Clear Sky Science · pl
Prognozowanie poziomu glukozy z uwzględnieniem przyszłości przy użyciu destylacji wiedzy z modeli sekwencja‑do‑sekwencji opartych na transformerach
Dlaczego przewidywanie poziomu cukru ma znaczenie
Dla osób żyjących z cukrzycą typu 1 poziom cukru może szybko rosnąć i spadać po posiłkach, podczas wysiłku, w reakcji na stres lub po podaniu insuliny. Możliwość zobaczenia nie tylko aktualnego poziomu glukozy, lecz także kierunku, w jakim zmierza w ciągu następnej godziny lub dwóch, może pomóc uniknąć niebezpiecznych spadków i wzrostów, odpowiednio wcześniej dostosować insulinę oraz planować codzienne aktywności z większą pewnością. Badanie opisuje nowy sposób uczenia komputerów prognozowania przyszłego poziomu glukozy poprzez „poufne” wykorzystanie informacji o nadchodzących posiłkach i insulinie podczas treningu, jednocześnie zachowując działanie w rzeczywistym świecie, gdzie przyszłość jest nieznana.
Mądrzejsze spojrzenie w przód dla opieki nad cukrzycą
Obecne ciągłe monitory glukozy dostarczają odczytów co kilka minut, a nowoczesne algorytmy już wykorzystują te dane do przewidywania krótkoterminowego. Większość istniejących narzędzi jednak patrzy wstecz: analizuje przeszłe odczyty glukozy i czasem inne sygnały, takie jak tętno czy aktywność ruchowa. Zwykle pomijają duży wpływ przyszłych zdarzeń, jak następny posiłek czy bolus insuliny, ponieważ te zdarzenia nie są wiarygodnie znane z wyprzedzeniem. W efekcie prognozy często zawodzą dokładnie wtedy, gdy poziom cukru zmienia się najszybciej — na przykład zaraz po jedzeniu lub przy korekcie wysokiego odczytu. Autorzy argumentują, że aby rzeczywiście wspierać codzienne decyzje związane z cukrzycą, prognozy muszą w jakiś sposób nauczyć się o tych przyszłych zakłóceniach, nie spodziewając się, że będą one dostępne w czasie działania.
Nauczanie z dodatkowymi wskazówkami, potem test bez nich
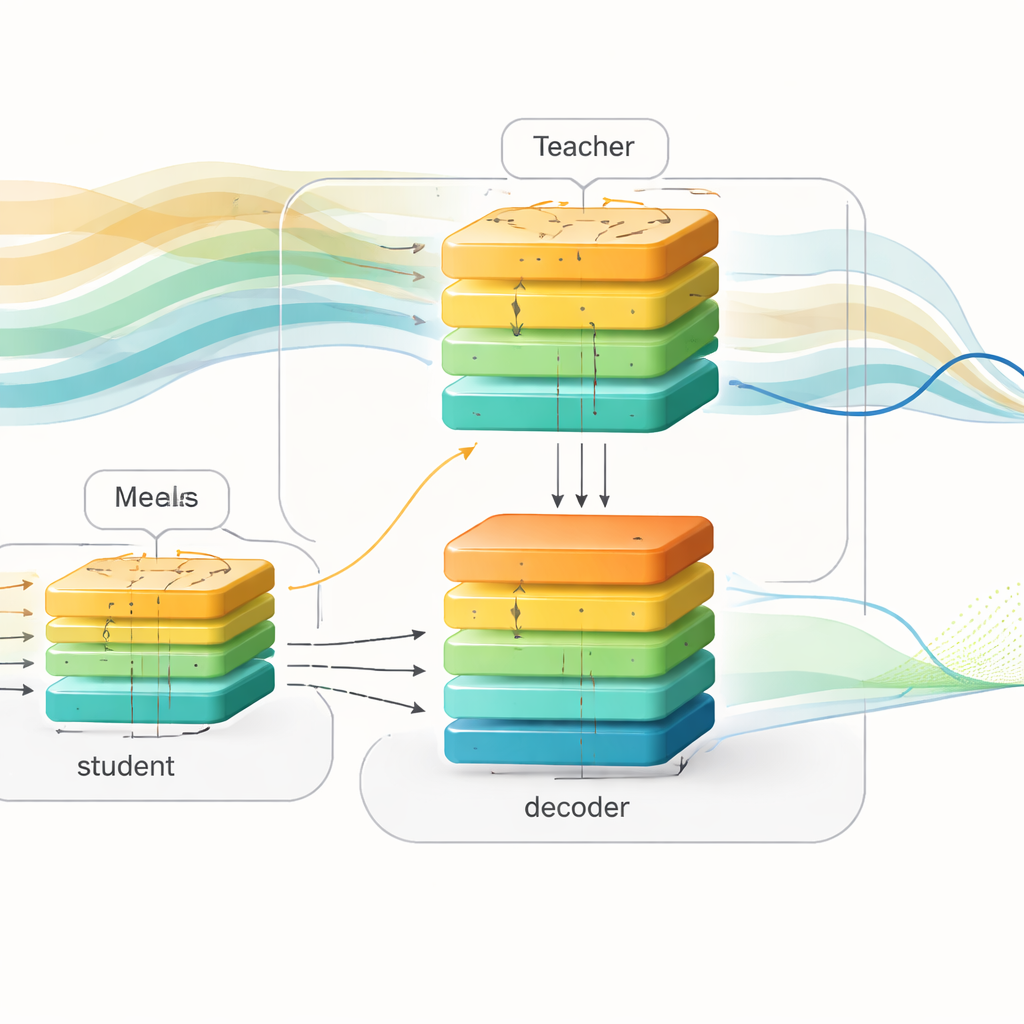
Naukowcy wprowadzają ramy uczące „świadome przyszłości”, które rozdzielają fazę treningu od fazy wdrożenia. Podczas treningu korzystają z bogatych zapisów z dwóch dużych zbiorów danych osób z cukrzycą typu 1, zawierających odczyty glukozy, dawki insuliny i informacje o posiłkach. Budują potężny model „nauczyciela” oparty na transformerze, architekturze uczenia głębokiego znanej z obsługi długich sekwencji. Ten nauczyciel widzi zarówno przeszłe dane glukozy, jak i nadchodzące posiłki i insulinę na następne dwie godziny, i uczy się, jak te przyszłe zdarzenia kształtują wzorce glikemii. Równolegle projektują model „ucznia” o podobnej strukturze wejście‑wyjście, ale uczeń widzi tylko dane z przeszłości, tak jak urządzenie działające w świecie rzeczywistym.
Przekazywanie wiedzy od nauczyciela do ucznia
Aby zniwelować różnicę między tymi dwoma spojrzeniami na świat, autorzy stosują technikę nazwaną destylacją wiedzy. Zamiast jedynie dopasowywać końcowe prognozy nauczyciela, proszą ucznia, by imitował również wewnętrzną reprezentację nauczyciela dotyczącą oczekiwanego przebiegu glukozy. Zarówno nauczyciel, jak i uczeń przekazują swoje wewnętrzne sygnały do tej samej sieci dekodera, która przekształca abstrakcyjne wzorce w przyszłe krzywe glukozy. Podczas treningu uczeń jest popychany na trzy sposoby jednocześnie: musi przewidzieć prawdziwą przyszłą glikemię, utrzymywać swoje wewnętrzne wzorce blisko wzorców nauczyciela i przybliżać prognozy nauczyciela. Z czasem uczeń uczy się „myśleć” o nadchodzących posiłkach i insulinie pośrednio, wnioskując prawdopodobne przyszłe wahania jedynie na podstawie kształtów niedawnej historii.
Testy na danych z rzeczywistej opieki diabetologicznej
Zespół ocenia swoje podejście na dwóch niezależnych zbiorach danych: OhioT1DM, który śledzi 12 dorosłych przez osiem tygodni codziennego życia, oraz AZT1D, który obejmuje 25 osób korzystających z systemów automatycznego dawkowania insuliny. Po starannym obchodzeniu się z brakującymi odczytami sensora porównują model ucznia z kilkoma silnymi sieciami neuronowymi referencyjnymi, w tym LSTM, dwukierunkowym LSTM, sieciami konwolucyjno‑rekurencyjnymi oraz modelami transformer, które nie stosują treningu świadomego przyszłości. W całym zakresie horyzontów prognozy od 30 do 120 minut nowa metoda konsekwentnie obniża typowe miary błędu, takie jak błąd średniokwadratowy pierwiastkowy i średni bezwzględny błąd. Niezawodność kliniczną badano za pomocą wykresu błędów Clarke’a, który ocenia prognozy pod kątem potencjalnej szkody w decyzjach terapeutycznych; ponad 90% prognoz tego modelu mieści się w strefach uznanych za bezpieczne lub akceptowalne do prowadzenia terapii.
Co to może oznaczać na co dzień
Mówiąc prosto, badanie pokazuje, że pozwolenie modelowi potrenować z zajrzeniem w przyszłość, a następnie zdestylowanie tego doświadczenia do lżejszej wersji działającej bez wiedzy o przyszłości, może uczynić prognozy poziomu glukozy bardziej dokładnymi — szczególnie w perspektywie 60–120 minut. To właśnie dłuższe prognozy pomagają ludziom zdecydować, czy zjeść przekąskę teraz, żeby uniknąć hipoglikemii później, lub czy w porę skorygować dawkę insuliny, by zapobiec nadchodzącemu wysokiemu poziomowi. Choć praca pozostaje badawcza i zakłada dość regularne rutyny, wskazuje drogę ku mądrzejszym narzędziom wspierającym decyzje i systemom zamkniętej pętli insulinowej, które lepiej przewidują nadchodzące wahania glikemii, nawet gdy jedynymi dostępnymi informacjami są zdarzenia, które już miały miejsce.
Cytowanie: Sun, X., Li, H. & Yu, X. Future-aware blood glucose forecasting using knowledge distillation with transformer-based sequence-to-sequence models. Sci Rep 16, 11404 (2026). https://doi.org/10.1038/s41598-026-41787-7
Słowa kluczowe: predykcja glukozy we krwi, cukrzyca typu 1, uczenie głębokie, modele transformer, destylacja wiedzy