Clear Sky Science · nl
Toekomstbewuste voorspelling van bloedglucose met kennisdistillatie en transformer-gebaseerde sequence-to-sequence-modellen
Waarom het voorspellen van bloedsuiker belangrijk is
Voor mensen met type 1 diabetes kan de bloedsuiker snel stijgen en dalen na maaltijden, inspanning, stress of insuline toediening. Niet alleen weten wat de bloedsuiker nu is, maar ook waar die naartoe gaat in het komende uur of twee, kan helpen om gevaarlijke hypoglykemieën en hyperglykemieën te voorkomen, insuline op tijd aan te passen en dagelijkse activiteiten met meer vertrouwen te plannen. Deze studie onderzoekt een nieuwe manier om computers te leren toekomstige bloedsuiker te voorspellen door tijdens de training stilletjes informatie over aankomende maaltijden en insuline te gebruiken, terwijl het model in de praktijk gewoon moet werken zonder kennis van de toekomst.
Een slimmer vooruitzicht voor diabeteszorg
Moderne continue glucosesensoren geven elke paar minuten metingen, en bestaande algoritmen gebruiken deze gegevens al om de nabije toekomst te voorspellen. De meeste huidige hulpmiddelen kijken echter alleen terug: ze analyseren eerdere glucosemetingen en soms andere signalen zoals hartslag of beweging. Ze negeren doorgaans de sterke invloed van toekomstige gebeurtenissen zoals de volgende maaltijd of een insulinebolus, omdat die gebeurtenissen niet betrouwbaar vooraf bekend zijn. Daardoor falen voorspellingen vaak precies wanneer de suiker het snelst schommelt, bijvoorbeeld direct na eten of na correctie van een hoge waarde. De auteurs betogen dat forecasts om echt dagelijkse beslissingen te ondersteunen, op de een of andere manier over deze toekomstige verstoringen moeten leren zonder te verwachten dat die informatie tijdens gebruik beschikbaar is.
Leren met extra aanwijzingen, testen zonder
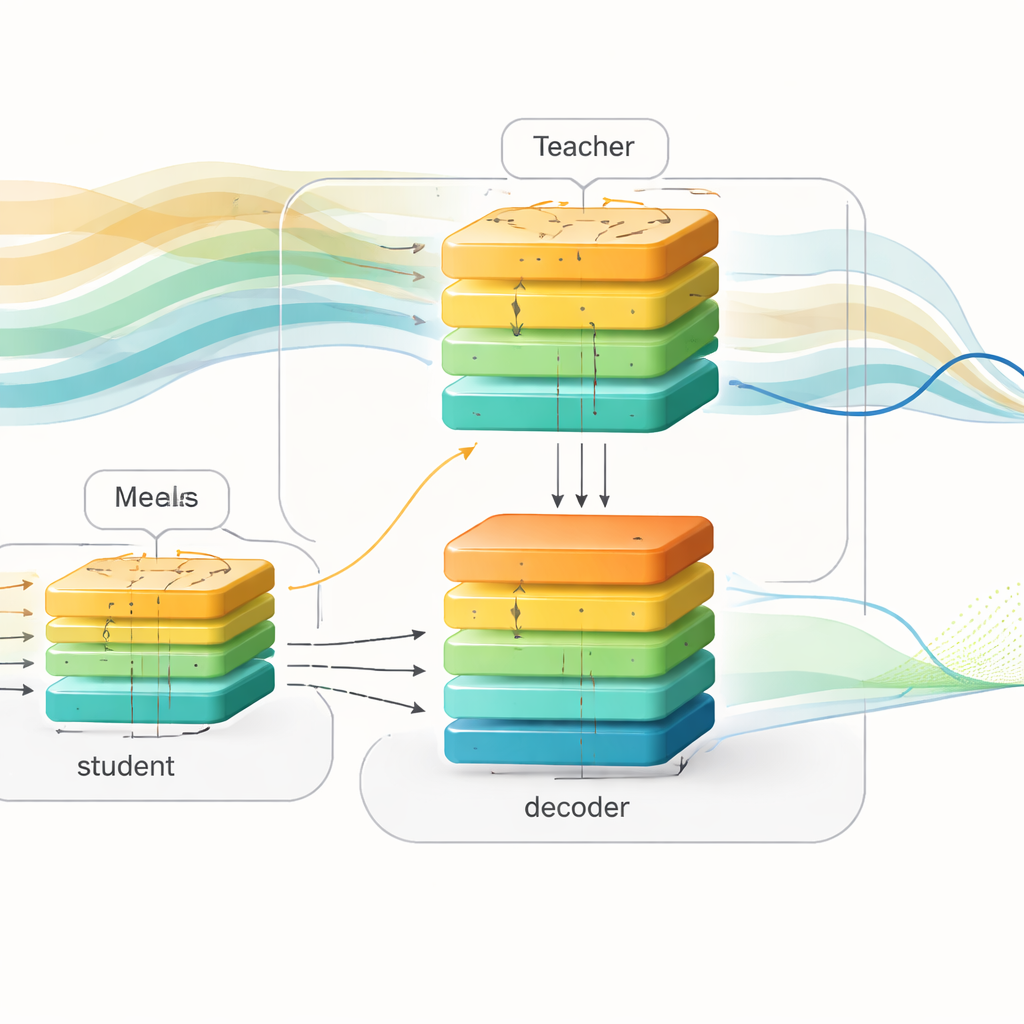
De onderzoekers introduceren een "toekomstbewust" leerkader dat training en inzet scheidt. Tijdens de training gebruiken ze rijke gegevens uit twee grote datasets van mensen met type 1 diabetes, die glucosemetingen, insulinedoseringen en maaltijdinformatie bevatten. Ze bouwen een krachtig "teacher"-model op basis van een transformer, een deep learning-architectuur die bekendstaat om het verwerken van lange reeksen. Deze teacher ziet zowel afgelopen glucosedata als aankomende maaltijden en insuline voor de komende twee uur en leert hoe die toekomstige gebeurtenissen het glucosepatroon vormen. Parallel daaraan ontwerpen ze een "student"-model met een vergelijkbare input–outputstructuur, maar de student ziet voortaan alleen historische data, net als een apparaat in de echte wereld.
Kennis overdragen van teacher naar student
Om de kloof tussen deze twee wereldbeelden te overbruggen, gebruiken de auteurs een techniek die kennisdistillatie heet. In plaats van alleen de uiteindelijke voorspellingen van de teacher na te bootsen, vragen ze de student ook de interne representatie van de teacher na te bootsen van hoe glucose naar verwachting zal evolueren. Zowel teacher als student voeren hun interne signalen in hetzelfde decoder-netwerk dat abstracte patronen omzet in toekomstige glucosecurven. Tijdens de training wordt de student op drie manieren tegelijk aangestuurd: hij moet de werkelijke toekomstige bloedsuiker voorspellen, zijn interne patronen dicht bij die van de teacher houden, en de voorspellingen van de teacher benaderen. In de loop van de tijd leert de student indirect te "denken" aan aankomende maaltijden en insuline, door waarschijnlijke toekomstige schommelingen af te leiden uit de vormen van de recente geschiedenis alleen.
Testen op gegevens uit de echte wereld
Het team evalueert hun aanpak op twee onafhankelijke datasets: OhioT1DM, dat 12 volwassenen volgt gedurende acht weken in dagelijks leven, en AZT1D, dat 25 mensen volgt die geautomatiseerde insulineafgiftesystemen gebruiken. Na zorgvuldige verwerking van ontbrekende sensormetingen vergelijken ze hun studentmodel met verschillende sterke neurale netwerk-baselines, waaronder LSTM, bidirectionele LSTM, convolutioneel–recurrente netwerken en transformermodellen die geen toekomstbewuste training gebruiken. Over voorspellingshorizons van 30 tot 120 minuten verlaagt de nieuwe methode consequent gangbare foutmaten zoals root mean squared error en mean absolute error. Klinische betrouwbaarheid wordt onderzocht via een Clarke-foutengrid, die voorspellingen beoordeelt op hoeveel schade ze in besluitvorming zouden kunnen veroorzaken; meer dan 90% van de voorspellingen van dit model valt in de zones die als veilig of acceptabel worden beschouwd voor het sturen van therapie.
Wat dit kan betekenen voor het dagelijks leven
Kort gezegd laat de studie zien dat een model laten oefenen met een glimp van de toekomst, en die ervaring vervolgens distilleren in een slankere versie die zonder toekomstkennis werkt, de nauwkeurigheid van bloedsuiker‑voorspellingen kan verbeteren—vooral 60 tot 120 minuten vooruit. Deze langere horizonvoorspellingen helpen mensen beslissen of ze nu een snack nemen om later een daling te vermijden, of een insulinedosering tijdig aanpassen om een dreigende hoge waarde te voorkomen. Hoewel het werk nog onderzoek is en uitgaat van redelijk regelmatige routines, wijst het op slimmere besluitondersteunende hulpmiddelen en gesloten-lus insulinesystemen die aankomende glucoseschommelingen beter anticiperen, zelfs wanneer de enige beschikbare informatie bestaat uit wat al gebeurd is.
Bronvermelding: Sun, X., Li, H. & Yu, X. Future-aware blood glucose forecasting using knowledge distillation with transformer-based sequence-to-sequence models. Sci Rep 16, 11404 (2026). https://doi.org/10.1038/s41598-026-41787-7
Trefwoorden: voorspelling van bloedglucose, type 1 diabetes, deep learning, transformermodelen, kennisdistillatie