Clear Sky Science · ru
Прогнозирование уровня глюкозы с учётом будущего с помощью дистилляции знаний и трансформерных последовательных моделей
Почему важно прогнозировать уровень сахара
Для людей с сахарным диабетом 1 типа уровень сахара в крови может быстро повышаться и снижаться после приёма пищи, физической активности, стресса или введения инсулина. Возможность видеть не только текущее значение, но и направление движения глюкозы на следующий час или два может помочь избежать опасных падений и подъёмов, вовремя скорректировать инсулин и увереннее планировать повседневные дела. В этом исследовании изучается новый способ научить компьютеры прогнозировать будущую глюкозу, тайно используя информацию о предстоящих приёмах пищи и инсулине во время обучения, при этом сохраняя работоспособность в реальном мире, где будущее неизвестно.
Более умный взгляд вперёд для ухода при диабете
Современные непрерывные мониторы глюкозы передают показания каждые несколько минут, и современные алгоритмы уже используют эти данные для прогнозирования ближайшего будущего. Однако большинство существующих инструментов смотрят назад: они анализируют прошлые показания глюкозы и иногда другие сигналы, такие как частота сердечных сокращений или движение. Обычно они игнорируют сильное влияние будущих событий — следующего приёма пищи или болюса инсулина — потому что такие события заранее неизвестны с надёжностью. В результате прогнозы часто дают сбой именно тогда, когда уровень сахара меняется быстрее всего, например сразу после еды или при коррекции высокого значения. Авторы утверждают, что чтобы действительно поддерживать повседневные решения при диабете, модели должны как-то усваивать информацию о будущих возмущениях, не рассчитывая на её наличие во время работы.
Обучение с дополнительными подсказками, затем тестирование без них
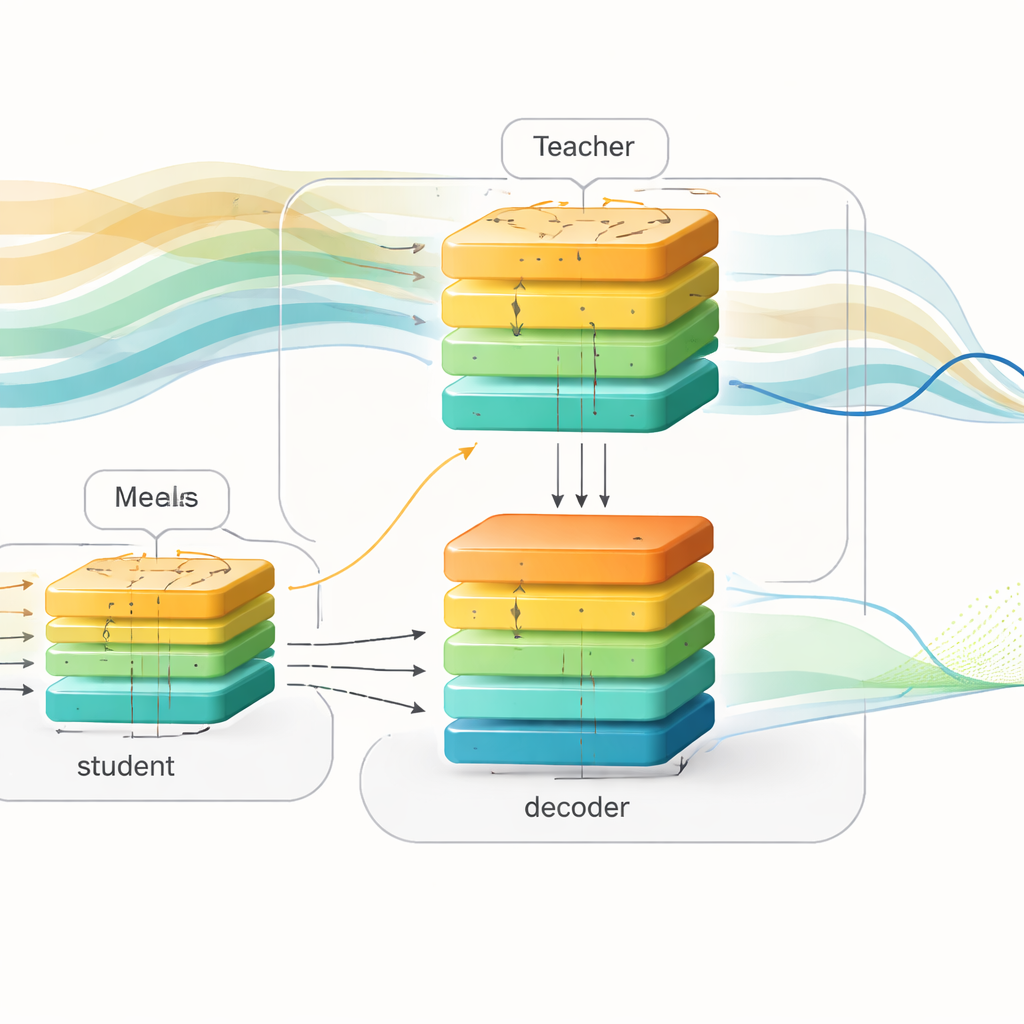
Исследователи предлагают «осознанную о будущем» схему обучения, которая разделяет этапы обучения и развёртывания. Во время обучения они используют подробные записи из двух больших наборов данных людей с диабетом 1 типа, включающих показания глюкозы, дозы инсулина и информацию о приёмах пищи. Они создают мощную «учительскую» модель на базе трансформера — архитектуры глубинного обучения, известной обработкой длинных последовательностей. Этот учитель видит как прошлые данные о глюкозе, так и предстоящие приёмы пищи и инсулин в течение следующих двух часов и учится, как эти будущие события формируют шаблоны глюкозы. Параллельно они проектируют «студенческую» модель с похожей входно-выходной структурой, но студент видит только прошлые данные, так же как и реальное устройство.
Передача знаний от учителя к студенту
Чтобы преодолеть разрыв между двумя представлениями мира, авторы используют технику, называемую дистилляцией знаний. Вместо того чтобы лишь подгонять конечные предсказания учителя, они также просят студента имитировать внутреннее представление учителя о том, как ожидается развитие глюкозы. И учитель, и студент подают свои внутренние сигналы в один и тот же декодер, превращающий абстрактные паттерны в будущие кривые глюкозы. Во время обучения студент корректируется тремя способами одновременно: он должен предсказывать истинное будущее значение глюкозы, держать свои внутренние паттерны близкими к паттернам учителя и аппроксимировать собственные прогнозы учителя. Со временем студент учится «думать» о предстоящих приёмах пищи и инсулине косвенно, выводя вероятные будущие колебания только по форме недавней истории.
Тестирование на реальных данных по диабету
Команда оценивает подход на двух независимых наборах данных: OhioT1DM, который отслеживает 12 взрослых в течение восьми недель повседневной жизни, и AZT1D, где наблюдаются 25 человек, использующих системы автоматической подачи инсулина. После тщательной обработки пропущенных показаний датчиков они сравнивают свою студенческую модель с несколькими сильными нейросетевыми базовыми методами, включая LSTM, двунаправленные LSTM, сверточно-рекуррентные сети и трансформеры без обучения с учётом будущего. На горизонтах прогнозирования от 30 до 120 минут новый метод последовательно снижает распространённые метрики ошибки, такие как среднеквадратичная ошибка и средняя абсолютная ошибка. Клиническую надёжность изучают с помощью сетки ошибок Кларка, которая оценивает прогнозы по тому, какой вред они могут нанести при принятии решений; более 90% прогнозов этой модели попадают в зоны, считающиеся безопасными или допустимыми для руководства терапией.
Что это может значить для повседневной жизни
Проще говоря, исследование показывает: позволив модели потренироваться с подсмотром в будущее, а затем дистиллировать этот опыт в более лёгкую версию, работающую без знания будущего, можно повысить точность прогнозов глюкозы — особенно на горизонтах 60–120 минут. Такие более дальние прогнозы помогают людям решить, стоит ли сейчас съесть перекус, чтобы не допустить гипогликемии позже, или вовремя скорректировать дозу инсулина, чтобы предотвратить надвигающийся подъём. Хотя работа пока остаётся исследованием и предполагает относительно регулярные распорядки, она указывает на направление для более умных инструментов поддержки принятия решений и замкнутых систем доставки инсулина, которые лучше предугадывают предстоящие колебания глюкозы, даже когда доступна только информация о том, что уже произошло.
Цитирование: Sun, X., Li, H. & Yu, X. Future-aware blood glucose forecasting using knowledge distillation with transformer-based sequence-to-sequence models. Sci Rep 16, 11404 (2026). https://doi.org/10.1038/s41598-026-41787-7
Ключевые слова: прогнозирование уровня глюкозы в крови, сахарный диабет 1 типа, глубокое обучение, модели-трансформеры, дистилляция знаний