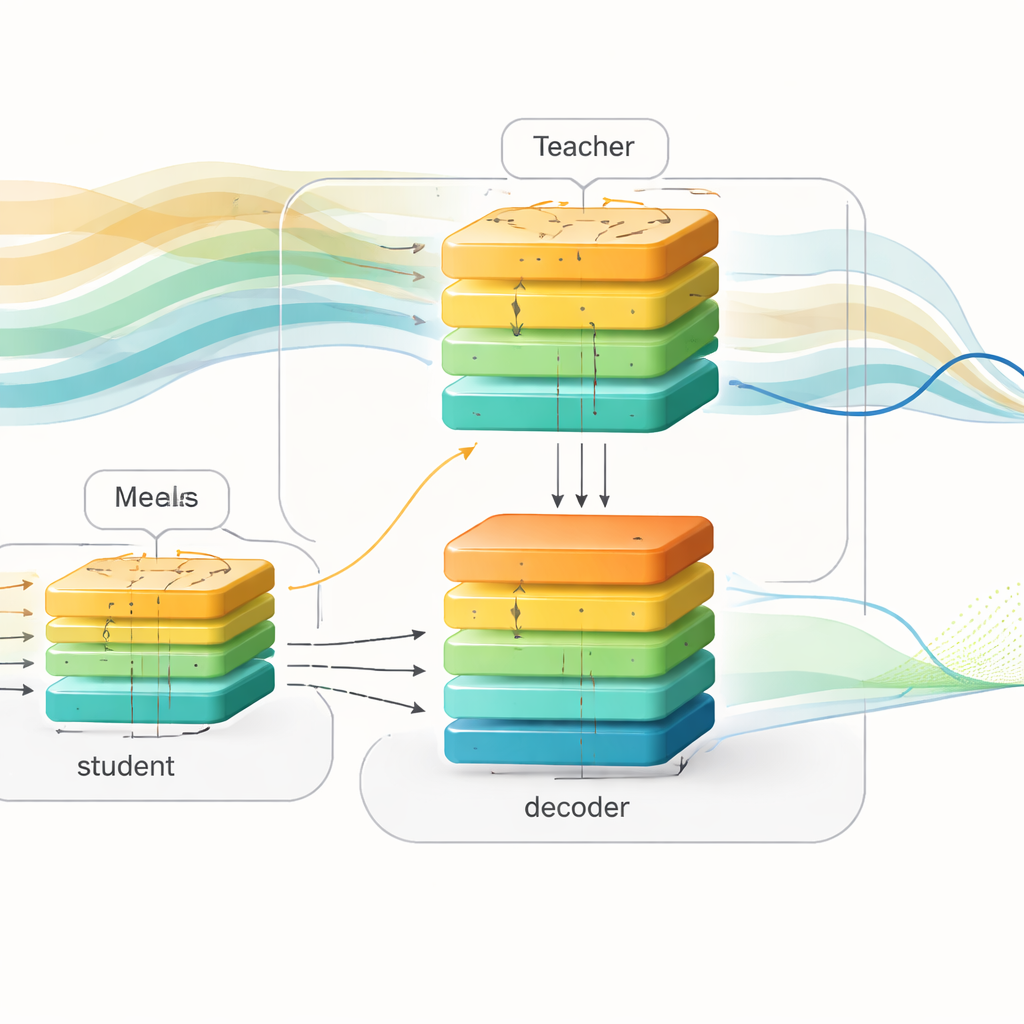
Transferindo conhecimento do professor para o aluno
Para ligar essas duas visões do mundo, os autores usam uma técnica chamada destilação de conhecimento. Em vez de apenas igualar as previsões finais do professor, eles também fazem o aluno imitar a representação interna do professor sobre como a glicose deve evoluir. Tanto o professor quanto o aluno alimentam seus sinais internos na mesma rede decodificadora que transforma padrões abstratos em curvas de glicemia futuras. Durante o treinamento, o aluno é guiado de três maneiras ao mesmo tempo: deve prever a glicemia futura real, manter seus padrões internos próximos aos do professor e aproximar as próprias previsões do professor. Com o tempo, o aluno aprende a “pensar” indiretamente sobre refeições e insulina futuras, inferindo oscilações prováveis a partir das formas do histórico recente sozinho.
Testando com dados reais de diabetes
A equipe avalia sua abordagem em dois conjuntos de dados independentes: OhioT1DM, que acompanha 12 adultos por oito semanas de vida diária, e AZT1D, que segue 25 pessoas usando sistemas de administração automatizada de insulina. Após lidar cuidadosamente com leituras de sensores ausentes, eles comparam seu modelo aluno com várias referências fortes de redes neurais, incluindo LSTM, LSTM bidirecional, redes convolucionais–recorrentes e modelos transformer que não usam treinamento consciente do futuro. Em horizontes de previsão de 30 a 120 minutos, o novo método reduz consistentemente medidas comuns de erro, como erro quadrático médio e erro absoluto médio. A confiabilidade clínica é examinada por meio da grade de erro de Clarke, que classifica previsões pelo potencial de causar dano em decisões clínicas; mais de 90% das previsões deste modelo caem nas zonas consideradas seguras ou aceitáveis para orientar a terapia.
O que isso pode significar para o dia a dia
Em termos simples, o estudo mostra que deixar um modelo treinar com uma espiada no futuro e depois destilar essa experiência em uma versão mais enxuta que funciona sem conhecimento do futuro pode tornar as previsões de glicemia mais precisas — especialmente para 60 a 120 minutos à frente. Essas previsões de longo alcance são as que ajudam as pessoas a decidir se devem comer um lanche agora para evitar uma hipoglicemia mais tarde, ou ajustar uma dose de insulina a tempo de prevenir uma hiperglicemia iminente. Embora o trabalho ainda seja pesquisa e presuma rotinas relativamente regulares, ele aponta para ferramentas de suporte à decisão mais inteligentes e sistemas de insulina em malha fechada que anteveem melhor as flutuações futuras de glicose, mesmo quando a única informação disponível é o que já aconteceu.
Citação: Sun, X., Li, H. & Yu, X. Future-aware blood glucose forecasting using knowledge distillation with transformer-based sequence-to-sequence models. Sci Rep 16, 11404 (2026). https://doi.org/10.1038/s41598-026-41787-7
Palavras-chave: previsão da glicemia, diabetes tipo 1, aprendizado profundo, modelos transformer, destilação de conhecimento